
基于Keras的情感分类器训练
基于Keras的情感分类器训练
提问于 2018-03-20 00:45:42
我使用keras (后端tensorflow)对亚马逊评论中的情感进行分类。
首先是嵌入层(使用GloVe),然后是LSTM层,最后是一个密集层作为输出。示范摘要如下:
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
embedding_1 (Embedding) (None, None, 100) 2258700
_________________________________________________________________
lstm_1 (LSTM) (None, 16) 7488
_________________________________________________________________
dense_1 (Dense) (None, 5) 85
=================================================================
Total params: 2,266,273
Trainable params: 2,266,273
Non-trainable params: 0
_________________________________________________________________
Train on 454728 samples, validate on 113683 samples训练时,训练精度约为74%,损失(训练和评估)约为0.6。
我尝试过改变LSTM层中元素的数量,包括辍学、反复辍学、正则化,以及GRU (而不是LSTM)。然后,准确度略有提高(~76%)。
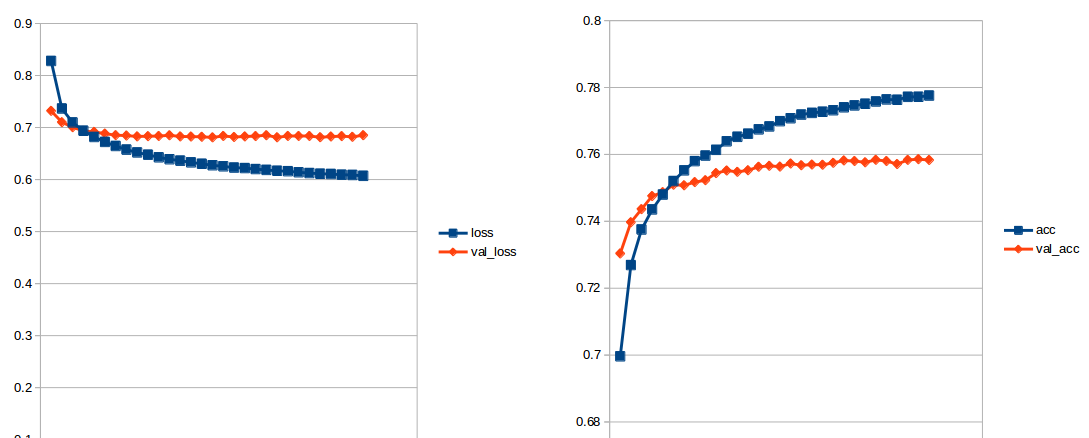
我还能尝试什么来提高我的成绩呢?
回答 1
Stack Overflow用户
回答已采纳
发布于 2018-03-20 00:56:09
我在情感分析方面取得了很大的成功,使用双向LSTM,也将两层垂直叠加在一起,即2层LSTMS,形成一个深网络,这也有助于并试图将lstm元素的数量增加到128左右。
页面原文内容由Stack Overflow提供。腾讯云小微IT领域专用引擎提供翻译支持
原文链接:
https://stackoverflow.com/questions/49374691
复制相关文章
相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号