
损失与准确度的关系
损失与准确度的关系
提问于 2017-12-29 16:10:48
在训练CNN模型时,是否有可能在每一个时期减少损失,降低准确度?我在训练的时候得到了下面的结果。
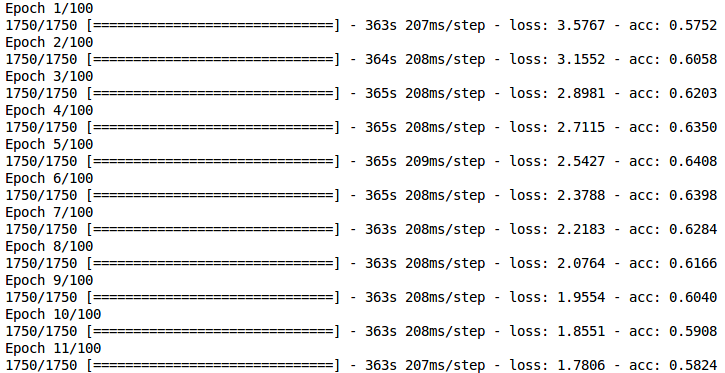
有人能解释一下发生这种情况的可能原因吗?
回答 4
Stack Overflow用户
回答已采纳
发布于 2018-01-03 20:33:59
至少有5个原因可能导致这种行为:
- Outliers:假设您有10个完全相同的图像,其中9个属于A类,另一个属于B类。在这种情况下,由于大多数示例,模型将开始为这个示例分配高概率的A类。但是,从离群点发出的信号可能会破坏模型的稳定性,使精度下降。理论上,一个模型应该稳定地将分数90%分配给A类,但它可能会持续很多时期。 解决方案:为了处理这些示例,我建议您使用梯度裁剪(您可以在优化器中添加这样的选项)。如果您想检查这种现象是否发生-您可以检查您的损失分布(个别例子的损失,从培训集),并寻找异常值。
- 偏差:现在假设您有10个完全相同的图像,但其中5个已经分配了A类、类和5级B。在这种情况下,模型将尝试在这两个类上分配大约50%-50%的发行版。现在-你的模型可以达到最多50%的准确性在这里-选择一个类别中的两个有效。 解决方案:试图增加模型容量--通常您有一组非常相似的图像--添加表达能力可能有助于区分类似的示例。不过,要当心过头了。另一个解决方案是在您的培训中尝试这策略。如果你想检查这种现象是否发生--检查损失的分布情况。如果一个分布会倾向于更高的值,那么您可能受到了偏倚的影响。
- 类不平衡:现在假设图像的90%属于A类。在您的培训的早期阶段,您的模型主要集中于将这个类分配给几乎所有的示例。这可能会使个人损失达到很高的价值,并使预测的分布更加不稳定,从而破坏模型的稳定性。
解决方案:再一次-梯度剪辑。第二件事--耐心,试着离开你的模型去追求更多的时代。一个模型应该在进一步的训练阶段学习更微妙的东西。当然,也可以通过分配
sample_weights或class_weights来尝试类平衡。如果您想检查这种现象是否发生-请检查您的类分布。 - 太强的正则化:如果您将正则化设置得太严格--训练过程主要集中在使您的体重比实际学习有趣的洞察力更小。
解决方案:添加一个
categorical_crossentropy作为度量,并观察它是否也在减少。如果没有--那就意味着你的正规化太严格了--试着减少重量的惩罚。 - 坏模型设计--这种行为可能是由错误的模型设计引起的。为了改进您的模型,可以采用以下几种良好做法: 批处理规范化-由于这种技术,您正在阻止模型从内部网络激活的根本变化。这使得训练更加稳定和有效。对于一个小批量大小,这也可能是一个真正的方式,以规范您的模型。 梯度裁剪-这使您的模型培训更加稳定和有效。 降低瓶颈效应,-阅读这精彩的论文,并检查您的模型是否可能遇到瓶颈问题。 添加辅助分类器--如果您正在从头开始培训您的网络--这将使您的功能更有意义,并且使您的培训更快、更高效。
Stack Overflow用户
发布于 2018-01-01 14:24:25
是的,这是可能的。
为了提供一个直观的例子来说明为什么会发生这种情况,假设您的分类器输出的A类和B类的概率大致相同,而A类的总体密度最高。在此设置中,最小限度地更改模型参数可能会将B转换为最可能的类。这一效应将使交叉熵损失的变化最小,因为它直接依赖于概率分布,但由于它取决于输出概率分布的最大程度,因此这种变化在精度上会被清楚地注意到。
结论是,最大限度地减小交叉熵损失并不总是意味着提高精度,主要是因为交叉熵是一个光滑函数,而精度是非光滑的。
Stack Overflow用户
发布于 2017-12-29 19:38:29
在精度下降的情况下,可以减少损失,但它远不能被称为一个好的模型。这个问题可以在模型的每一层使用批规范化来解决。
页面原文内容由Stack Overflow提供。腾讯云小微IT领域专用引擎提供翻译支持
原文链接:
https://stackoverflow.com/questions/48025267
复制相关文章
相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号