
简单二项GLM的rstan MCMC低效采样
我正在尝试使用rethinking包(借鉴rstan MCMC)来安装二项式GLM。
该模型符合要求,但抽样效率很低,Rhat表明出了问题。我不明白为什么会有这个合适的问题。
以下是数据:
d <- read_csv("https://gist.githubusercontent.com/sebastiansauer/a2519de39da49d70c4a9e7a10191cb97/raw/election.csv")
d <- as.data.frame(dummy)这就是模式:
m1_stan <- map2stan(
alist(
afd_votes ~ dbinom(votes_total, p),
logit(p) <- beta0 + beta1*foreigner_n,
beta0 ~ dnorm(0, 10),
beta1 ~ dnorm(0, 10)
),
data = d,
WAIC = FALSE,
iter = 1000)Fit诊断( went,有效样本的数量)表明出了问题:
Mean StdDev lower 0.89 upper 0.89 n_eff Rhat
beta0 -3.75 0 -3.75 -3.75 3 2.21
beta1 0.00 0 0.00 0.00 10 1.25追踪图中没有显示“肥毛毛虫”:
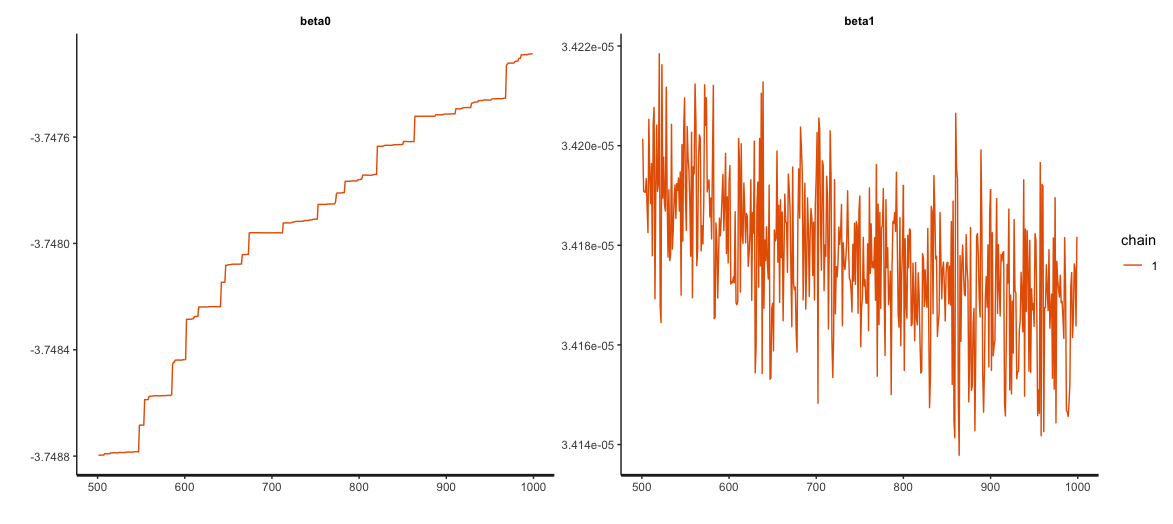
stan输出建议增加两个参数,adapt_delta和max_treedepth,我这样做了。这在一定程度上改善了抽样过程:
Mean StdDev lower 0.89 upper 0.89 n_eff Rhat
beta0 18.1 0.09 18.11 18.16 28 1.06
beta1 0.0 0.00 0.00 0.00 28 1.06但正如追踪图所显示的,仍然有一些问题:
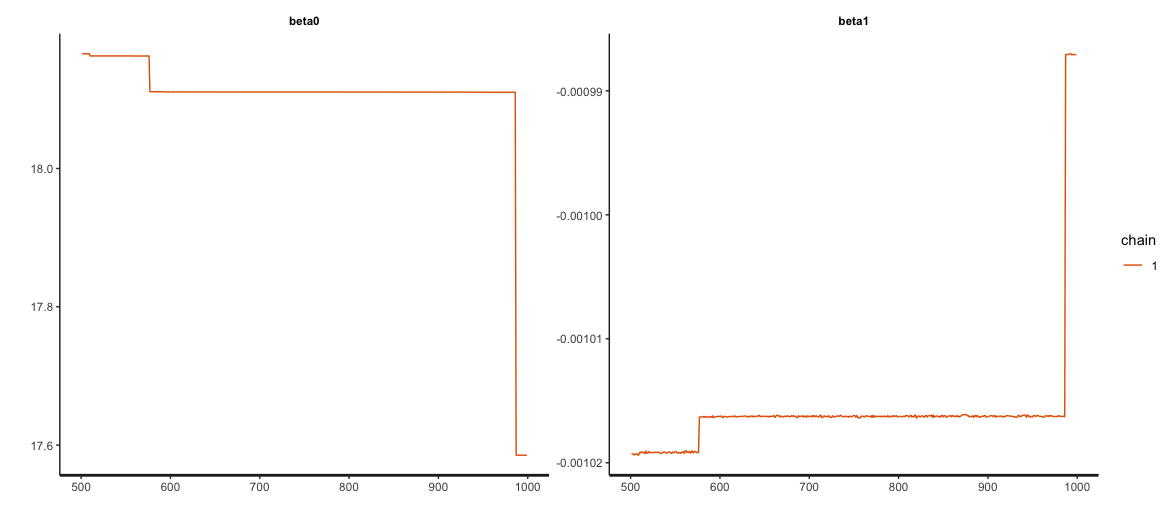
两人的情节看起来也很奇怪:
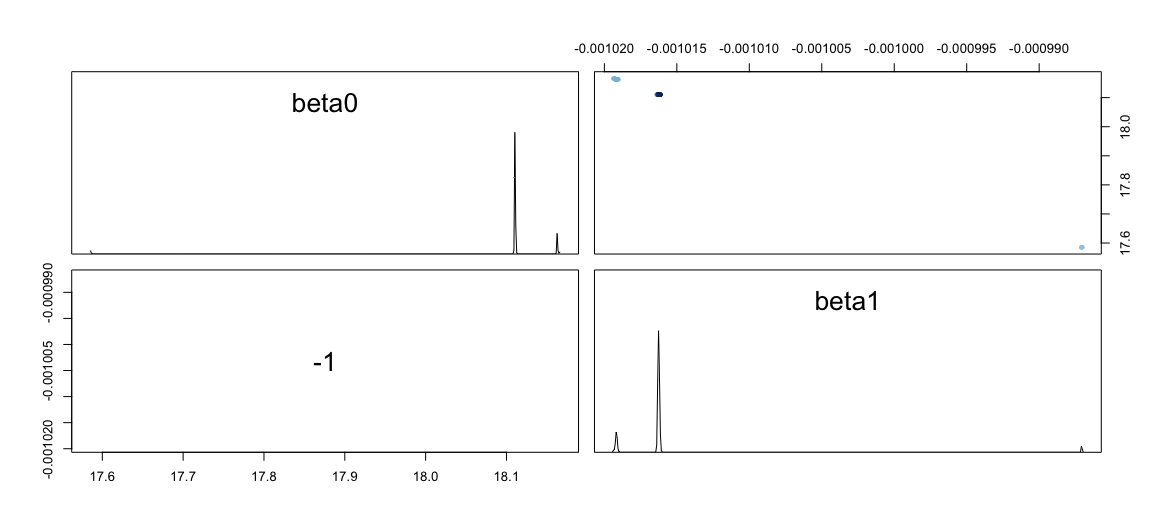
我试过的是:
- 我居中/z-标准化了预测器(产生了这个错误:“sampler$call_sampler中的错误(args_list[i]):初始化失败”)。
- 我尝试了一个正常的模型(但它是计数数据)
- 我检查过没有失踪(没有)
- 我将迭代次数增加到4000次,没有改进。
- 我增加了前科的sd (模型需要很长的时间才能适应)
但到目前为止没有什么帮助。是什么原因造成了这种无益的合身?我能试试什么?
