
R: Regex_ Join /Fuzzy_Join -不同语序中的联接不精确字符串
R: Regex_ Join /Fuzzy_Join -不同语序中的联接不精确字符串
提问于 2019-01-07 18:05:50
df1
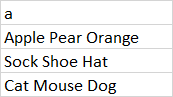
df2
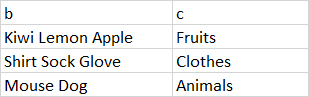
df3
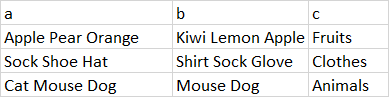
library(dplyr)
library(fuzzyjoin)
df1 <- tibble(a =c("Apple Pear Orange", "Sock Shoe Hat", "Cat Mouse Dog"))
df2 <- tibble(b =c("Kiwi Lemon Apple", "Shirt Sock Glove", "Mouse Dog"),
c = c("Fruit", "Clothes", "Animals"))
# Appends 'Animals'
df3 <- regex_left_join(df1,df2, c("a" = "b"))
# Appends Nothing
df3 <- stringdist_left_join(df1, df2, by = c("a" = "b"), max_dist = 3, method = "lcs")我想使用字符串“Apple”、“Sock”和“df1 Dog”将df1的第c列附加到后面。
我试着用regex_join和fuzzyjoin做这件事,但是字符串的顺序似乎很重要,似乎找不到绕过它的方法。
回答 1
Stack Overflow用户
回答已采纳
发布于 2019-01-07 18:31:15
regex_left_join可以工作,但它不只是寻找任何相似之处。就像描述中说的,
通过正则表达式列连接另一个表中的字符串列的表
所以,我们需要提供一个正则表达式。如果df2$b包含单独的感兴趣的单词,我们可以这样做
(df2$regex <- gsub(" ", "|", df2$b))
# [1] "Kiwi|Lemon|Apple" "Shirt|Sock|Glove" "Mouse|Dog" 然后
regex_left_join(df1, df2, by = c(a = "regex"))[-ncol(df1) - ncol(df2)]
# A tibble: 3 x 3
# a b c
# <chr> <chr> <chr>
# 1 Apple Pear Orange Kiwi Lemon Apple Fruit
# 2 Sock Shoe Hat Shirt Sock Glove Clothes
# 3 Cat Mouse Dog Mouse Dog Animals其中,-ncol(df1) - ncol(df2)简单地删除了包含regex模式的最后一列。
页面原文内容由Stack Overflow提供。腾讯云小微IT领域专用引擎提供翻译支持
原文链接:
https://stackoverflow.com/questions/54079535
复制相关文章
相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号