
理解Seq2Seq模型
这是我对LSTM序列的理解。假设我们正在处理一个问答设置。
您有两套LSTM(绿色和蓝色)。每组分别共享权重(即,4个绿色单元中的每个具有相同的权重,并且与蓝色单元相似)。第一种是多到一的最小存储空间,它在最后一个隐藏层/单元内存中总结了问题。
第二组(蓝色)是一对多的LSTM,与第一组LSTM具有不同的权重。输入只是回答句,而输出是同一个句子,移动一句。
问题有两个方面: 1.我们是否将最后一个隐藏状态(仅)作为初始隐藏状态传递给蓝色LSTM。或者是最后一次隐藏状态和单元内存。2.是否有办法在Keras或Tensorflow中设置初始隐藏状态和单元内存?如果是这样的话?
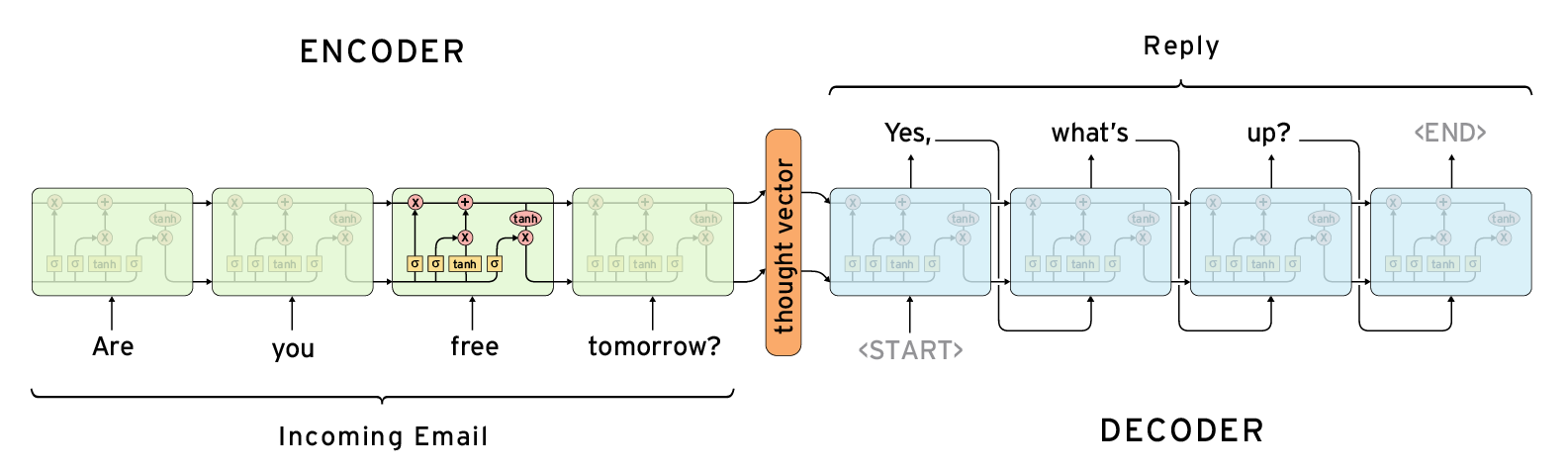
(图片取自suriyadeepan.github.io)
回答 2
Stack Overflow用户
发布于 2017-09-23 16:34:10
- 我们是否只将最后一个隐藏状态传递给蓝色LSTM作为初始隐藏状态。或者是最后一次隐藏状态和细胞记忆。
将隐藏状态h和单元存储器c传递给解码器。
TensorFlow
在seq2seq源代码中,您可以在basic_rnn_seq2seq()中找到以下代码
_, enc_state = rnn.static_rnn(enc_cell, encoder_inputs, dtype=dtype)
return rnn_decoder(decoder_inputs, enc_state, cell)如果使用LSTMCell,则编码器返回的enc_state将是元组(c, h)。如您所见,元组直接传递给解码器。
喀拉斯
在Keras中,为LSTMCell定义的“状态”也是元组(h, c) (注意顺序与TF不同)。在LSTMCell.call()中,您可以找到:
h_tm1 = states[0]
c_tm1 = states[1]要获得从LSTM层返回的状态,可以指定return_state=True。返回的值是一个元组(o, h, c)。张量o是该层的输出,除非您指定return_sequences=True,否则它将等于h。
- 是否有方法在Keras或Tensorflow中设置初始隐藏状态和单元内存?如果是这样的话?
