
CPU端的性能瓶颈
我正在研究语义分割架构。我需要加速训练,但不知道该往哪里看。
一般信息
- 形状图像(512,512,3)
- 4 GeForce GTX 1080 11 GB GPU内存可用
- 1 CPU英特尔(R) Xeon(R) CPU E5-2637 v4 #3.50GHz可用
- 足够的RAM
- 我用Keras
- 我使用光数据预处理(主要是裁剪,数据增强不多)。
对于数据加载,我尝试过不同的方法,但每次瓶颈似乎都是CPU而不是GPU。我运行nvidia-smi和htop来查看利用率。
到目前为止,我已经尝试过:
- Keras +带有8个工作人员和1个GPU
model.fit_generator(generator=training_generator,use_multiprocessing=True, workers=8)的自定义DataGenerator - 从原始图像加载数据的Keras + tf.data.dataset (
model.fit(training_dataset.make_one_shot_iterator(),...)) 我尝试了两种预取方式:dataset = dataset.prefetch(tf.contrib.data.AUTOTUNE)dataset = dataset.apply(tf.contrib.data.prefetch_to_device('/gpu:0')) - 从tf.data.dataset加载数据的Keras + tf.Records =>下一个选项是这个选项。
调查结果
- 使用多个CPU (使用Keras非常容易)会减缓训练速度,因为开销计算占用CPU。
- 令人惊讶的是,普通的DataGenerator方法(没有tf.data.dataset)现在是最快的。
- GPU的利用率在很短的时间内每一种方法都会提高到100%。但有时也是0%。
我觉得现在,我的处理链是这样的:
磁盘上的数据-> CPU加载数据-> CPU进行数据预处理-> CPU将数据移动到GPU -> GPU执行训练步骤。
因此,加快培训的唯一方法是预先进行所有预处理,并将文件保存到磁盘(随着数据的增加将是巨大的)。然后使用tf.Records有效地加载文件。
你有其他的想法来提高训练的速度吗?
更新
我用两种型号测试了我的管道。
简单模型

复模型
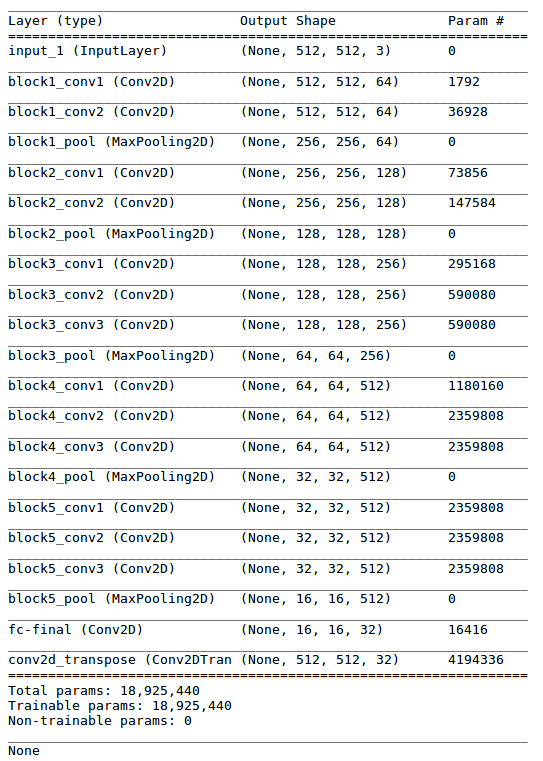
业绩结果
我为三个时代训练了两个模型,每个步骤140步(批次大小= 3)。以下是结果。
- 原始图像数据=> Keras.DataGenerator 简单型号:126 s 复杂模型:154 s
- 原始图像数据=> tf.data.datasets 简单型号:208 s 复杂模型:215 s
DataGenerator
辅助函数
def load_image(self,path):
image = cv2.cvtColor(cv2.imread(path,-1), cv2.COLOR_BGR2RGB)
return image主体部分
#Collect a batch of images on the CPU step by step (probably the bottlebeck of the whole computation)
for i in range(len(image_filenames_tmp)):
#print(image_filenames_tmp[i])
#print(label_filenames_tmp[i])
input_image = self.load_image(image_filenames_tmp[i])[: self.shape[0], : self.shape[1]]
output_image = self.load_image(label_filenames_tmp[i])[: self.shape[0], : self.shape[1]]
# Prep the data. Make sure the labels are in one-hot format
input_image = np.float32(input_image) / 255.0
output_image = np.float32(self.one_hot_it(label=output_image, label_values=label_values))
input_image_batch.append(np.expand_dims(input_image, axis=0))
output_image_batch.append(np.expand_dims(output_image, axis=0))
input_image_batch = np.squeeze(np.stack(input_image_batch, axis=1))
output_image_batch = np.squeeze(np.stack(output_image_batch, axis=1))
return input_image_batch, output_image_batchtf.data.dataset
辅助函数
def preprocess_fn(train_image_filename, train_label_filename):
'''A transformation function to preprocess raw data
into trainable input. '''
x = tf.image.decode_png(tf.read_file(train_image_filename))
x = tf.image.convert_image_dtype(x,tf.float32,saturate=False,name=None)
x = tf.image.resize_image_with_crop_or_pad(x,512,512)
y = tf.image.decode_png(tf.read_file(train_label_filename))
y = tf.image.resize_image_with_crop_or_pad(y,512,512)
class_names, label_values = get_label_info(csv_path)
semantic_map = []
for colour in label_values:
class_map = tf.reduce_all(tf.equal(y, colour), axis=-1)
semantic_map.append(class_map)
semantic_map = tf.stack(semantic_map, axis=-1)
