
卡桑德拉和G1垃圾收集器停止世界事件(STW)
我们有一个6节点的Cassandra集群正在被大量利用。我们一直在处理垃圾收集器停止世界事件,在我们的节点上可能需要50秒的时间,而Cassandra Node则反应迟钝,甚至不接受新的登录。
额外细节:
- 卡桑德拉版本: 3.11
- 堆大小= 12 GB
- 我们使用的是默认设置的G1垃圾收集器
- 节点大小:4个CPU,28 GB RAM
- 所有节点的G1 GC行为都是相同的。
任何帮助都是非常感谢的!
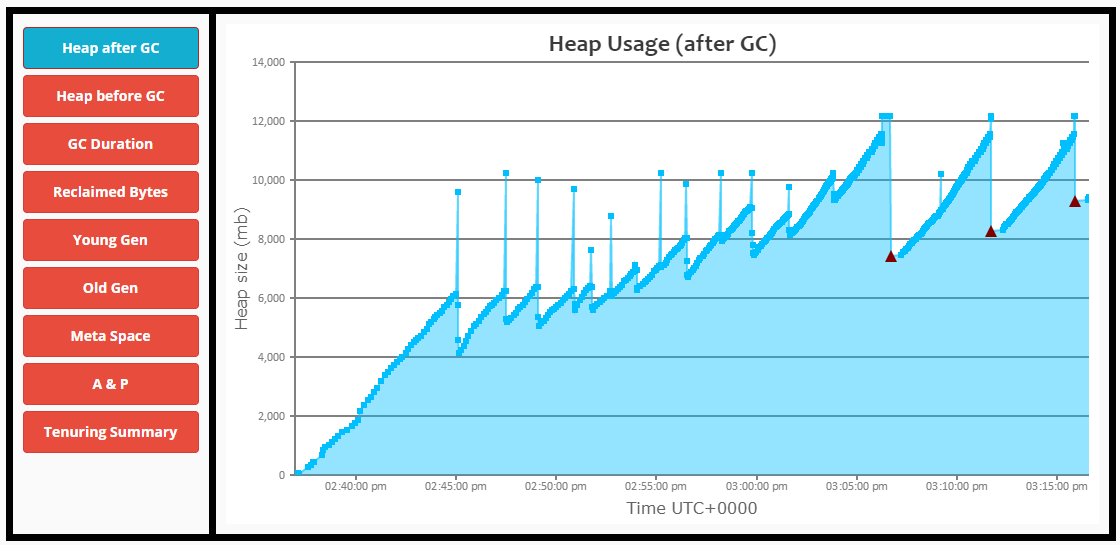
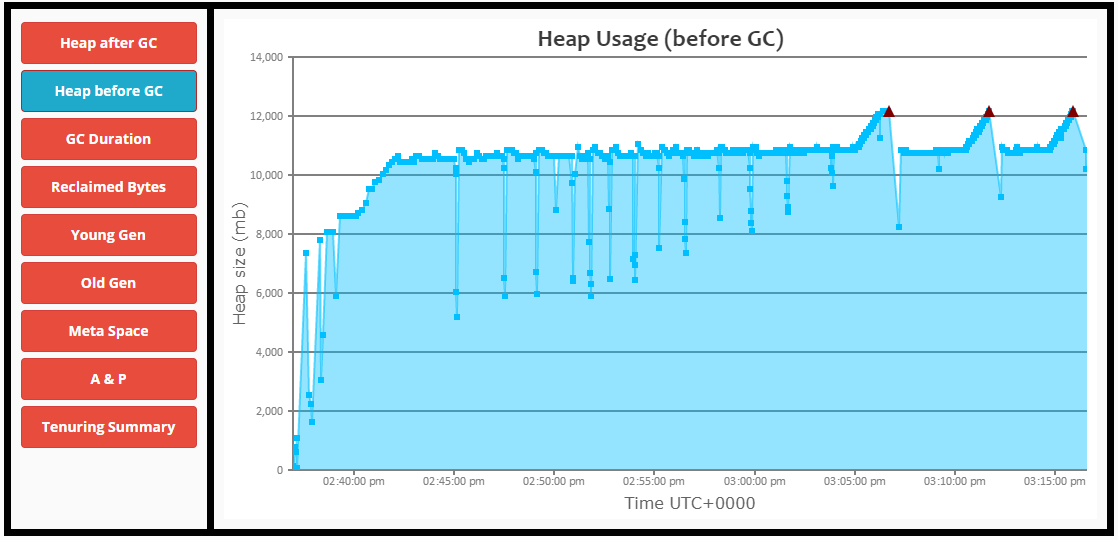
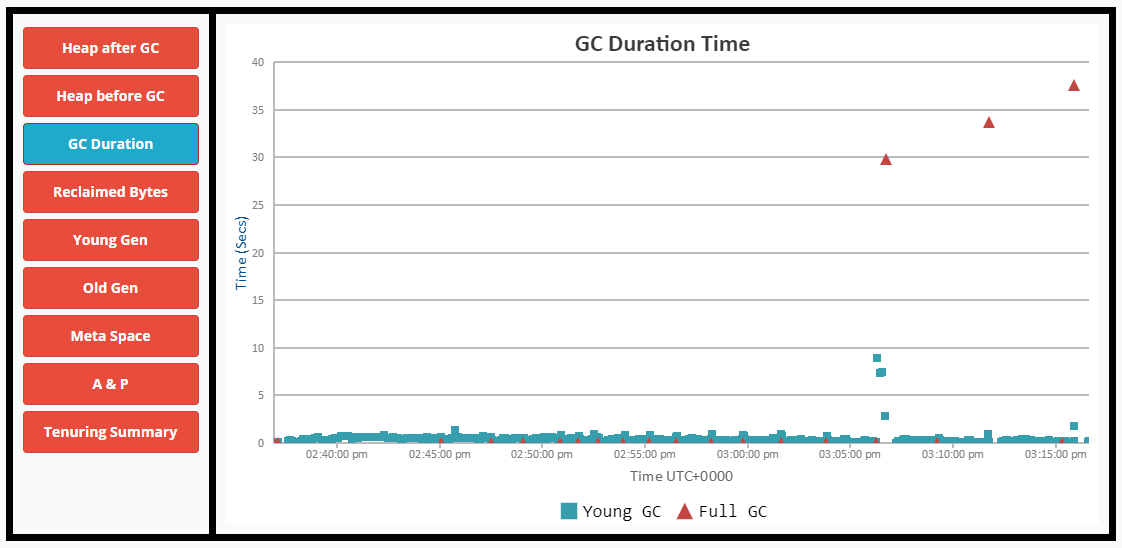
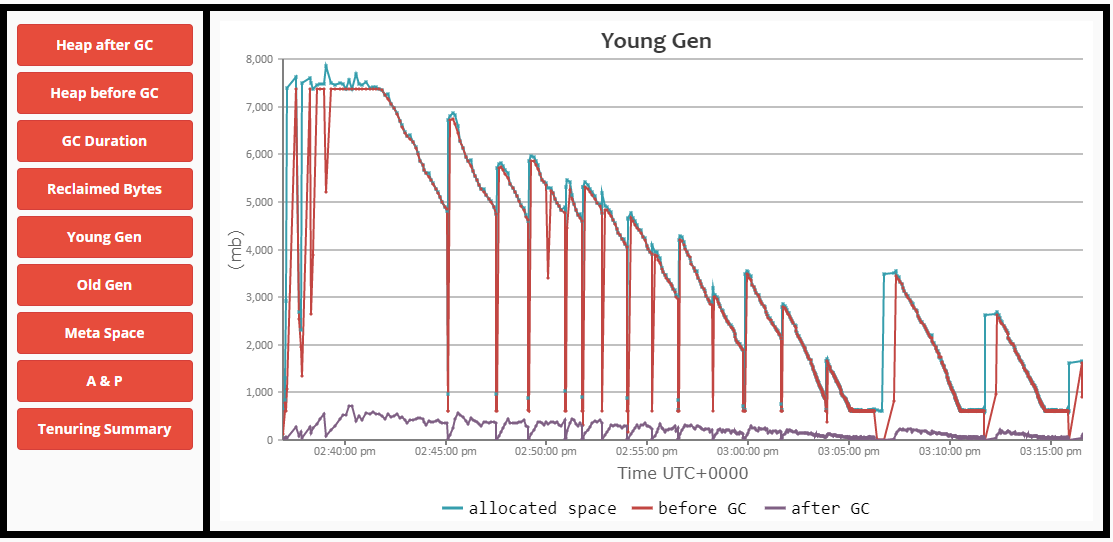
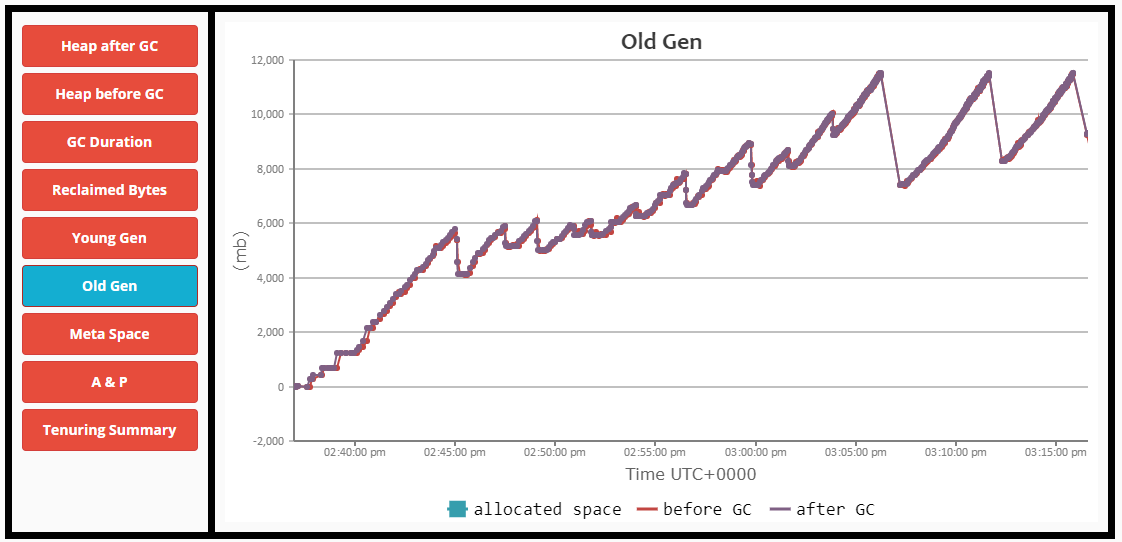
编辑1:
检查对象创建状态,它看起来一点也不健康。
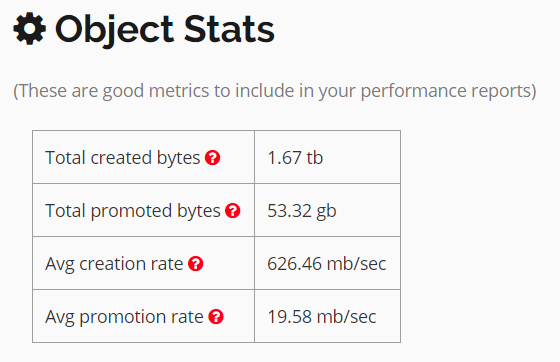
编辑2:
我尝试使用Chris 建议的设置,下面是GC报告:
使用CMS建议设置的 http://gceasy.io/my-gc-report.jsp?p=c2hhcmVkLzIwMTcvMTAvOC8tLWdjLmxvZy4wLmN1cnJlbnQtLTE5LTAtNDk=
