
一开始概率小于1的生存分析
我试图创建一个图表,显示一首歌曲在一段时间内进入公告牌百强排行榜前十名的可能性(图表中的几周)。当一首歌进入图表时,概率应该是0.15左右,接下来的每周都会下降。因此,图表应该是从0.15开始的下降曲线,x(图表中的周)和y(到达前10位的概率)。
1)我能用Kaplan-Meier曲线来做这件事吗?
2)如何在R(生存包)中创建一个不以1的概率开始的Kaplan-Meier曲线?
回答 2
Stack Overflow用户
发布于 2018-04-16 01:21:16
这是一个有趣的问题。我想也许stats.stackexchange.com会有更多的话要说。
我不认为这类似于生存,因此我认为Kaplan或任何其他的生存估计器不会做你想要的。
这是一种时过境迁的问题;对这个词的网络搜索可能会出现一些资源。但这并不是一个生存或可靠性问题,因为问题中的事件并非最终发生在所有受试者身上(就像死亡或机械故障一样)。事实上,这一事件非常罕见。
我的建议是,通过计算达到前10名的歌曲,自己算出概率。你提到的基本语句是计算pk = mk/nk,为了方便起见,我定义了mk =(歌曲数量至少停留在图表上k周,最终到达前10位)和nk =(在图表上停留至少k周的歌曲数量)。我认为pk在k中不一定是单调的--如果里面有一个颠簸,我不会感到惊讶。不管怎么说是要找的。
歌曲从图表上掉下来,回到上面,把图片搞得有点乱。我的建议是把他们当作一直在图表上的人对待。但对于如何处理这些问题,你可能有不同的想法。
我可以看到一个有趣的变化。那么pj,k=(在图表上的至少k周之后最终到达前10位的歌曲比例是j)呢?或者说是相同的,但是初始位置是j呢?毫无疑问还有其他人。
祝你好运,玩得开心。
Stack Overflow用户
发布于 2018-04-09 14:18:44
Kinda...sorta...not真的。
首先,你可能不想要一个典型的Kaplan曲线,它描绘了生存函数.你想要补体,或者累加发生率。(1 - S(x))。这将以0的概率开始情节,表示在发行的那一刻,没有歌曲就在前十位(有点,差不多吧)。
对于在第一周发布并排在榜首的歌曲,你需要将后续时间标记为0,前十名标志为1。这样,虽然step功能在技术上是从零开始的,但它将立即提升到前十名首周歌曲的比例。
例如:
library(survival)
df <-
data.frame(song = c("A", "B", "C", "D", "E"),
# number of weeks followed before reaching top ten
# (or truncation)
weeks_followed = c(0, 3, 4, 13, 1),
topten = c(1, 0, 1, 0, 1),
stringsAsFactors = FALSE)
fit <- survfit(Surv(weeks_followed, topten) ~ 1,
data = df)
plot(fit,
conf.int = FALSE,
# 1 - survival
fun = function(x) 1 - x,
xlim = c(0, 13),
ylim = c(0, 1))这就产生了以下情节:
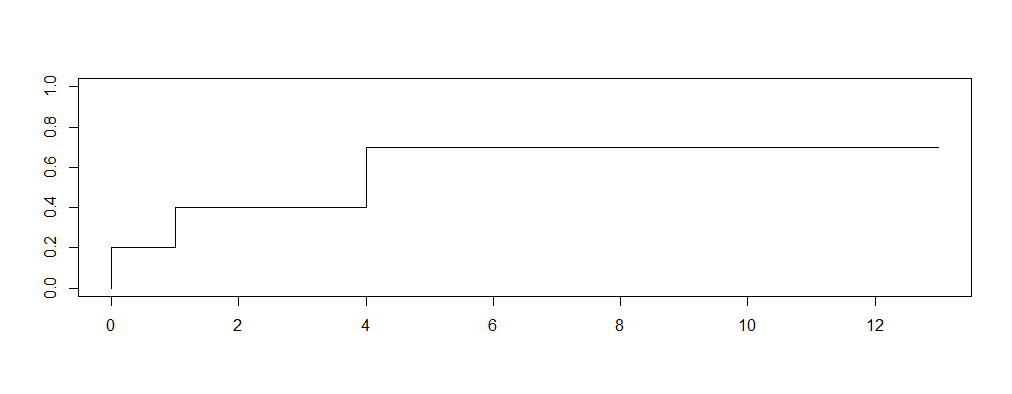
https://stackoverflow.com/questions/49733741
复制相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号