
如何避免简单前馈网络上的过度拟合
使用pima印第安人糖尿病数据集,我试图使用Keras构建一个精确的模型。我编写了以下代码:
# Visualize training history
from keras import callbacks
from keras.layers import Dropout
tb = callbacks.TensorBoard(log_dir='/.logs', histogram_freq=10, batch_size=32,
write_graph=True, write_grads=True, write_images=False,
embeddings_freq=0, embeddings_layer_names=None, embeddings_metadata=None)
# Visualize training history
from keras.models import Sequential
from keras.layers import Dense
import matplotlib.pyplot as plt
import numpy
# fix random seed for reproducibility
seed = 7
numpy.random.seed(seed)
# load pima indians dataset
dataset = numpy.loadtxt("pima-indians-diabetes.csv", delimiter=",")
# split into input (X) and output (Y) variables
X = dataset[:, 0:8]
Y = dataset[:, 8]
# create model
model = Sequential()
model.add(Dense(12, input_dim=8, kernel_initializer='uniform', activation='relu', name='first_input'))
model.add(Dense(500, activation='tanh', name='first_hidden'))
model.add(Dropout(0.5, name='dropout_1'))
model.add(Dense(8, activation='relu', name='second_hidden'))
model.add(Dense(1, activation='sigmoid', name='output_layer'))
# Compile model
model.compile(loss='binary_crossentropy',
optimizer='rmsprop',
metrics=['accuracy'])
# Fit the model
history = model.fit(X, Y, validation_split=0.33, epochs=1000, batch_size=10, verbose=0, callbacks=[tb])
# list all data in history
print(history.history.keys())
# summarize history for accuracy
plt.plot(history.history['acc'])
plt.plot(history.history['val_acc'])
plt.title('model accuracy')
plt.ylabel('accuracy')
plt.xlabel('epoch')
plt.legend(['train', 'test'], loc='upper left')
plt.show()
# summarize history for loss
plt.plot(history.history['loss'])
plt.plot(history.history['val_loss'])
plt.title('model loss')
plt.ylabel('loss')
plt.xlabel('epoch')
plt.legend(['train', 'test'], loc='upper left')
plt.show()经过几次尝试,我增加了辍学层,以避免过度适应,但没有运气。下图显示验证损失和训练损失在某一点上是分开的。
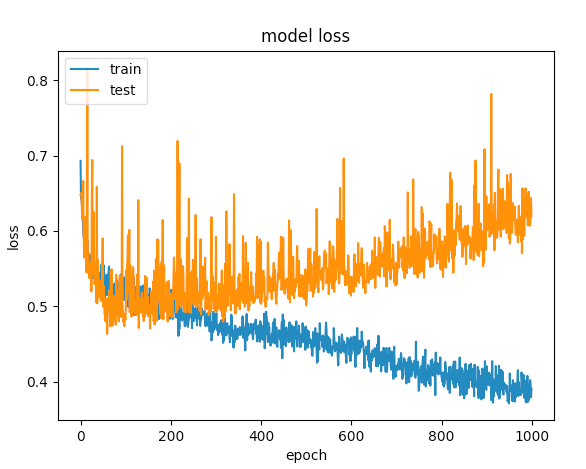
我还能做什么来优化这个网络呢?
更新:基于我得到的注释,我对代码进行了如下调整:
model = Sequential()
model.add(Dense(12, input_dim=8, kernel_initializer='uniform', kernel_regularizer=regularizers.l2(0.01),
activity_regularizer=regularizers.l1(0.01), activation='relu',