使用G1建议的设置 http://gceasy.io/my-gc-report.jsp?p=c2hhcmVkLzIwMTcvMTAvOC8tLWdjLmxvZy4wLmN1cnJlbnQtLTE5LTExLTE3
行为基本保持不变:
- 老一代开始充满了。
- 如果没有完整的GC和STW事件,GC无法正确地清理它。
- 整个GC开始花费更长的时间,直到节点完全没有响应。
我将获得cfstats输出,以便每次读取最大分区大小和墓碑,并再次编辑post。
回答 2
Stack Overflow用户
发布于 2017-10-06 01:55:04
你看过使用Zing吗?像这样的Cassandra情况是一个典型的用例,Zing从根本上消除了Cassandra节点和集群中与GC相关的所有故障。
您可以在JavaOne (https://www.slideshare.net/howarddgreen/understanding-gc-javaone-2017)最近的“理解GC”演讲中看到关于如何/为什么这样做的一些细节。或者跳到56-60张卡桑德拉特定结果的幻灯片。
Stack Overflow用户
发布于 2017-10-04 19:32:26
在不知道您现有的设置或可能存在的数据模型问题的情况下,下面是一些保守设置的猜测,以尽量减少疏散暂停,因为没有足够的空间(查看gc日志):
-Xmx12G -Xms12G -XX:+UseG1GC -XX:G1ReservePercent=25 -XX:G1RSetUpdatingPauseTimePercent=5 -XX:MaxGCPauseMillis=500 -XX:-ReduceInitialCardMarks -XX:G1HeapRegionSize=32m这还应有助于通过设置G1HeapRegionSize来减少更新记忆集的暂停(这将成为一个问题),并减少大量对象,这可能会根据数据模型而成为一个问题。确保没有设置-Xmn。
使用C*的12 get可能更适合使用CMS,因为它的价值,您肯定可以获得更好的吞吐量。只是需要小心,随着时间的推移,对于可以分配的相当大的对象,要小心分割。
-XX:+UseConcMarkSweepGC -XX:CMSInitiatingOccupancyFraction=55 -XX:MaxTenuringThreshold=3 -Xmx12G -Xms12G -Xmn3G -XX:+CMSEdenChunksRecordAlways -XX:+CMSParallelInitialMarkEnabled -XX:+CMSParallelRemarkEnabled -XX:CMSWaitDuration=10000 -XX:+UseCMSInitiatingOccupancyOnly -XX:+UseCondCardMark 不过,数据模型或您的配置不足很可能存在问题。
https://stackoverflow.com/questions/46568777
复制相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号