
在训练和测试模型时,度量值是相等的。
在训练和测试模型时,度量值是相等的。
提问于 2018-12-17 05:17:02
我正在使用带有TensorFlow后端的Keras开发一个使用python的神经网络模型。数据集包含两个序列,结果可以是1或0,数据集中的正负比为1: 9。模型将这两个序列作为输入输出概率。首先,我的模型有一个密集层,有一个隐藏单元和乙状结肠激活函数作为输出,然后我将模型的最后一层改为一个有两个隐藏单元和softmax激活函数的稠密层,并使用Keras to_categorical函数改变了数据集的结果。这些变化后,模型的准确性、精确性、召回性、F1、AUC等指标都是相等的,具有很高的和错误的价值。下面是我用于这些度量的实现
def recall(y_true, y_pred):
true_positives = K.sum(K.round(K.clip(y_true * y_pred, 0, 1)))
possible_positives = K.sum(K.round(K.clip(y_true, 0, 1)))
recall = true_positives / (possible_positives + K.epsilon())
return recall
def precision(y_true, y_pred):
true_positives = K.sum(K.round(K.clip(y_true * y_pred, 0, 1)))
predicted_positives = K.sum(K.round(K.clip(y_pred, 0, 1)))
precision = true_positives / (predicted_positives + K.epsilon())
return precision
def f1(y_true, y_pred):
precisionValue = precision(y_true, y_pred)
recallValue = recall(y_true, y_pred)
return 2*((precisionValue*recallValue)/(precisionValue+recallValue+K.epsilon()))
def auc(y_true, y_pred):
auc = tf.metrics.auc(y_true, y_pred)[1]
K.get_session().run(tf.local_variables_initializer())
return auc这是训练的结果
Epoch 1/5
4026/4026 [==============================] - 17s 4ms/step - loss: 1.4511 - acc: 0.9044 - f1: 0.9044 - auc: 0.8999 - precision: 0.9044 - recall: 0.9044
Epoch 2/5
4026/4026 [==============================] - 15s 4ms/step - loss: 1.4573 - acc: 0.9091 - f1: 0.9091 - auc: 0.9087 - precision: 0.9091 - recall: 0.9091
Epoch 3/5
4026/4026 [==============================] - 15s 4ms/step - loss: 1.4573 - acc: 0.9091 - f1: 0.9091 - auc: 0.9083 - precision: 0.9091 - recall: 0.9091
Epoch 4/5
4026/4026 [==============================] - 15s 4ms/step - loss: 1.4573 - acc: 0.9091 - f1: 0.9091 - auc: 0.9090 - precision: 0.9091 - recall: 0.9091
Epoch 5/5
4026/4026 [==============================] - 15s 4ms/step - loss: 1.4573 - acc: 0.9091 - f1: 0.9091 - auc: 0.9085 - precision: 0.9091 - recall: 0.9091在此之后,我使用predict测试了我的模型,并使用sklearn的precision_recall_fscore_support函数计算了度量,并再次得到了相同的结果。度量都是相等的,并且具有较高的值(0.93),根据我生成的混淆矩阵,这是错误的。
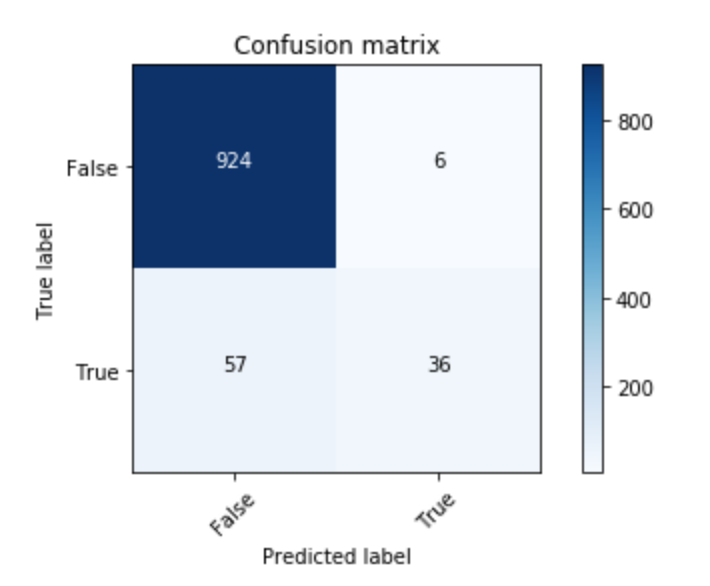
我做错了什么?
回答 1
Stack Overflow用户
回答已采纳
发布于 2018-12-17 07:30:22
由于Keras2.0的精确性,F1被删除了,因为这些度量应该是全局计算的,但是它们是批量计算的,您的代码类似于keras1.x中使用的代码,这可能就是问题所在。
尝试使用包度量标准
import keras
import keras_metrics
model = models.Sequential()
model.add(keras.layers.Dense(1, activation="sigmoid", input_dim=2))
model.add(keras.layers.Dense(1, activation="softmax"))
model.compile(optimizer="sgd",
loss="binary_crossentropy",
metrics=[keras_metrics.precision(), keras_metrics.recall()])页面原文内容由Stack Overflow提供。腾讯云小微IT领域专用引擎提供翻译支持
原文链接:
https://stackoverflow.com/questions/53809325
复制相关文章
相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号