每一个数字中的大数目会不会是个问题?
mean(d_short$afd_votes)
[1] 19655.83数据摘录:
head(d)
afd_votes votes_total foreigner_n
1 11647 170396 16100
2 9023 138075 12600
3 11176 130875 11000
4 11578 156268 9299
5 10390 150173 25099
6 11161 130514 13000会议信息:
sessionInfo()
R version 3.5.0 (2018-04-23)
Platform: x86_64-apple-darwin15.6.0 (64-bit)
Running under: macOS High Sierra 10.13.6
Matrix products: default
BLAS: /System/Library/Frameworks/Accelerate.framework/Versions/A/Frameworks/vecLib.framework/Versions/A/libBLAS.dylib
LAPACK: /Library/Frameworks/R.framework/Versions/3.5/Resources/lib/libRlapack.dylib
locale:
[1] en_US.UTF-8/en_US.UTF-8/en_US.UTF-8/C/en_US.UTF-8/en_US.UTF-8
attached base packages:
[1] parallel stats graphics grDevices utils datasets methods base
other attached packages:
[1] viridis_0.5.1 viridisLite_0.3.0 sjmisc_2.7.3 pradadata_0.1.3 rethinking_1.59 rstan_2.17.3 StanHeaders_2.17.2 forcats_0.3.0 stringr_1.3.1
[10] dplyr_0.7.6 purrr_0.2.5 readr_1.1.1 tidyr_0.8.1 tibble_1.4.2 ggplot2_3.0.0 tidyverse_1.2.1
loaded via a namespace (and not attached):
[1] httr_1.3.1 jsonlite_1.5 modelr_0.1.2 assertthat_0.2.0 stats4_3.5.0 cellranger_1.1.0 yaml_2.1.19 pillar_1.3.0 backports_1.1.2
[10] lattice_0.20-35 glue_1.3.0 digest_0.6.15 rvest_0.3.2 snakecase_0.9.1 colorspace_1.3-2 htmltools_0.3.6 plyr_1.8.4 pkgconfig_2.0.1
[19] broom_0.5.0 haven_1.1.2 bookdown_0.7 mvtnorm_1.0-8 scales_0.5.0 stringdist_0.9.5.1 sjlabelled_1.0.12 withr_2.1.2 RcppTOML_0.1.3
[28] lazyeval_0.2.1 cli_1.0.0 magrittr_1.5 crayon_1.3.4 readxl_1.1.0 evaluate_0.11 nlme_3.1-137 MASS_7.3-50 xml2_1.2.0
[37] blogdown_0.8 tools_3.5.0 loo_2.0.0 data.table_1.11.4 hms_0.4.2 matrixStats_0.54.0 munsell_0.5.0 prediction_0.3.6 bindrcpp_0.2.2
[46] compiler_3.5.0 rlang_0.2.1 grid_3.5.0 rstudioapi_0.7 labeling_0.3 rmarkdown_1.10 gtable_0.2.0 codetools_0.2-15 inline_0.3.15
[55] curl_3.2 R6_2.2.2 gridExtra_2.3 lubridate_1.7.4 knitr_1.20 bindr_0.1.1 rprojroot_1.3-2 KernSmooth_2.23-15 stringi_1.2.4
[64] Rcpp_0.12.18 tidyselect_0.2.4 xfun_0.3 coda_0.19-1 回答 1
Stack Overflow用户
发布于 2018-09-01 16:29:32
STAN在单位尺度、不相关参数方面做得更好。来自STAN手册§28.4模型条件和曲率:
理想情况下,所有参数都应编程,使其具有单位尺度,从而减少后验相关;这些性质共同意味着,Stan算法的最佳性能不需要旋转或缩放。对于哈密顿蒙特卡罗,这意味着单位质量矩阵,这不需要适应,因为它是在那里的算法初始化。黎曼哈密顿蒙特卡罗在每一步都会执行这个条件,但是这种条件在计算上非常昂贵。
在您的示例中,beta1与没有单位规模的foreigner_n相关联,因此与beta0相比是不平衡的。另外,由于foreigner_n不是中心,所以在采样过程中,两个β都改变了p的位置,因此产生了后验相关性。
标准化产生了一个更易于处理的模型,变换foreigner_n的中心和单位尺度使模型能够快速收敛并产生高效率的样本大小。我还认为,这种形式的betas更易于解释,因为beta0只关注p的位置,而beta1只关注foreigner_n中的变化如何解释afd_votes/total_votes中的变化。
library(readr)
library(rethinking)
d <- read_csv("https://gist.githubusercontent.com/sebastiansauer/a2519de39da49d70c4a9e7a10191cb97/raw/election.csv")
d <- as.data.frame(d)
d$foreigner_z <- scale(d$foreigner_n)
m1 <- alist(
afd_votes ~ dbinom(votes_total, p),
logit(p) <- beta0 + beta1*foreigner_z,
c(beta0, beta1) ~ dnorm(0, 1)
)
m1_stan <- map2stan(m1, data = d, WAIC = FALSE,
iter = 10000, chains = 4, cores = 4)检查样本,我们有
> summary(m1_stan)
Inference for Stan model: afd_votes ~ dbinom(votes_total, p).
