
如何解释textsum模型的损失曲线?
如何解释textsum模型的损失曲线?
提问于 2017-08-15 22:42:13
我一直在训练文本和seq2seq w/注意模型的摘要摘要的训练语料库600 k文章+摘要。这算不算趋同呢?如果是这样的话,那么,在不到5k步的情况下,它会不会是正确的呢?考虑因素:
- 我已经训练过200 K的声乐了
- 5k步骤(直到接近收敛)的批次大小为4,这意味着最多可看到20k不同的样本。这只是整个训练语料库的一小部分。
或者我实际上没有看到我的狗的脸在茶叶和边缘负斜率是否如预期的?
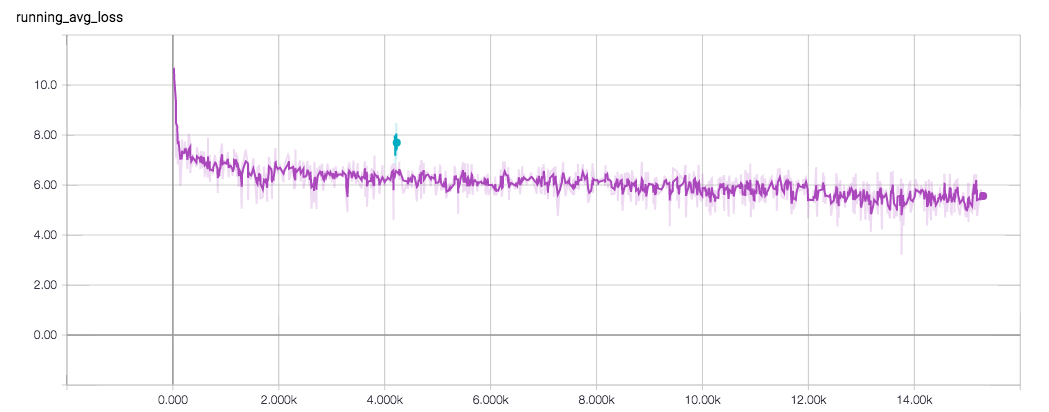
回答 1
Stack Overflow用户
发布于 2017-09-11 09:49:15
好的,我实际上切换到了GPU (而不是CPU)上的训练,并证明了模型仍然在学习。以下是初始化一个全新模型后的学习曲线:
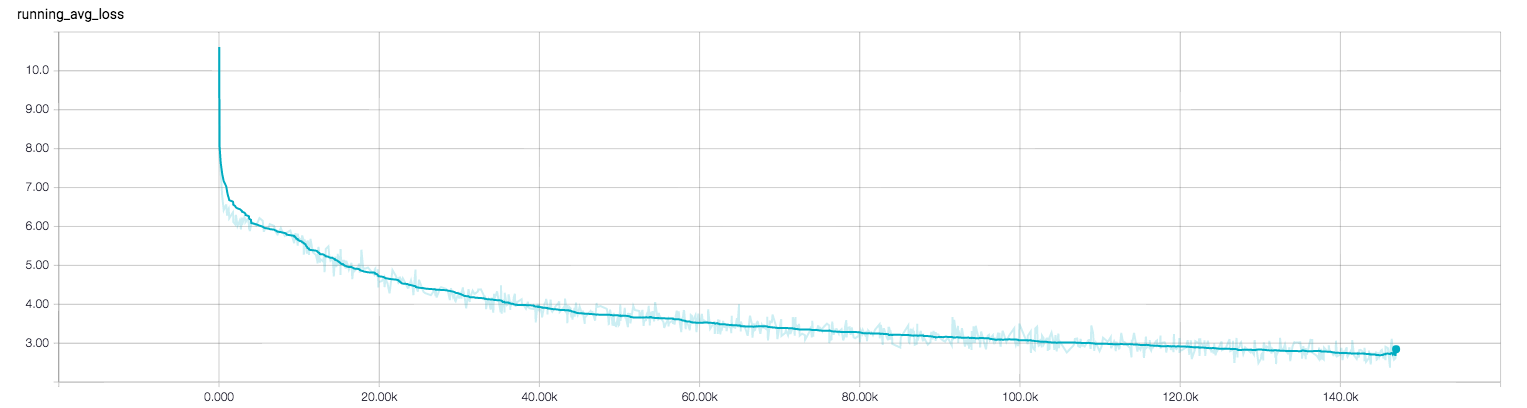
使用AWSp2.x大型NVIDIA K80,加速比约为30倍。
页面原文内容由Stack Overflow提供。腾讯云小微IT领域专用引擎提供翻译支持
原文链接:
https://stackoverflow.com/questions/45702608
复制相关文章
相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号