
R: mle()错误的麻烦:非有限差分值[2]
我有一个简单的x, y data.frame。
mydata <- data.frame(days = 1:96, risk = c(5e-09, 5e-09, 5e-09, 1e-08, 4e-08, 6e-08, 9e-08, 1.5e-07, 4.2e-07,
7.2e-07, 1.02e-06, 1.32e-06, 1.66e-06, 2.19e-06, 2.76e-06, 3.32e-06,
3.89e-06, 4.55e-06, 5.8e-06, 7.16e-06, 8.51e-06, 9.85e-06, 1.138e-05,
1.396e-05, 1.672e-05, 1.947e-05, 2.222e-05, 2.521e-05, 2.968e-05,
3.439e-05, 3.909e-05, 4.378e-05, 4.894e-05, 5.697e-05, 6.546e-05,
7.392e-05, 8.236e-05, 9.16e-05, 0.00010573, 0.00012063, 0.00013547,
0.00015025, 0.00016642, 0.00019127, 0.00021743, 0.00024343, 0.00026924,
0.00029818, 0.00034681, 0.00039832, 0.00044932, 0.00049976, 0.0005451,
0.00056293, 0.00057586, 0.00058838, 0.0006005, 0.00061562, 0.00065079,
0.00068845, 0.00072508, 0.00076062, 0.00079763, 0.00084886, 0.00090081,
0.0009507, 0.00099844, 0.00104427, 0.00108948, 0.00113175, 0.00117056,
0.00120576, 0.00123701, 0.00126253, 0.00128269, 0.00129757, 0.00130716,
0.00131291, 0.00132079, 0.0013216, 0.00131392, 0.00129806, 0.00127247,
0.00122689, 0.00117065, 0.00110696, 0.00103735, 0.00095951, 0.00085668,
0.0007517, 0.00065083, 0.000556, 0.0004669, 0.00037675, 0.00029625,
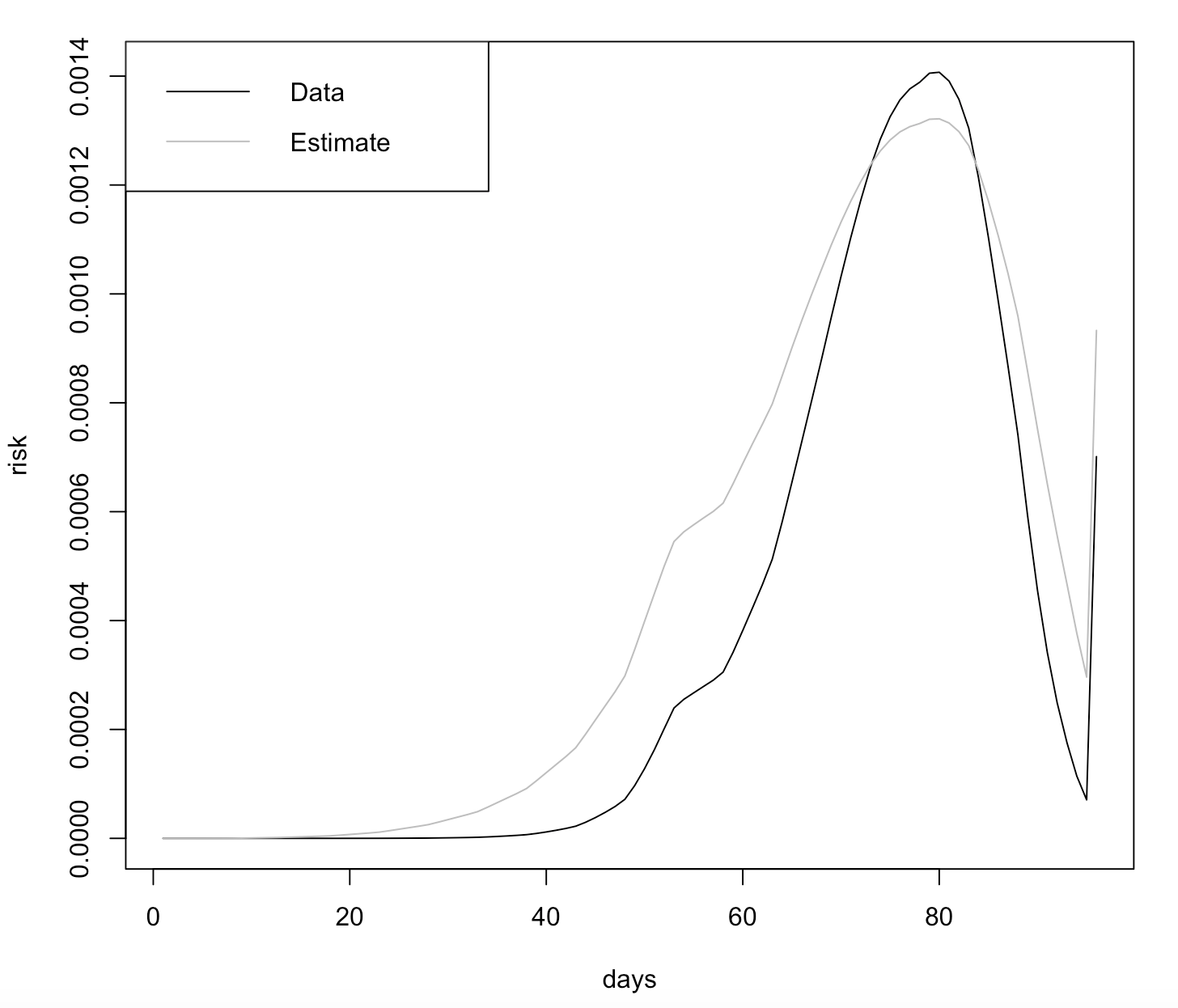
0.00093289))从下面的情节来看,我认为Weibull(3, 0.155)非常适合我的数据。
plot(1:96, dweibull(mydata$risk, shape = 3, scale = 0.155), type = "l", xlab = "days", ylab = "risk")
lines(mydata, type = "l", col = "grey")
legend("topleft", c("Data", "Estimate"), col = c("black", "grey"), lty = c(1, 1))
我编写了一个计算负日志可能性的函数,它将被传递到mle中.
