
拟合曲线:描述加权知识图中分布的哪种模型
作为一个表示知识网络和学习加权图性质的简单模型,我计算了维基百科文章之间的余弦相似度。
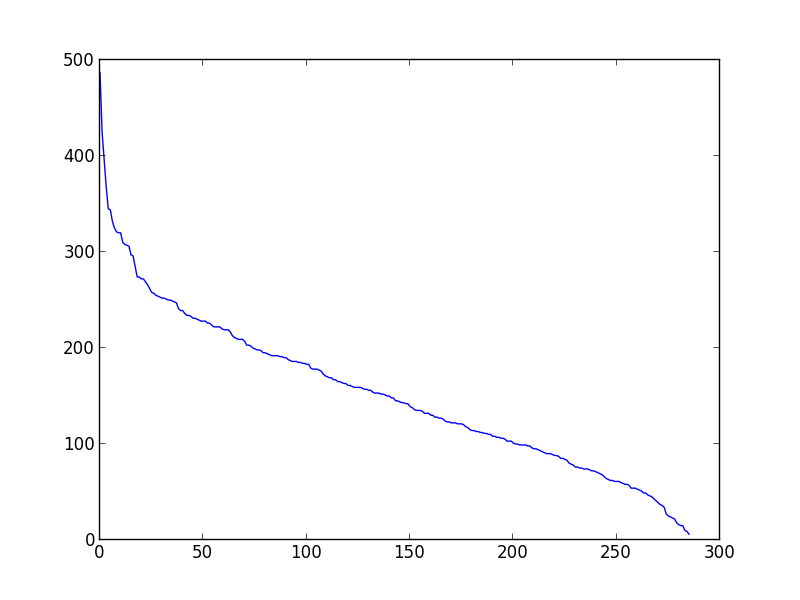
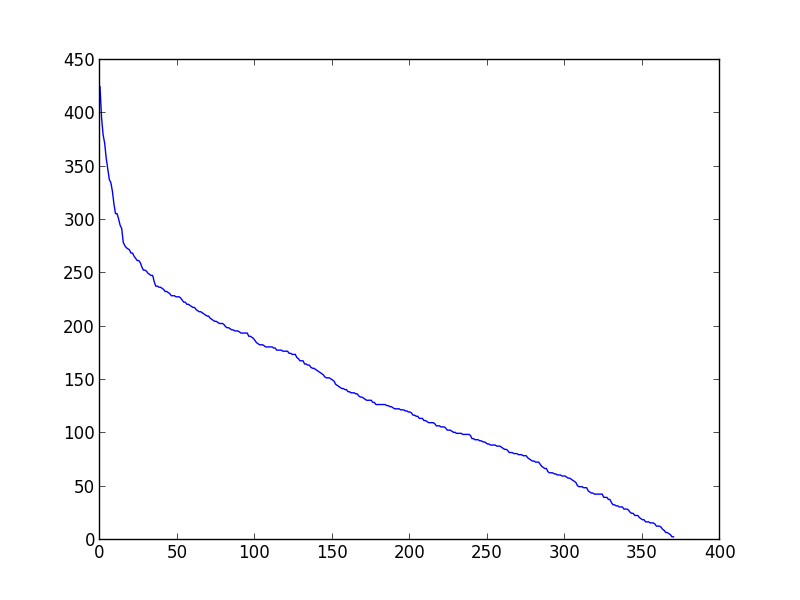
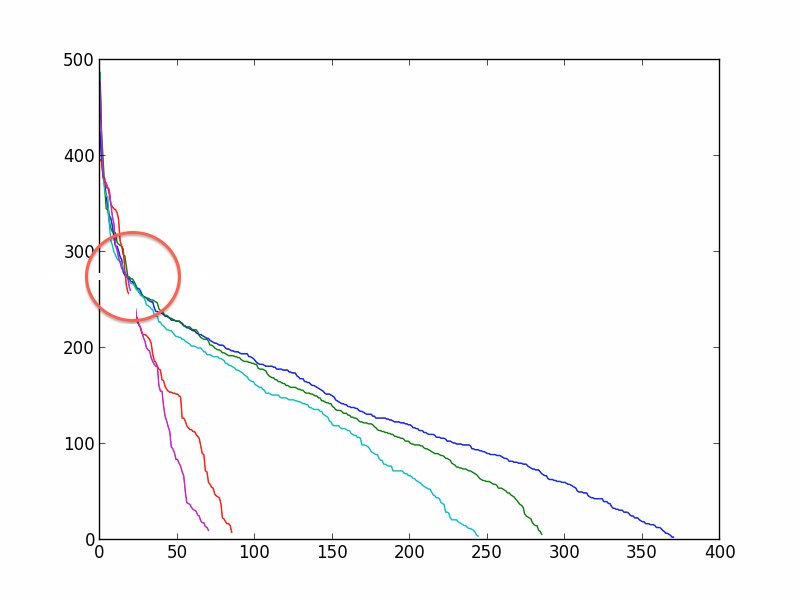
我现在看的是每一篇文章的相似权重的分布(见图)。
在图片中,你可以看到曲线改变了某个值(从指数到线性)的导数:我想对曲线进行拟合并提取这个值,在那里,导数可以明显地(或预期地)变化,这样我就可以将相似的文章分成两组:“最相似的”(阈值的左边)和“其他的”(阈值的右侧)。
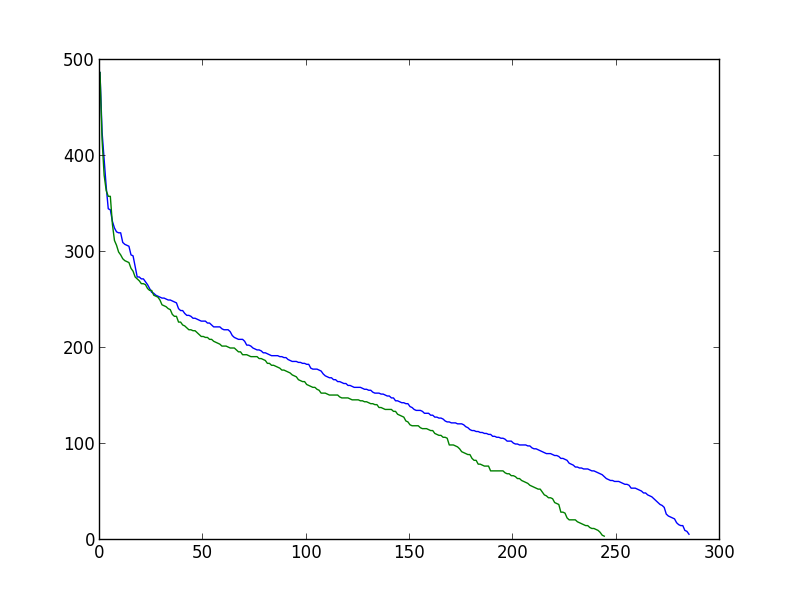
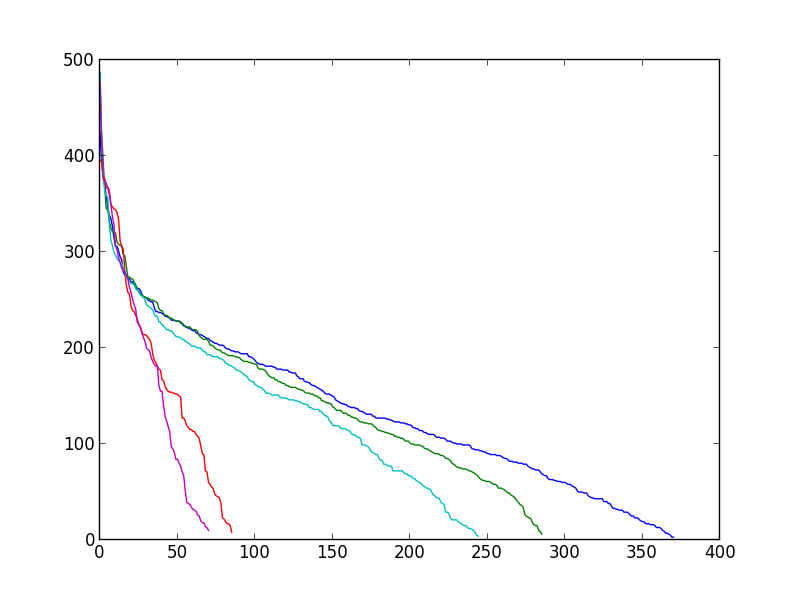
我想对每一篇文章的分布进行拟合;比较所有文章的分布与平均分布;比较分布与随机加权网络的分布之间的关系。(在定义工作流程时,你的建议是最受欢迎的:你知道我想用这个模型作为玩具模型,然后训练一个网络或一篇文章如何及时发展)。
我的背景是对数据科学有扭曲的用户体验,我希望更好地理解哪个模型可以描述我观察到的值的分布,比较分布的适当方法,以及python工具(或Mathematica 11)来拟合曲线并获得每个点的导数。
- 您建议采用哪种模型来描述在加权网络中对象之间的相似值的分布(这里,协作知识库被表示为加权网络,其中权重是两篇给定文章的相似值-我应该期望指数吗?)一个伪君子?为什么?)
