
用python进行非线性回归--有什么简单的方法可以更好地拟合这些数据?
我有一些我想要拟合的数据,所以我可以对给定温度的物理参数的值做一些估计。
我使用numpy.polyfit作为二次模型,但是拟合并不像我希望的那样好,而且我没有太多的回归经验。
我已经包含了散点图和numpy:S与温度;蓝点为实验数据,黑线为模型。提供的模型
{kind=link}
X轴是温度(以C为单位),y轴是参数,我们称之为S,这是实验数据,但在理论上,S应该随着温度的升高而趋于0,随着温度的降低而达到1。
我的问题是:如何才能更好地拟合这些数据?我应该使用什么样的库,什么样的函数可以比多项式更好地近似这个数据,等等?
如果有帮助的话,我可以提供代码,多项式系数等。
这是我的数据的Dropbox链接。 (为了避免混淆有些重要的注意事项,虽然它不会改变实际的回归,但是这个数据集中的温度列是Tc,其中Tc是过渡温度(40C)。我通过计算40 -x将熊猫转换成T。
回答 7
Stack Overflow用户
发布于 2018-08-22 21:51:34
此示例代码使用具有两个形状参数(a和b )和偏移项(不影响曲率)的方程。方程为"y = 1.0 / (1.0 +exp(-a(x-b))+偏移量“,参数为a= 2.1540318329369712E-01,b= -6.6744890642157646E+00,偏移量= -3.5241299859669645E-01,R-平方为0.988,均方根为0.0085。
该示例包含使用Python代码进行拟合和绘图的发布数据,以及使用scipy.optimize.differential_evolution遗传算法进行的自动初始参数估计。差异进化的实现使用拉丁超立方体算法来确保对参数空间的彻底搜索,这需要搜索的范围--在这个示例代码中,这些边界是基于最大和最小数据值的。
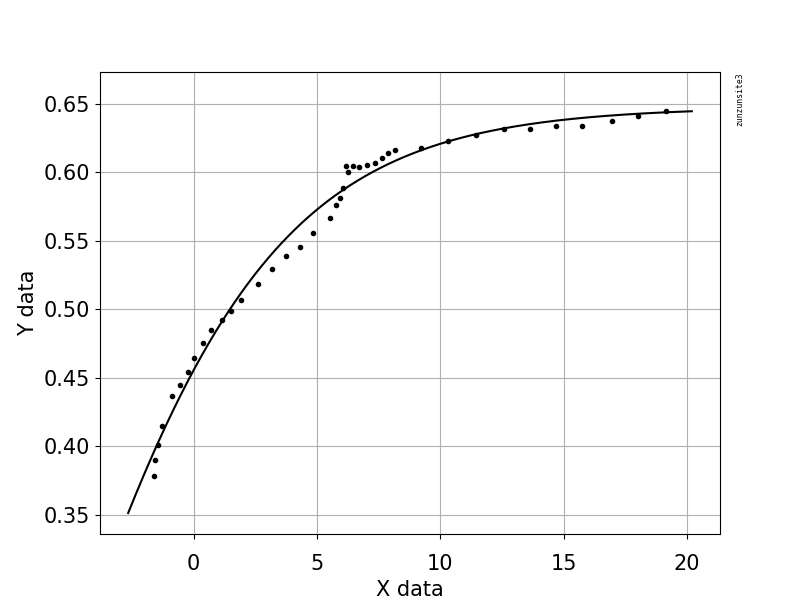
import numpy, scipy, matplotlib
import matplotlib.pyplot as plt
from scipy.optimize import curve_fit
from scipy.optimize import differential_evolution
import warnings
xData = numpy.array([19.1647, 18.0189, 16.9550, 15.7683, 14.7044, 13.6269, 12.6040, 11.4309, 10.2987, 9.23465, 8.18440, 7.89789, 7.62498, 7.36571, 7.01106, 6.71094, 6.46548, 6.27436, 6.16543, 6.05569, 5.91904, 5.78247, 5.53661, 4.85425, 4.29468, 3.74888, 3.16206, 2.58882, 1.93371, 1.52426, 1.14211, 0.719035, 0.377708, 0.0226971, -0.223181, -0.537231, -0.878491, -1.27484, -1.45266, -1.57583, -1.61717])
yData = numpy.array([0.644557, 0.641059, 0.637555, 0.634059, 0.634135, 0.631825, 0.631899, 0.627209, 0.622516, 0.617818, 0.616103, 0.613736, 0.610175, 0.606613, 0.605445, 0.603676, 0.604887, 0.600127, 0.604909, 0.588207, 0.581056, 0.576292, 0.566761, 0.555472, 0.545367, 0.538842, 0.529336, 0.518635, 0.506747, 0.499018, 0.491885, 0.484754, 0.475230, 0.464514, 0.454387, 0.444861, 0.437128, 0.415076, 0.401363, 0.390034, 0.378698])
def func(x, a, b, Offset): # Sigmoid A With Offset from zunzun.com
return 1.0 / (1.0 + numpy.exp(-a * (x-b))) + Offset
# function for genetic algorithm to minimize (sum of squared error)
def sumOfSquaredError(parameterTuple):
warnings.filterwarnings("ignore") # do not print warnings by genetic algorithm
val = func(xData, *parameterTuple)
