
Keras在检查形状兼容性时更改输入形状的维数。
我有下面的keras模型,它接受非顺序和顺序的输入
# Model parameters
units = 100
batch_size = 64
epochs = 1
encoder_inputs = Input(shape=(None, 1), name='encoder')
# Allows handling of variable length inputs by applying a binary mask to the specified mask_value.
masker = Masking(mask_value=sys.float_info.max)
masker(encoder_inputs)
nonseq_inputs = np.array([
tensors['product_popularity'],
tensors['quarter_autocorr'],
tensors['year_autocorr']
]).T
nonseq_dim = nonseq_inputs.shape[1]
nonseq_input = Input(shape=(nonseq_dim,), name='nonsequential_input')
hidden_dense = Dense(units)(nonseq_input)
zeros = Lambda(lambda x: K.zeros_like(x), output_shape=lambda s: s)(hidden_dense)
encoder = LSTM(units, return_state=True)
encoder_outputs, state_h, state_c = encoder(encoder_inputs, initial_state=[hidden_dense, zeros])
# Keep encoder states for decoder, discard outputs
encoder_states = [state_h, state_c]
# Set up the decoder taking the encoder_states to be the initial state vector of the decoder.
decoder_inputs = Input(shape=(None, 1), name='decoder')
# Full output sequences and internal states are returned. Returned states are used in prediction / inference
masker(decoder_inputs)
decoder = LSTM(units, return_sequences=True, return_state=True)
decoder_outputs, _, _ = decoder(decoder_inputs, initial_state=encoder_states)
# Gives continuous output at each time step
decoder_dense = Dense(1)
decoder_outputs = decoder_dense(decoder_outputs)
# create model that takes encoder_input_data and decoder_input_data and creates decoder_target_data
model = Model([nonseq_input, encoder_inputs, decoder_inputs], decoder_outputs)
model.summary()
plot_model(model, 'model.png')
# Get encoder inputs and standardise
encoder_input = get_time_block_series(series_array, date_to_index, train_encoding_start, train_encoding_end)
encoder_input, encoder_series_mean = centre_data(encoder_input)
# Get targets for the decoder
decoder_targets = get_time_block_series(series_array, date_to_index, train_pred_start, train_pred_end)
decoder_targets, _ = centre_data(decoder_targets, means=encoder_series_mean)
# Lag the target series to apply teacher forcing to mitigate error propagtion
decoder_input = np.zeros_like(decoder_targets)
decoder_input[:, 1:, 0] = decoder_targets[:, :-1, 0]
decoder_input[:, 0, 0] = encoder_input[:, -1, 0]
model.compile(Adam(), loss='mean_absolute_error')
history = model.fit(
[nonseq_inputs, encoder_input, decoder_input],
decoder_targets,
batch_size=batch_size,
epochs=epochs,
validation_split=0.2,
shuffle=True
)
# Build a model to predict with
encoder_model = Model([nonseq_input, encoder_inputs], encoder_states)
decoder_state_input_h = Input(shape=(units,))
decoder_state_input_c = Input(shape=(units,))
decoder_initial_state = [decoder_state_input_h, decoder_state_input_c]
decoder_outputs, state_h, state_c = decoder(decoder_inputs, initial_state=decoder_initial_state)
decoder_states = [state_h, state_c]
decoder_model = Model([decoder_inputs] + decoder_initial_state, [decoder_outputs] + decoder_states)
# Predict
encoder_input_data = get_time_block_series(series_array, date_to_index, val_encoding_start, val_encoding_end)
encoder_input_data, encoder_series_mean = centre_data(encoder_input_data)
decoder_target_data = get_time_block_series(series_array, date_to_index, val_pred_start, val_pred_end)
decoder_target_data, _ = centre_data(decoder_target_data, encoder_series_mean)
series, y, yhat = predict(
encoder_model,
decoder_model,
encoder_input_data,
decoder_targets,
encoder_series_mean,
horizon,
sp,
nonseq_inputs
)
def predict(encoder_model, decoder_model, encoder_input, decoder_targets, means, horizon, sample_index, nonseq_inputs):
encode_series = encoder_input[sample_index:sample_index + 1]
nonseq_input = nonseq_inputs[sample_index, :]
yhat = decode_sequence(encoder_model, decoder_model, encode_series, horizon, nonseq_input)
encode_series = encode_series.flatten()
yhat = yhat.flatten()
y = decoder_targets[sample_index, :, :1].flatten()
encode_series, yhat, y = invert_transform(encode_series, yhat, y, means[sample_index])
return encode_series, y, yhat
def decode_sequence(encoder_model, decoder_model, input_sequence, output_length, nonseq_input=None):
# Encode input as state vectors
state_values = encoder_model.predict([nonseq_input, input_sequence], batch_size=1)
# Generate empty target sequence of length 1
target_sequence = np.zeros((1, 1, 1))
# Populate the first target sequence with the end of the encoding series
target_sequence[0, 0, 0] = input_sequence[0, -1, 0]
# Sampling loop for a batch of sequences - we will fill decoded_sequence with predictions
# (to simplify we assume a batch_size of 1)
decoded_sequence = np.zeros((1, output_length, 1))
for i in range(output_length):
output, h, c = decoder_model.predict([target_sequence] + state_values)
decoded_sequence[0, i, 0] = output[0, 0, 0]
# Update the target sequence (of length 1)
target_sequence = np.zeros((1, 1, 1))
target_sequence[0, 0, 0] = output[0, 0, 0]
# Update states
state_values = [h, c]
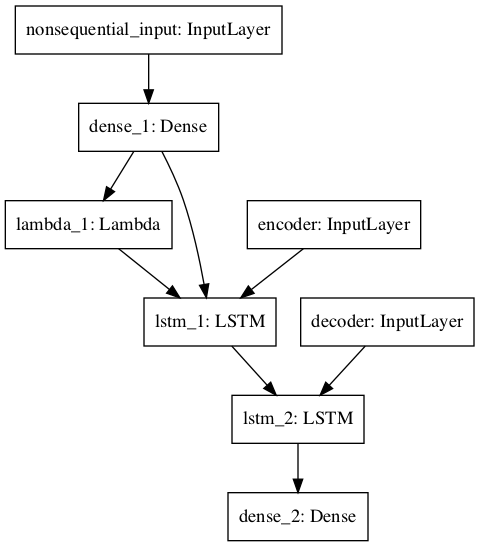
return decoded_sequence下面是模型的图像:
当我在一组非顺序输入和一组顺序输入中调用预测函数时,我得到以下错误:
ValueError:在检查输入时出错:期望nonsequential_input具有形状(3,但得到了形状(1,))
我可以确认,我确实按照模型输入列表中的要求传递了一个形状数组(3,)(我打印出来是为了检查它是否正常)。当我调试代码时,我一直到standardize_input_data模块中的training_utils.py模块,一直到形状检查兼容性:
