
双数据源LSTM神经网络
双数据源LSTM神经网络
提问于 2018-10-27 17:28:27
我有以下配置:一个lstm网络,接收大小为2的n克文本。下面是一个简单的原理图:
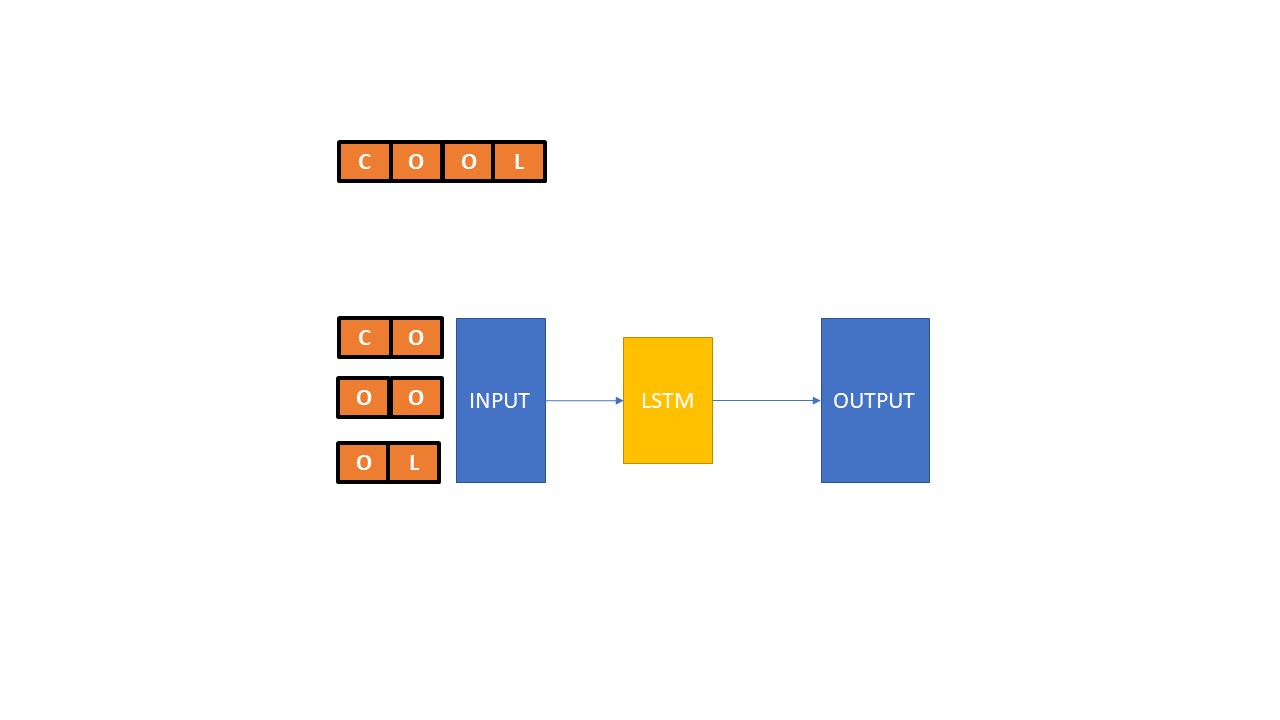
经过一些测试后,我注意到在某些类中,当我使用大小为3的ngram时,我的准确性有了很大提高。现在,我想训练一个同时具有两个ngram大小的新的LSTM神经网络,如下面的原理图:
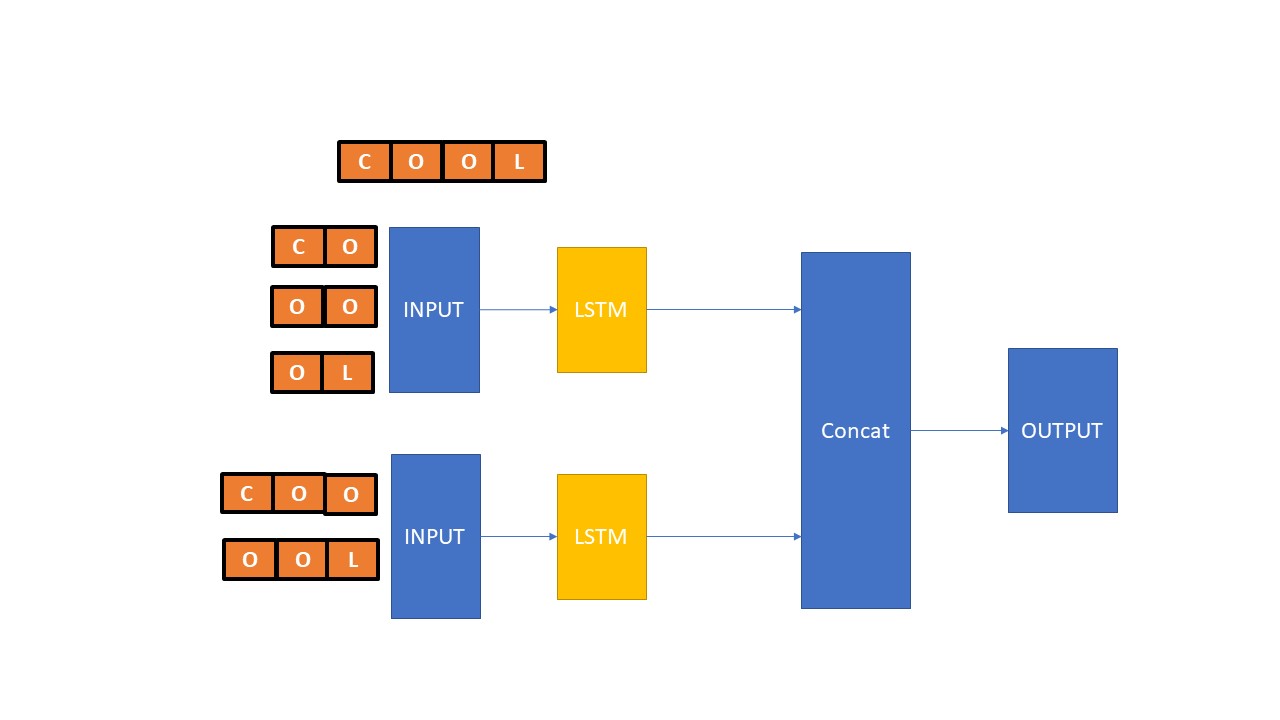
我如何提供数据并建立这个模型,使用keras来执行这个任务?
回答 1
Stack Overflow用户
回答已采纳
发布于 2018-10-29 08:48:41
我想你已经有了把单词分解成n克的功能,就像你已经有了2克和3克的模型一样?为此,我只为一个工作示例构造了一个单词“酷”的示例。我不得不在我的例子中使用嵌入,因为带有26^3=17576节点的LSTM层对我的计算机来说有点太难处理了。我想你在你的3克密码里也这么做了?
以下是一个完整的工作示例:
from tensorflow.keras.layers import Input, Embedding, LSTM, Dense, concatenate
from tensorflow.keras.models import Model
import numpy as np
# c->2 o->14 o->14 l->11
np_2_gram_in = np.array([[26*2+14,26*14+14,26*14+11]])#co,oo,ol
np_3_gram_in = np.array([[26**2*2+26*14+14,26**2*14+26*14+26*11]])#coo,ool
np_output = np.array([[1]])
output_shape=1
lstm_2_gram_embedding = 128
lstm_3_gram_embedding = 192
inputs_2_gram = Input(shape=(None,))
em_input_2_gram = Embedding(output_dim=lstm_2_gram_embedding, input_dim=26**2)(inputs_2_gram)
lstm_2_gram = LSTM(lstm_2_gram_embedding)(em_input_2_gram)
inputs_3_gram = Input(shape=(None,))
em_input_3_gram = Embedding(output_dim=lstm_3_gram_embedding, input_dim=26**3)(inputs_3_gram)
lstm_3_gram = LSTM(lstm_3_gram_embedding)(em_input_3_gram)
concat = concatenate([lstm_2_gram, lstm_3_gram])
output = Dense(output_shape,activation='sigmoid')(concat)
model = Model(inputs=[inputs_2_gram, inputs_3_gram], outputs=[output])
model.compile(optimizer='adam', loss='binary_crossentropy')
model.fit([np_2_gram_in, np_3_gram_in], [np_output], epochs=5)
model.predict([np_2_gram_in,np_3_gram_in])页面原文内容由Stack Overflow提供。腾讯云小微IT领域专用引擎提供翻译支持
原文链接:
https://stackoverflow.com/questions/53024517
复制相关文章
相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号