name='first_input')) # added regularizers
model.add(Dense(8, activation='relu', name='first_hidden')) # reduced to 8 neurons
model.add(Dropout(0.5, name='dropout_1'))
model.add(Dense(5, activation='relu', name='second_hidden'))
model.add(Dense(1, activation='sigmoid', name='output_layer'))以下是500个年代的图表
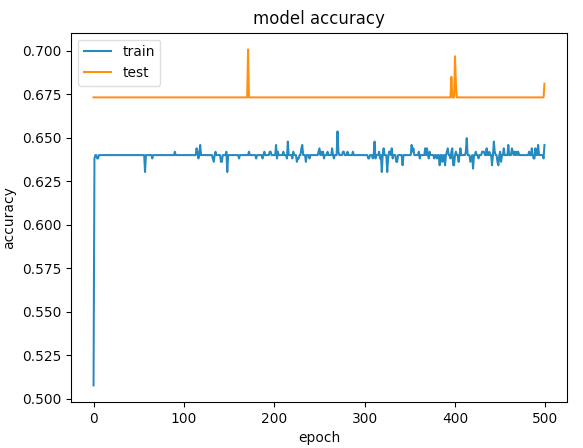
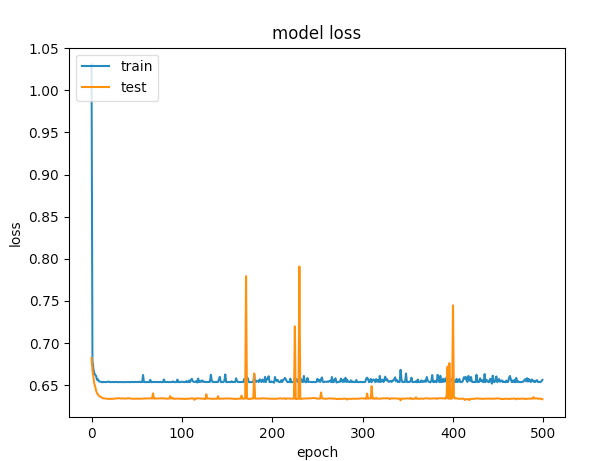
回答 3
Stack Overflow用户
发布于 2017-07-08 11:34:03
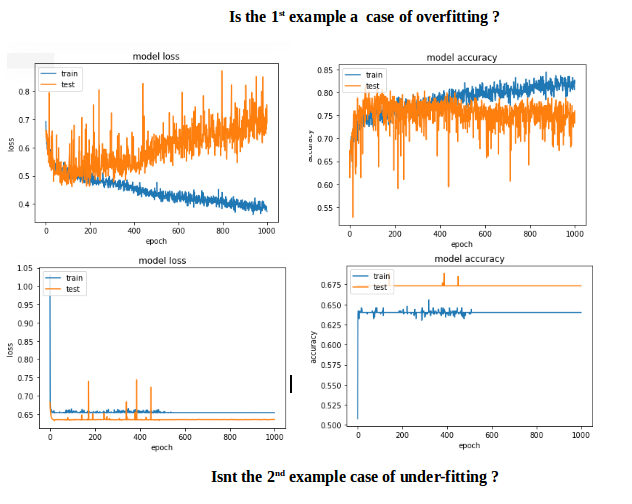
第一个实例给出的验证精度> 75%,第二个实例给出的精度< 65%,如果比较100以下的损失,第一个和第二个的损失小于0.5,则> 0.6。但是第二个案子怎么样了?
对我来说,第二个例子是under-fitting:这个模型没有足够的学习能力。而第一例有over-fitting的问题,因为它的训练没有停止时,过度适应开始(early stopping)。如果在100年代停止训练,这将是一个更好的模式之间的两个。
我们的目标应该是在看不见的数据中获得小的预测误差,并为此增加网络的容量,直到超过这一点时才会发生过度拟合。
那么,在这种特殊情况下如何避免over-fitting呢?采用early stopping。
代码更改:包含early stopping和input scaling。
# input scaling
scaler = StandardScaler()
X = scaler.fit_transform(X)
# Early stopping
early_stop = EarlyStopping(monitor='val_loss', min_delta=0, patience=3, verbose=1, mode='auto')
# create model - almost the same code
model = Sequential()
model.add(Dense(12, input_dim=8, activation='relu', name='first_input'))
model.add(Dense(500, activation='relu', name='first_hidden'))
model.add(Dropout(0.5, name='dropout_1'))
model.add(Dense(8, activation='relu', name='second_hidden'))
model.add(Dense(1, activation='sigmoid', name='output_layer')))
history = model.fit(X, Y, validation_split=0.33, epochs=1000, batch_size=10, verbose=0, callbacks=[tb, early_stop])Accuracy和loss图:
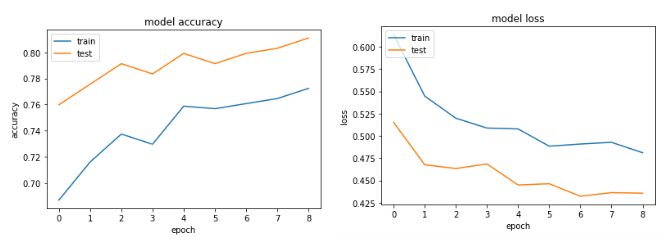
Stack Overflow用户
发布于 2017-07-04 15:08:05
首先,尝试添加一些正则化(https://keras.io/regularizers/),如下代码所示:
model.add(Dense(12, input_dim=12,
kernel_regularizer=regularizers.l2(0.01),
activity_regularizer=regularizers.l1(0.01)))同时,确保减少你的网络大小,即你不需要一个隐藏的500个神经元层--试着把它去掉,以降低表示能力,如果它仍然太合适的话,甚至还会减少另一层。此外,只使用relu激活。也许还可以尝试将辍学率提高到0.75左右(虽然这个数字已经很高)。您可能也不需要运行这么多的时代-它将只是开始过度适应足够长的时间。
Stack Overflow用户
发布于 2017-07-04 15:06:02
对于像糖尿病这样的数据集,您可以使用一个简单得多的网络。试着减少你第二层的神经元。(你选择tanh作为激活有什么具体原因吗?)
此外,您只需在培训中添加一个EarlyStopping回调:https://keras.io/callbacks/
https://stackoverflow.com/questions/44909134
复制相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号