- 如何计算曲线拟合并提取给定点曲线的导数(python或Mathematica 11)
回答 1
Stack Overflow用户
发布于 2017-08-18 15:15:40
使用Mathematica时,假设数据在列表data中。然后,如果您想找到最适合您的数据的三次多项式,请使用Fit函数:
Fit[data, {1, x, x^2, x^3}, x]通常,Fit命令的用法如下所示
Fit["data set", "list of functions", "independent variable"] 它试图将列表中的函数线性组合到你的数据集中。我不知道该用什么样的曲线来描述这些数据,但请记住,任何光滑函数都可以用一个多项式来逼近任意精度,并且有足够多的项。因此,如果您有足够的计算能力,只需让您的函数列表成为x功能的长列表。虽然看起来在x=0上有一个渐近线,但是可能允许在那里有一个1/x项来捕捉它。当然,您可以使用Plot在数据的顶部绘制曲线,以直观地比较它们。
现在,要获得这个最适合的曲线,可以在Mathematica中作为一个函数,你可以得到以下的导数:
f[x_] := Fit[data, {1, x, x^2, x^3}, x]然后,当二阶导数为零时,就会发生明显的变化,因此要得到x值:
NSolve[f''[x] == 0, x]https://stackoverflow.com/questions/45757813
复制相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号