
数据集不平衡导致使用SMOTE后出现高假阳性
数据集不平衡导致使用SMOTE后出现高假阳性
提问于 2019-05-18 12:17:44
我正在开发一个二元分类不平衡的营销数据集,该数据集有:
- 是的比率为88:12 (不-不是买的,是买的)
- ~4300次观测和30个特征(9个数字和21个分类)
我将我的数据分为列车(80%)和测试(20%)集合,然后在列车上使用standard_scalar & SMOTE。SMOTE将训练数据集与1:1的比例设为“No:Yes”。然后,我运行了一个逻辑回归分类器,如下面代码所示,在测试数据上获得了80%的召回分数,而在测试数据上只有21%。
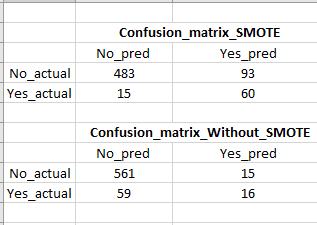
随着SMOTE召回的增加是很大的,但是假阳性率很高(请参考图像中的混淆矩阵),这是一个问题,因为我们最终会针对许多虚假(不太可能购买)客户。有没有办法在不牺牲召回/真阳性的情况下降低假阳性?
#Without SMOTE
clf_logistic_nosmote = LogisticRegression(random_state=0, solver='lbfgs').fit(X_train,y_train)
#With SMOTE (resampled train datasets)
clf_logistic = LogisticRegression(random_state=0, solver='lbfgs').fit(X_train_sc_resampled, y_train_resampled)回答 1
Stack Overflow用户
发布于 2019-11-21 18:02:37
甚至我也有过类似的问题,那里的假阳性率很高。在这种情况下,我在做了功能工程之后申请了SMOTE。
然后,在进行特征工程之前,我使用了SMOTE,并使用SMOTE生成的数据来提取特征。这样效果很好。虽然,这将是一个较慢的方法,但它对我来说是可行的。告诉我这对你有什么好处。
页面原文内容由Stack Overflow提供。腾讯云小微IT领域专用引擎提供翻译支持
原文链接:
https://stackoverflow.com/questions/56198863
复制相关文章
相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号