
在对抗性训练中,应该再使用Dropout口罩吗?
我正在使用来自解释和利用对抗性实例的FGSM方法实现对抗性培训,使用自定义的损失函数:
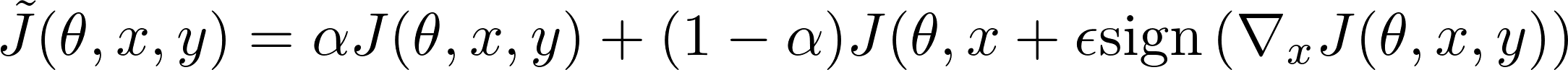
它在tf.keras中使用自定义丢失函数实现,在概念上如下所示:
model = Sequential([
...
])
def loss(labels, logits):
# Compute the cross-entropy on the legitimate examples
cross_ent = tf.losses.softmax_cross_entropy(labels, logits)
# Compute the adversarial examples
gradients, = tf.gradients(cross_ent, model.input)
inputs_adv = tf.stop_gradient(model.input + 0.3 * tf.sign(gradients))
# Compute the cross-entropy on the adversarial examples
logits_adv = model(inputs_adv)
cross_ent_adv = tf.losses.softmax_cross_entropy(labels, logits_adv)
return 0.5 * cross_ent + 0.5 * cross_ent_adv
model.compile(optimizer='adam', loss=loss)
model.fit(x_train, y_train, ...)这对于一个简单的卷积神经网络来说是很好的。
在logits_adv = model(inputs_adv)调用期间,将第二次调用该模型。这意味着,它将使用不同的辍学面具,而不是在最初的前馈传递与model.inputs。然而,inputs_adv是用tf.gradients(cross_ent, model.input)创建的,也就是从原始的前馈传递中提取出来的掩码。这可能是有问题的,因为允许模型使用新的辍学口罩可能会削弱对抗性批次的效果。
由于在Keras中实现下拉掩码的重用非常麻烦,所以我对重用掩码的实际效果很感兴趣。会有什么不同吗?在合法的和敌对的例子上测试的准确性?
回答 1
Stack Overflow用户
发布于 2018-11-20 15:31:39
在对抗性训练阶段,我试着重复使用辍学口罩,在MNIST上用一个简单的CNN进行前传。我选择了与此cleverhans教程中使用的相同的网络体系结构,在softmax层之前有一个额外的退出层。
这就是结果(red =重用退出掩码,blue =朴素实现):
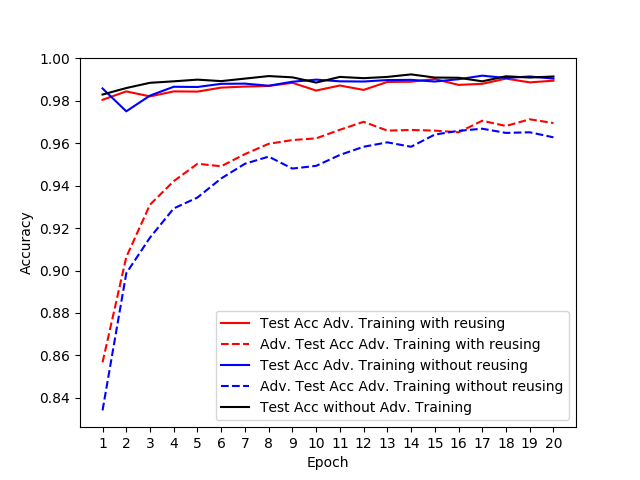
实线表示合法测试实例的准确性。虚线表示在测试集上生成的对抗性示例的准确性。
在总结,如果您只使用对抗性训练作为一个正则化,以提高测试的准确性本身,重复使用辍学面具可能是不值得的努力。对于对抗攻击的鲁棒性,可能会产生很小的影响。但是,您需要在其他数据集、体系结构、随机种子等上进行进一步的实验,才能做出更有信心的声明。
为了保持上述图形的可读性,我省略了不经过对抗性训练的模型的对抗性测试示例的准确性。数值约为10%。
你可以在这个要旨中找到这个实验的代码。使用TensorFlow的急切模式,实现存储和重用下拉掩码非常简单。
https://stackoverflow.com/questions/53395329
复制相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号