###TensorFlow###只需在调用它时向LSTMCell提供初始状态。例如,在官方RNN教程中
lstm = tf.contrib.rnn.BasicLSTMCell(lstm_size)
...
output, state = lstm(current_batch_of_words, state)还有一个函数(如initial_state )的tf.nn.static_rnn参数。如果使用seq2seq模块,向rnn_decoder提供问题1的代码中所示的状态。
###Keras###
在LSTM函数调用中使用关键字参数initial_state。
out = LSTM(32)(input_tensor, initial_state=(h, c))实际上,您可以在正式文件上找到这种用法。
###Note指定RNNs###的初始状态 通过使用关键字参数
initial_state调用RNN层,可以象征性地指定RNN层的初始状态。initial_state的值应该是表示RNN层初始状态的张量或张量列表。
编辑:
现在有一个Keras (seq2seq.py)中的示例脚本,演示如何在Keras中实现基本的seq2seq。本脚本还介绍了如何在训练seq2seq模型之后进行预测。
Stack Overflow用户
发布于 2017-09-22 06:14:19
(编辑:这个答案是不完整的,没有考虑到国家转移的实际可能性。见已接受的答案)。
从Keras的角度来看,该图片只有两个层。
- 绿色组为一个LSTM层。
- 蓝色组是另一个LSTM层。
除了传递输出之外,绿色和蓝色之间没有任何通信。因此,第一个问题的答案是:
- 只有思想向量(即该层的实际输出)被传递到另一层。
内存和状态(不确定它们是否是两个不同的实体)完全包含在单个层中,最初不打算与任何其他层看到或共享。
图像中的每个单独的块在角星中都是完全不可见的。它们被认为是“时间步骤”,仅以输入数据的形式出现。担心它们很少是很重要的(除非对于非常高级的用法)。
在角星,它是这样的:
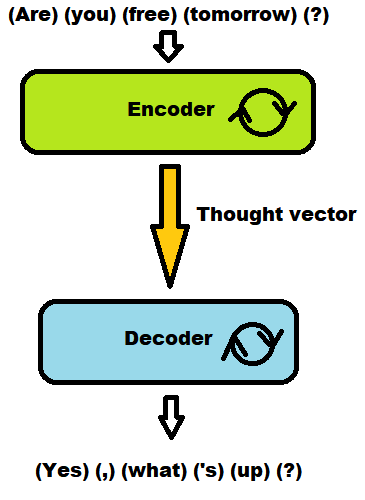
很容易,您只能访问外部箭头(包括“思想向量”)。
但是,能够访问每个步骤(图片中的每个单独的绿色块)并不是一件公开的事情。所以..。
- 在Keras中也不期望将状态从一个层传递到另一个层。你可能得黑点东西。(参见:https://github.com/fchollet/keras/issues/2995)
但是,考虑到一个足够大的思想向量,你可以说它将学习一种方法来携带本身重要的东西。
您从这些步骤中得到的唯一概念是:
- 您必须输入形状类似于
(sentences, length, wordIdFeatures)的东西
考虑到长度维度中的每个切片都是每个绿色块的输入,将执行这些步骤。
您可以选择拥有一个输出(sentences, cells),对于该输出,您完全失去了步骤的跟踪。或者..。
- 像
(sentences, length, cells)这样的输出,您可以从它知道每个块通过长度维度的输出。
一对多还是多对多?
现在,第一层是多到一层(但是如果你想的话,没有什么能阻止它成为多层或多层)。
但是第二个..。这很复杂。
- 如果思想向量是由一对一的人组成的。你必须设法创造一个一对多的方法。(这在keras中并不简单,但您可以考虑重复所期望的长度的思想向量,使其成为所有步骤的输入。或者用0或1填充整个序列,只保留第一个元素作为思想向量)
- 如果思想向量是由许多人组成的,那么您可以利用这一点,让许多人对多人轻松,如果您愿意接受输出的步骤与输入完全相同的话。
对于1到许多情况,Keras没有现成的解决方案。(从单个输入可以预测整个序列)。
https://stackoverflow.com/questions/46355651
复制相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号