4 chains, each with iter=10000; warmup=5000; thin=1;
post-warmup draws per chain=5000, total post-warmup draws=20000.
mean se_mean sd 2.5% 25% 50% 75% 97.5% n_eff Rhat
beta0 -1.95 0.00 0.00 -1.95 -1.95 -1.95 -1.95 -1.95 16352 1
beta1 -0.24 0.00 0.00 -0.24 -0.24 -0.24 -0.24 -0.24 13456 1
dev 861952.93 0.02 1.97 861950.98 861951.50 861952.32 861953.73 861958.26 9348 1
lp__ -17523871.11 0.01 0.99 -17523873.77 -17523871.51 -17523870.80 -17523870.39 -17523870.13 9348 1
Samples were drawn using NUTS(diag_e) at Sat Sep 1 11:48:55 2018.
For each parameter, n_eff is a crude measure of effective sample size,
and Rhat is the potential scale reduction factor on split chains (at
convergence, Rhat=1).看看这对图,我们看到β之间的相关性降低到0.15:
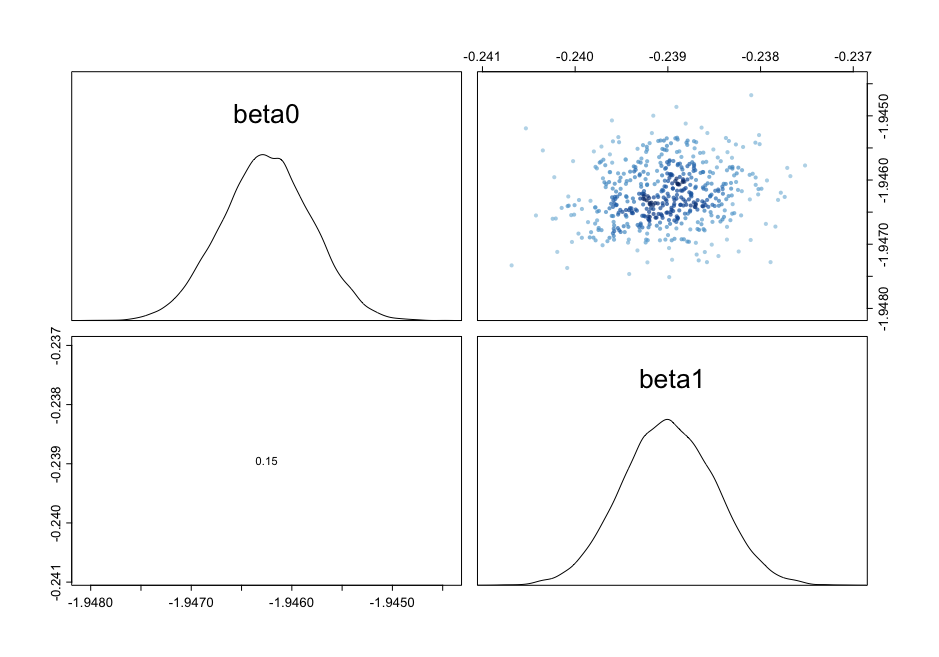
附加分析
我最初的直觉是,未输入的foreigner_n是主要的问题。同时,我有点困惑,因为STAN使用的是HMC/坚果,据我所知,HMC/坚果对于相关的潜在变量来说应该是相当稳健的。然而,我在STAN手册中注意到由于数值不稳定而产生的具有尺度不变性的实际问题的评论,这也是commented on by Michael Betancourt in a CrossValidated answer (尽管这是一个相当老的文章)。所以,我想测试一下,在改进取样过程中,中心化还是定标是最有效的。
单对中心
中心化仍然会导致相当差的性能。注意,有效样本大小实际上是每个链的一个有效样本。
library(readr)
library(rethinking)
d <- read_csv("https://gist.githubusercontent.com/sebastiansauer/a2519de39da49d70c4a9e7a10191cb97/raw/election.csv")
d <- as.data.frame(d)
d$foreigner_c <- d$foreigner_n - mean(d$foreigner_n)
m2 <- alist(
afd_votes ~ dbinom(votes_total, p),
logit(p) <- beta0 + beta1*foreigner_c,
c(beta0, beta1) ~ dnorm(0, 1)
)
m2_stan <- map2stan(m2, data = d, WAIC = FALSE,
iter = 10000, chains = 4, cores = 4)产额
Inference for Stan model: afd_votes ~ dbinom(votes_total, p).