# Check shapes compatibility.
if shapes:
for i in range(len(names)):
if shapes[i] is not None and not K.is_tensor(data[i]):
data_shape = data[i].shape
shape = shapes[i]
if data[i].ndim != len(shape):
raise ValueError(
'Error when checking ' + exception_prefix +
': expected ' + names[i] + ' to have ' +
str(len(shape)) + ' dimensions, but got array '
'with shape ' + str(data_shape))
if not check_batch_axis:
data_shape = data_shape[1:]
shape = shape[1:]
for dim, ref_dim in zip(data_shape, shape):
if ref_dim != dim and ref_dim:
raise ValueError(
'Error when checking ' + exception_prefix +
': expected ' + names[i] + ' to have shape ' +
str(shape) + ' but got array with shape ' +
str(data_shape))当我遍历这段代码时,直到行“如果不是check_batch_axis”,变量data_shape具有正确的形状维数(即3)。然而,这个函数总是用check_batch_axis=False调用的,这意味着if语句总是会传递。在代码的这一部分中,正确设置的data_shape会被覆盖,并被错误地设置为1。
if not check_batch_axis:
data_shape = data_shape[1:]
shape = shape[1:]我不知道为什么会这样,或者我做了什么不对的事情。我所能确认的是,我传递给列表中的预测函数的numpy数组确实具有正确的形状,但是它们在前面的代码中会被更改。有人知道我为什么或做错了什么吗?
该模型基于以下博客文章中的代码:https://blog.keras.io/a-ten-minute-introduction-to-sequence-to-sequence-learning-in-keras.html
编辑:下面要求的详细信息
传递给fit函数的数组的形状:
数组在具有下列形状的列表中传递:
(478、3)、(478、240)、(478、26)。
作为背景,我有478个独特的序列;其中有三个时不变特征,作为第一个输入,第二个输入包含实际序列,最后一个元素是译码器的输入,用于预测26个点。我已经更新了上面的代码以显示适合调用的行。
编辑2:添加一行以打印解码函数中的形状输出:
def decode_sequence(encoder_model, decoder_model, input_sequence, output_length, nonseq_input=None):
# Encode input as state vectors
print('nonseq_input.shape: {}'.format(nonseq_input.shape))
print('input_sequence.shape: {}'.format(input_sequence.shape))
state_values = encoder_model.predict([nonseq_input, input_sequence], batch_size=1)(函数的其余部分与以前相同,只在print语句中添加)。产出如下:
Train on 382 samples, validate on 96 samples
Epoch 1/1
2019-01-13 08:37:08.112955: I tensorflow/core/platform/cpu_feature_guard.cc:141] Your CPU supports instructions that this TensorFlow binary was not compiled to use: AVX2 FMA
64/382 [====>.........................] - ETA: 9s - loss: 2.7368
128/382 [=========>....................] - ETA: 4s - loss: 2.6203
192/382 [==============>...............] - ETA: 2s - loss: 2.4305
256/382 [===================>..........] - ETA: 1s - loss: 2.2558
320/382 [========================>.....] - ETA: 0s - loss: 2.2033
382/382 [==============================] - 4s 10ms/step - loss: 2.2386 - val_loss: 3.1458
nonseq_input.shape: (3,)
input_sequence.shape: (1, 240, 1)异常与问题的第一部分所表示的相同。
回答 1
Stack Overflow用户
发布于 2019-01-13 11:03:15
问题是,输入层需要一批数据,即一个二维数组,其中第一个轴是批处理维,第二个轴是数据维,但是作为一维数组传递给单个样本。虽然nonseq_inputs是二维的,并且具有形状(477, 3),因为sp是一个整数,但是新的数组nonseq_input = nonseq_inputs[sample_index, :]有形状(3,),并且是一维的。相反,你应该使用
nonseq_input = nonseq_inputs[[sample_index], :]来维护一个2D数组。
https://stackoverflow.com/questions/54161393
复制相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号