
如何研究每个数据对深层神经网络模型的影响?
如何研究每个数据对深层神经网络模型的影响?
提问于 2017-07-13 06:09:49
我正在用Python和Keras库训练一个神经网络模型。
我的模型测试准确率很低(60.0%),我试图提高它,但我做不到,我使用DEAP数据集(总共32名参与者)来训练模型。我使用的分裂技术是固定的。其内容如下:28名学员参加了培训,2名参加了验证,2名参加了测试。
对于我使用的模型,如下所示。
- 序贯模型
- 优化器= Adam
- 使用L2_regularizer,高斯噪声,丢包和批归一化
- 隐藏层数=3
- 激活= relu
- 编译损失= categorical_crossentropy
- 初始化器= he_normal
现在,我用火车测试技术(也是固定的)来分割数据,我得到了更好的结果。然而,我发现有些参与者正以负面的方式影响训练的准确性。因此,我想知道是否有方法研究每个数据(参与者)对模型的准确性(性能)的影响?
诚挚的问候,
回答 2
Stack Overflow用户
发布于 2018-04-13 10:10:07
在我的动手深入学习: CIFAR-10的图像分类教程中,我坚持要跟踪这两个方面:
- 全局度量(日志丢失、准确性),
- 示例(正确和错误地分类案例)。
后者可以帮助我们知道哪种模式是有问题的,并且在许多情况下帮助我改变了网络(如果是这样的话,可以补充培训数据)。
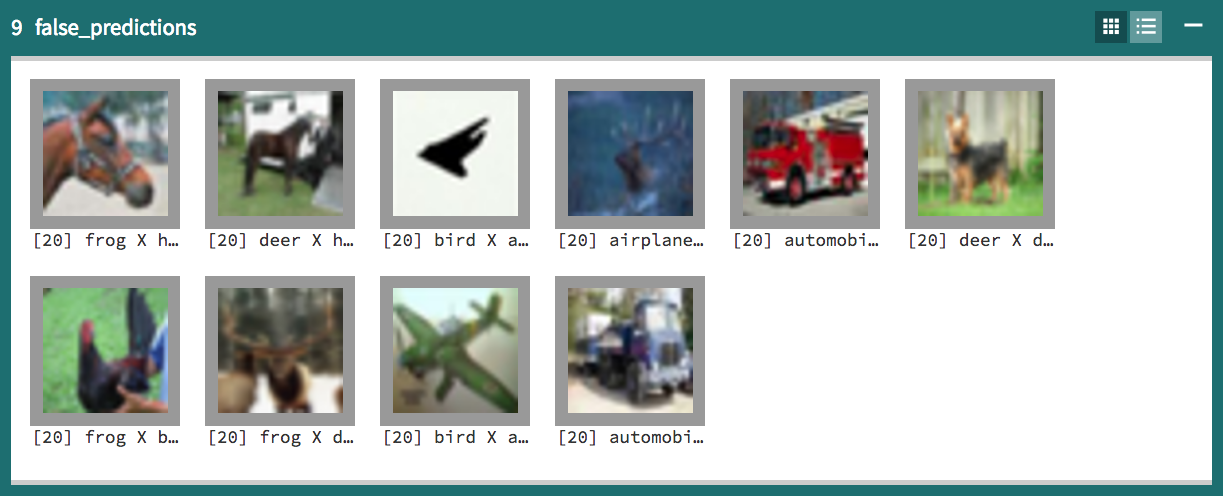
例如,它是如何工作的(在这里使用海王星,尽管您可以在木星笔记本中手动完成,也可以使用TensorBoard图像通道):
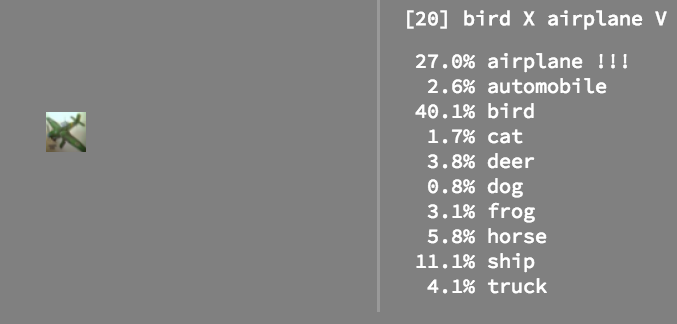
然后看看具体的例子,以及预测的概率:
完全免责声明:我与deepsense.ai、创建者或海王星-机器学习实验室合作。
Stack Overflow用户
发布于 2019-04-24 09:37:10
页面原文内容由Stack Overflow提供。腾讯云小微IT领域专用引擎提供翻译支持
原文链接:
https://stackoverflow.com/questions/45072636
复制相关文章
相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号