4 chains, each with iter=10000; warmup=5000; thin=1;
post-warmup draws per chain=5000, total post-warmup draws=20000.
mean se_mean sd 2.5% 25% 50% 75% 97.5% n_eff Rhat
beta0 -0.64 0.4 0.75 -1.95 -1.29 -0.54 0.2 0.42 4 2.34
beta1 0.00 0.0 0.00 0.00 0.00 0.00 0.0 0.00 4 2.35
dev 18311608.99 8859262.1 17270228.21 861951.86 3379501.84 14661443.24 37563992.4 46468786.08 4 1.75
lp__ -26248697.70 4429630.9 8635113.76 -40327285.85 -35874888.93 -24423614.49 -18782644.5 -17523870.54 4 1.75
Samples were drawn using NUTS(diag_e) at Sun Sep 2 18:59:52 2018.
For each parameter, n_eff is a crude measure of effective sample size,
and Rhat is the potential scale reduction factor on split chains (at
convergence, Rhat=1).而且似乎仍然有一个有问题的成对情节:
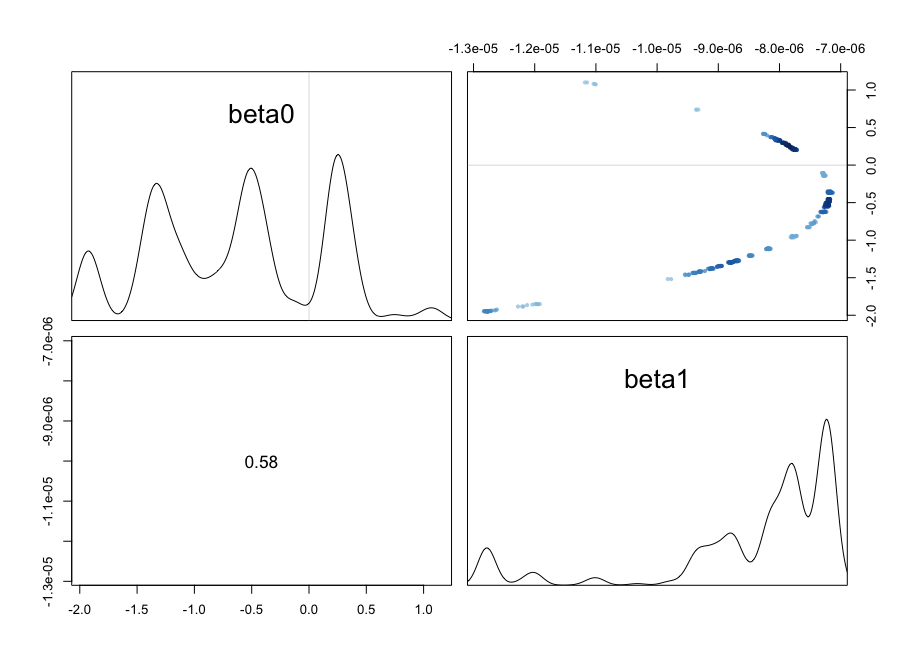
单尺度
缩放极大地改善了采样!即使结果的后验仍有相当高的相关性,有效样本大小仍在可接受的范围内,尽管远远低于完全标准化的范围。
library(readr)
library(rethinking)
d <- read_csv("https://gist.githubusercontent.com/sebastiansauer/a2519de39da49d70c4a9e7a10191cb97/raw/election.csv")
d <- as.data.frame(d)
d$foreigner_s <- d$foreigner_n / sd(d$foreigner_n)
m3 <- alist(
afd_votes ~ dbinom(votes_total, p),
logit(p) <- beta0 + beta1*foreigner_s,
c(beta0, beta1) ~ dnorm(0, 1)
)
m3_stan <- map2stan(m2, data = d, WAIC = FALSE,
iter = 10000, chains = 4, cores = 4)屈服
Inference for Stan model: afd_votes ~ dbinom(votes_total, p).
