
神经网络训练过程的诊断
神经网络训练过程的诊断
提问于 2019-01-24 19:44:00
我正在为一个回归问题训练一个自动编码器DNN。需要关于如何改进培训过程的建议。
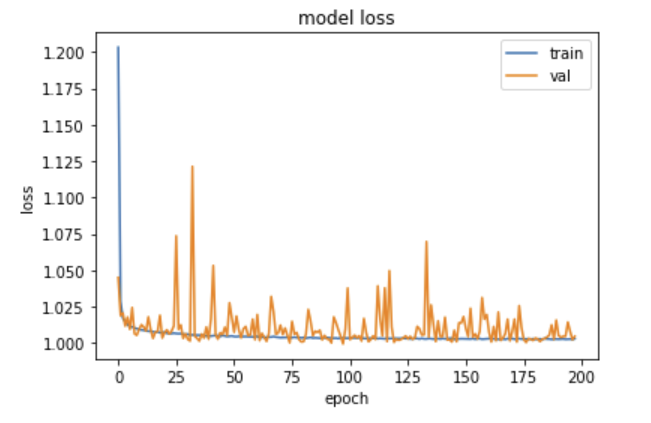
培训样本总数约为10万。我使用Keras来拟合模型,设置validation_split = 0.1。经过训练,我画了损失函数的变化,并得到了以下图片。从这里可以看出,验证损失是不稳定的,平均值非常接近训练损失。
我的问题是:在此基础上,下一步我应该努力改进培训过程吗?
编辑在1/26/2019上详细描述了网络体系结构:它有一个潜在层,由50个节点组成。输入层和输出层分别有1000个节点。隐藏层的激活为ReLU。损失函数为MSE。对于优化器,我在默认参数设置中使用Adadelta。我也试图设置lr=0.5,但得到了非常类似的结果。数据的不同特征在-10到10之间缩放,平均值为0。
回答 1
Stack Overflow用户
发布于 2019-01-26 02:08:28
通过观察所提供的图形,网络无法逼近建立输入和输出之间关系的函数。
如果你的特征太多样化。其中一个是大的,另一个是很小的值,那么你应该对特征向量进行规范化。您可以阅读更多的这里。
为了获得更好的培训和测试结果,您可以遵循以下建议,
- 使用一个小的网络。一个只有一个隐藏层的网络就足够了。
- 在输入层和隐藏层中执行激活。输出层必须具有线性函数。使用ReLU激活函数。
- 喜欢0.001这样的小学分。使用RMSProp优化器。它可以很好地解决大多数回归问题。
- 如果您没有使用均方误差函数,请使用它。
- 尝试缓慢和稳定的学习,而不是快速学习。
页面原文内容由Stack Overflow提供。腾讯云小微IT领域专用引擎提供翻译支持
原文链接:
https://stackoverflow.com/questions/54354225
复制相关文章
相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号