# NOTE cast to tf.float32 because most neural networks operate in float32.
semantic_map = tf.cast(semantic_map, tf.float32)
return x, semantic_map主体部分
dataset = tf.data.Dataset.from_tensor_slices((train_image_filenames, train_label_filenames))
dataset = dataset.apply(tf.contrib.data.map_and_batch(
preprocess_fn, batch_size,
num_parallel_batches=4, # cpu cores
drop_remainder=True if is_training
dataset = dataset.repeat()
dataset = dataset.prefetch(tf.contrib.data.AUTOTUNE) # automatically picks best buffer_size回答 3
Stack Overflow用户
发布于 2018-07-10 12:36:12
您的数据处理管道究竟是什么样子?你有没有考虑过省略一些可能太贵的步骤?你的数据是如何存储的?是按需加载普通图像文件,还是预先将它们加载到内存中?通常加载JPG/PNG图像非常昂贵。
如果你在max_queue_size中增加model.fit_generator(),你能看到任何改进吗?
最后,您是否可以基准测试您的数据处理管道实际上有多快?例如,只生成几千个批,并确定每批处理的时间?
除此之外,我自己的经验是,当您的模型相对较小/不需要计算费用时,可能会发现GPU利用率很低。由于新的数据必须在批间输入GPU,所以您无法真正避免这种开销。当此开销与一次传递的实际计算时间之间的比率很高时,您可能会发现您的总体GPU utulization相对较低,甚至常常得到0%的值。
编辑:你能给我们提供更多关于你使用的模型的信息吗,特别是它主要由哪些层组成。例如,相对较小的CNN一次通过的计算时间可能非常短,因此在批间重新输入GPU所用的时间可能比实际计算的时间要多。
更新:在您添加了更多关于处理管道的信息之后,我想说您的主要瓶颈是PNG图像的加载和解码。PNG解压缩(以及更多的压缩)通常非常昂贵(据这消息来源称,大约是JPEG的5倍)。要检查这个假设,您可以通过确保每个处理步骤(解码、调整大小、裁剪等)的时间来分析处理管道。需求和主要贡献者是什么。
现在有许多优化处理管道的方法:
- 似乎您加载了普通的,未经处理的PNG图像与不同的图像大小。您至少可以将每个图像文件的大小调整到最终大小。这将节省存储,并应减少加载/解码开销。
- 使用JPEG代替。“真实世界”图像的质量差异在JPEG和PNG之间是最小的,但是JPEG占用的空间更少,解码成本更低。
- 如果有足够的存储空间,则可以将整批图像保存为最终格式的压缩Numpy数组。这可能会占用更多的空间,但也会大大减少加载时间。
Stack Overflow用户
发布于 2018-09-06 00:05:06
我正在处理类似的问题,并试图优化管道是一场艰苦的战斗。使用horovod而不是keras多gpu给了我几乎线性的速度,而keras多gpu却没有:https://medium.com/omnius/keras-horovod-distributed-deep-learning-on-steroids-94666e16673d。
tf.dataset绝对是该走的路。您可能还想做洗牌操作,以便更好地泛化。
另一件对我有很大改善的事情是预先调整图像大小,并将它们保存为np.save()作为.npy文件。他们节省了更多的空间,但是读起来要快一个数量级。我使用tf.py_func()将numpy操作转换为张量(由于python不能并行化)
Nvidia最近释放了DALI。它确实增强了GPU,这无疑是未来的道路。对于简单的分类任务,它可能已经具备了所需的所有功能。
Stack Overflow用户
发布于 2018-07-10 09:00:34
关于加工链,你是正确的。
在我的经验中,导致性能大幅提高的是并行数据加载(例如来自远程数据库)以及数据预处理。
通过这种方式,您可以在进行培训时继续处理下一批的数据,理想情况下,下一批处理的数据在GPU上完成最后一步培训后就可以完成。
如果你有非常沉重的预处理,与一个非常快速的训练步骤相比,这可能不会增加很难的表现。然后,我会说,你最好的选择是移动预处理,也移动GPU,例如使用CUDA。
编辑:如果这没有帮助,我会建议一个更深入的剖析。如果它确实是一些处理部分,请考虑如何加快速度,或者可能是一些简单的问题,其中列表而不是numpy用于数组操作。最后,您唯一的选择是保存预处理过的数据,而不是在运行时进行计算。另一种解决方案可能是在第一个处理之后缓存它(取决于您有多少ram )。
https://stackoverflow.com/questions/51260680
复制相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号