return numpy.sum((yData - val) ** 2.0)
def generate_Initial_Parameters():
# min and max used for bounds
maxX = max(xData)
minX = min(xData)
maxY = max(yData)
minY = min(yData)
parameterBounds = []
parameterBounds.append([minX, maxX]) # search bounds for a
parameterBounds.append([minX, maxX]) # search bounds for b
parameterBounds.append([0.0, maxY]) # search bounds for Offset
# "seed" the numpy random number generator for repeatable results
result = differential_evolution(sumOfSquaredError, parameterBounds, seed=3)
return result.x
# generate initial parameter values
geneticParameters = generate_Initial_Parameters()
# curve fit the test data
fittedParameters, pcov = curve_fit(func, xData, yData, geneticParameters)
print('Parameters', fittedParameters)
modelPredictions = func(xData, *fittedParameters)
absError = modelPredictions - yData
SE = numpy.square(absError) # squared errors
MSE = numpy.mean(SE) # mean squared errors
RMSE = numpy.sqrt(MSE) # Root Mean Squared Error, RMSE
Rsquared = 1.0 - (numpy.var(absError) / numpy.var(yData))
print('RMSE:', RMSE)
print('R-squared:', Rsquared)
##########################################################
# graphics output section
def ModelAndScatterPlot(graphWidth, graphHeight):
f = plt.figure(figsize=(graphWidth/100.0, graphHeight/100.0), dpi=100)
axes = f.add_subplot(111)
# first the raw data as a scatter plot
axes.plot(xData, yData, 'D')
# create data for the fitted equation plot
xModel = numpy.linspace(min(xData), max(xData))
yModel = func(xModel, *fittedParameters)
# now the model as a line plot
axes.plot(xModel, yModel)
axes.set_xlabel('X Data') # X axis data label
axes.set_ylabel('Y Data') # Y axis data label
plt.show()
plt.close('all') # clean up after using pyplot
graphWidth = 800
graphHeight = 600
ModelAndScatterPlot(graphWidth, graphHeight)Stack Overflow用户
发布于 2018-08-22 19:51:43
我建议你去看看scipy。它们有一个非线性优化器来拟合任意函数的数据。请参阅scipy.optimize.curve_fit 这里的文档。请注意,功能越复杂,需要的时间就越长。
Stack Overflow用户
发布于 2018-08-22 20:05:28
对于非线性回归问题,可以尝试sklearn中的SVR()、KNeighborsRegressor()或DecisionTreeRegression(),并比较测试集上的模型性能。
https://stackoverflow.com/questions/51972637
复制相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号