estimate <- function(kappa, lambda){
-sum(dweibull(mydata$y, shape = kappa, scale = lambda, log = TRUE))
}我调用mle,提供我的初始参数估计,并获得以下错误。
> mle(estimate, start = list(kappa = 3, lambda = 0.155))
Error in optim(start, f, method = method, hessian = TRUE, ...) :
non-finite finite-difference value [2]
In addition: There were 50 or more warnings (use warnings() to see the first 50)这里出了什么问题?
回答 1
Stack Overflow用户
发布于 2017-09-22 03:45:13
你想做什么?据我所知,您有一个96值的“风险”数据集,您希望将它的分布与weibull相匹配。请注意,如果是这样的话,"days“一点也不相关。你有一个无序的值向量。
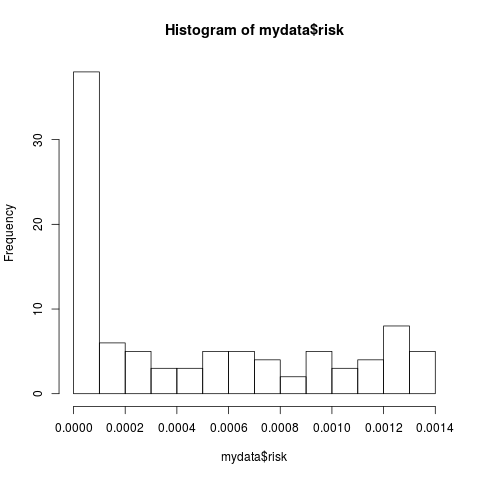
以上数字具有误导性。计算风险值的dweibull()。该数字表明,dweibull(risk)大致等于风险。这是一个与威布尔不同的主张,给定的参数是一个很好的契合。
例如,下面是数据的分布:hist(mydata$risk, breaks=15)
而参数在相关范围内的威布尔密度如下所示:curve((function(x) dweibull(x, shape=3, scale=0.155))(x), 0, 0.0014)
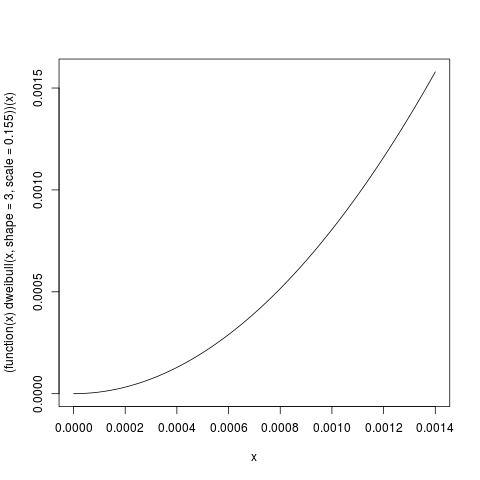
因此,这些分布是非常不同的。我会说,你们的经验分布是均匀的,加上零的质量,而不是威布尔。
现在是最后一个问题:由于分布不适合,优化器会遇到数值奇点。我对mle()不太了解,但是只要稍微调整一下,maxLik::maxLik()就会发现这个问题:
estimate <- function(par){
Kappa <- par[1]
Lambda <- par[2]
dweibull(mydata$risk, shape = Kappa, scale = Lambda, log = TRUE)
}
summary(maxLik::maxLik(estimate, start=c(Kappa=3, Lambda=0.155), method="BHHH"))给你
--------------------------------------------
Maximum Likelihood estimation
BHHH maximisation, 43 iterations
Return code 2: successive function values within tolerance limit
Log-Likelihood: 682.743
2 free parameters
Estimates:
Estimate Std. error t value Pr(> t)
Kappa 0.4849129 0.0473720 10.236 < 2e-16 ***
Lambda 0.0002953 0.0001028 2.873 0.00407 **
---
Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1
--------------------------------------------请注意,我做了一个重大更改:从日志可能性中删除sum,并使用BHHH优化器。这通常比基于单个求和可能性的优化更稳定。您还应该认真考虑编写用于估计的解析导数。
您现在可以检查发行版看起来更相似了。
https://stackoverflow.com/questions/46312000
复制相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号