4 chains, each with iter=10000; warmup=5000; thin=1;
post-warmup draws per chain=5000, total post-warmup draws=20000.
mean se_mean sd 2.5% 25% 50% 75% 97.5% n_eff Rhat
beta0 -1.58 0.00 0.00 -1.58 -1.58 -1.58 -1.58 -1.57 5147 1
beta1 -0.24 0.00 0.00 -0.24 -0.24 -0.24 -0.24 -0.24 5615 1
dev 861952.93 0.03 2.01 861950.98 861951.50 861952.31 861953.69 861958.31 5593 1
lp__ -17523870.45 0.01 1.00 -17523873.15 -17523870.83 -17523870.14 -17523869.74 -17523869.48 5591 1
Samples were drawn using NUTS(diag_e) at Sun Sep 2 19:02:00 2018.
For each parameter, n_eff is a crude measure of effective sample size,
and Rhat is the potential scale reduction factor on split chains (at
convergence, Rhat=1).成对图表明,仍然存在显著的相关性:
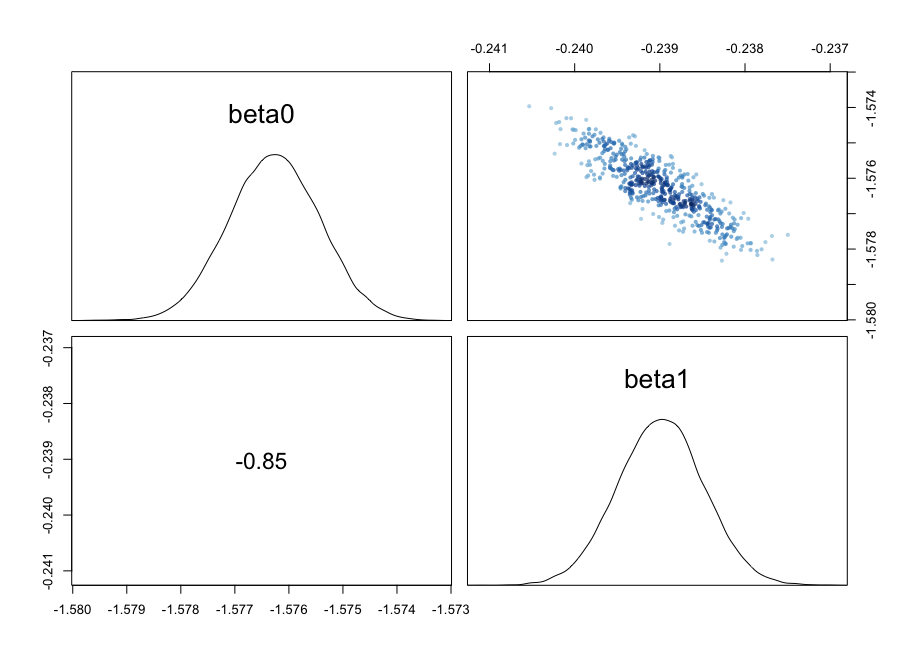
因此,尽管去相关变量确实改善了抽样,但消除规模不平衡在这个模型中是最重要的。
https://stackoverflow.com/questions/52110132
复制相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号