
分解大量小矩阵时本征partial_lu_inplace的瓶颈
我需要分解最大可变大小为20x20的1e05小矩阵。使用HpcToolkit对矩阵分解进行分析表明,代码中的热点在Eigen::internal::partial_lu_inplace中。
我检查了内矩阵分解的特征证明,我知道对于大型矩阵来说,使用内部分解、重用内存和具有更好的缓存效率是非常重要的。
我目前正在像这样计算分解:
// Factorize the matrix.
matrixFactorization_ = A_.partialPivLu(); 使用HpcToolkit进行分析显示,内部因式分解是热点:
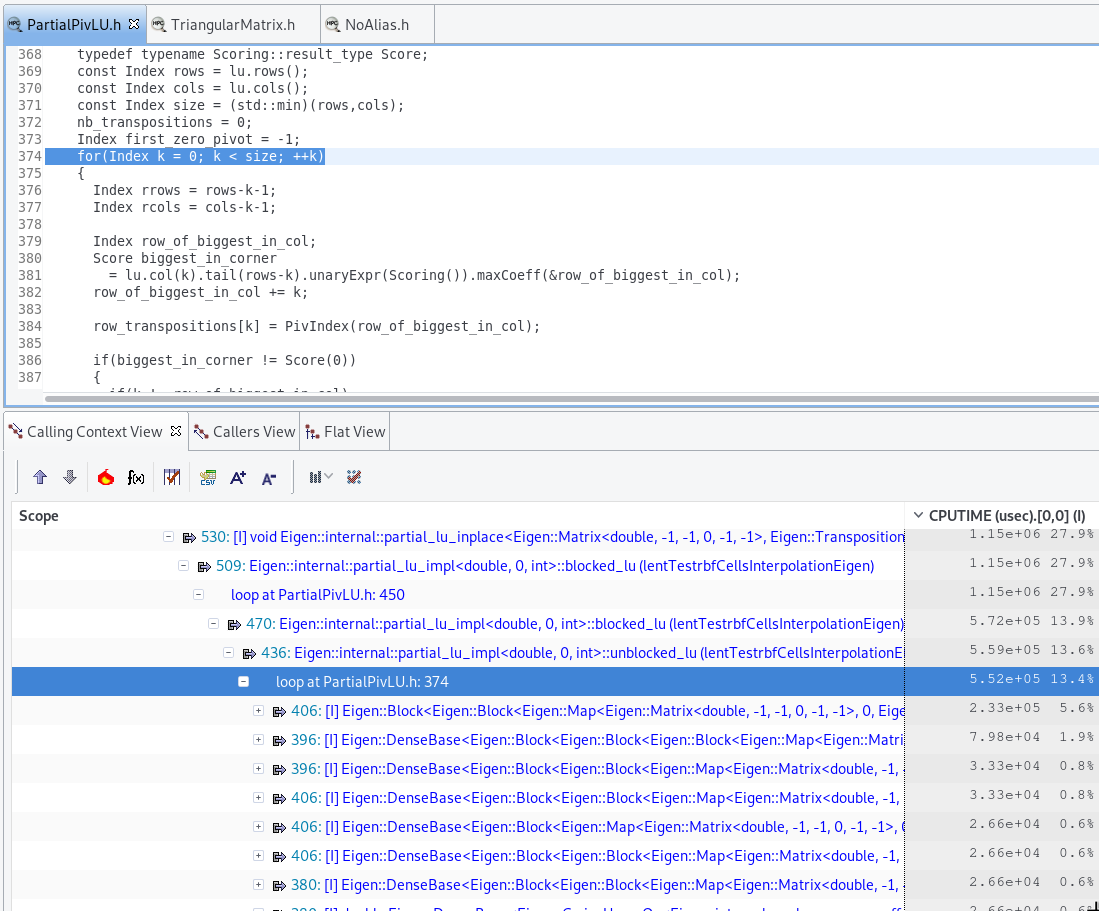
是否有可能禁用内部分解并测试我正在处理的小型矩阵的代码是否会更快?
注意:如果您查看映像上列中的CPU时间,您将注意到运行时以秒为单位:我不是在微秒优化之后,计算总共需要4秒。
编辑:HPCToolkit统计地描述了在完全优化模式下的代码, -O3,但是使用了将度量映射到源编码-g3所需的信息。
回答 1
Stack Overflow用户
发布于 2018-11-14 13:53:54
如果分析器向您提供了如此详细的信息,那么您就忘记启用编译器的优化(例如,-O3 -march=native -DNDEBUG,或使用VS的“释放”模式+ /arch:AVX )。有了艾根,这将产生巨大的变化。
然后,可以使用以下方法保存动态内存分配:
typedef Matrix<double,Dynamic,Dynamic,ColMajor,20,20> MatMax20;
MatMax20 A_;
PartialPivLU<MatMax20> matrixFactorization_;因此,矩阵A_和PartialPivLU的所有内部都将被静态地分配。
要更新现有的事实,更好地编写:
matrixFactorization_.compute(A_);https://stackoverflow.com/questions/53298403
复制相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号