
等价于predict_proba的DecisionTreeRegressor
等价于predict_proba的DecisionTreeRegressor
提问于 2018-12-03 02:55:20
回答 2
Stack Overflow用户
回答已采纳
发布于 2018-12-03 20:07:29
该函数对来自赫尔潘德的回答的代码进行了调整,以提供每个结果的概率:
from sklearn.tree import DecisionTreeRegressor
import pandas as pd
def decision_tree_regressor_predict_proba(X_train, y_train, X_test, **kwargs):
"""Trains DecisionTreeRegressor model and predicts probabilities of each y.
Args:
X_train: Training features.
y_train: Training labels.
X_test: New data to predict on.
**kwargs: Other arguments passed to DecisionTreeRegressor.
Returns:
DataFrame with columns for record_id (row of X_test), y
(predicted value), and prob (of that y value).
The sum of prob equals 1 for each record_id.
"""
# Train model.
m = DecisionTreeRegressor(**kwargs).fit(X_train, y_train)
# Get y values corresponding to each node.
node_ys = pd.DataFrame({'node_id': m.apply(X_train), 'y': y_train})
# Calculate probability as 1 / number of y values per node.
node_ys['prob'] = 1 / node_ys.groupby(node_ys.node_id).transform('count')
# Aggregate per node-y, in case of multiple training records with the same y.
node_ys_dedup = node_ys.groupby(['node_id', 'y']).prob.sum().to_frame()\
.reset_index()
# Extract predicted leaf node for each new observation.
leaf = pd.DataFrame(m.decision_path(X_test).toarray()).apply(
lambda x:x.to_numpy().nonzero()[0].max(), axis=1).to_frame(
name='node_id')
leaf['record_id'] = leaf.index
# Merge with y values and drop node_id.
return leaf.merge(node_ys_dedup, on='node_id').drop(
'node_id', axis=1).sort_values(['record_id', 'y'])示例(参见这个笔记本):
from sklearn.datasets import load_boston
from sklearn.model_selection import train_test_split
X, y = load_boston(True)
X_train, X_test, y_train, y_test = train_test_split(X, y, random_state=0)
# Works better with min_samples_leaf > 1.
res = decision_tree_regressor_predict_proba(X_train, y_train, X_test,
random_state=0, min_samples_leaf=5)
res[res.record_id == 2]
# record_id y prob
# 25 2 20.6 0.166667
# 26 2 22.3 0.166667
# 27 2 22.7 0.166667
# 28 2 23.8 0.333333
# 29 2 25.0 0.166667Stack Overflow用户
发布于 2018-12-03 11:24:17
您可以将数据从树结构中提取出来:
import sklearn
import numpy as np
import graphviz
from sklearn.tree import DecisionTreeRegressor, DecisionTreeClassifier
from sklearn.datasets import make_regression
# Generate a simple dataset
X, y = make_regression(n_features=2, n_informative=2, random_state=0)
clf = DecisionTreeRegressor(random_state=0, max_depth=2)
clf.fit(X, y)
# Visualize the tree
graphviz.Source(sklearn.tree.export_graphviz(clf)).view()
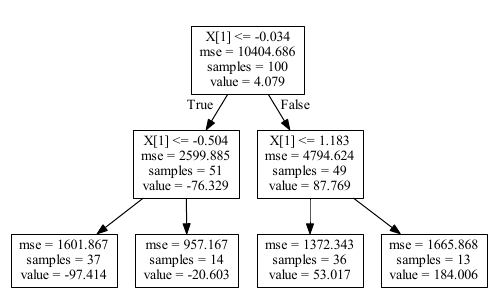
>>> clf.predict(X[:5])
0 184.005667
1 53.017289
2 184.005667
3 -20.603498
4 -97.414461如果调用clf.apply(X),您将得到一个实例所属的节点id:
array([6, 5, 6, 3, 2, 5, 5, 3, 6, ... 5, 5, 6, 3, 2, 2, 5, 2, 2], dtype=int64)将其与目标变量合并:
df = pd.DataFrame(np.vstack([y, clf.apply(X)]), index=['y','node_id']).T
y node_id
0 190.370562 6.0
1 13.339570 5.0
2 141.772669 6.0
3 -3.069627 3.0
4 -26.062465 2.0
5 54.922541 5.0
6 25.952881 5.0
...现在,如果您在node_id上做了一个groupby,后面跟着clf.predict(X),您将得到与clf.predict(X)相同的值
>>> df.groupby('node_id').mean()
y
node_id
2.0 -97.414461
3.0 -20.603498
5.0 53.017289
6.0 184.005667在我们的树上,叶子的value是:
>>> clf.tree_.value[6]
array([[184.00566679]])要获得新数据集的节点ids,需要调用
clf.decision_path(X[:5]).toarray()
它显示了这样一个数组
array([[1, 0, 0, 0, 1, 0, 1],
[1, 0, 0, 0, 1, 1, 0],
[1, 0, 0, 0, 1, 0, 1],
[1, 1, 0, 1, 0, 0, 0],
[1, 1, 1, 0, 0, 0, 0]], dtype=int64)需要得到最后一个非零元素(即叶)。
>>> pd.DataFrame(clf.decision_path(X[:5]).toarray()).apply(lambda x:x.nonzero()[0].max(), axis=1)
0 6
1 5
2 6
3 3
4 2
dtype: int64所以,如果你不想预测中值,而是想要预测中值,你就会做
>>> pd.DataFrame(clf.decision_path(X[:5]).toarray()).apply(lambda x: x.nonzero()[0].max(
), axis=1).to_frame(name='node_id').join(df.groupby('node_id').median(), on='node_id')['y']
0 181.381106
1 54.053170
2 181.381106
3 -28.591188
4 -93.891889页面原文内容由Stack Overflow提供。腾讯云小微IT领域专用引擎提供翻译支持
原文链接:
https://stackoverflow.com/questions/53586860
复制相关文章
相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号