
高度依赖于testval的PyMC3二项开关点模型
高度依赖于testval的PyMC3二项开关点模型
提问于 2017-04-26 21:10:36
我在PyMC3中建立了以下二项式开关点模型:
with pm.Model() as switchpoint_model:
switchpoint = pm.DiscreteUniform('switchpoint', lower=df['covariate'].min(), upper=df['covariate'].max())
# Priors for pre- and post-switch parameters
early_rate = pm.Beta('early_rate', 1, 1)
late_rate = pm.Beta('late_rate', 1, 1)
# Allocate appropriate binomial probabilities to years before and after current
p = pm.math.switch(switchpoint >= df['covariate'].values, early_rate, late_rate)
p = pm.Deterministic('p', p)
y = pm.Binomial('y', p=p, n=df['trials'].values, observed=df['successes'].values)它似乎运行得很好,只是它完全以开关点(999)的一个值为中心,如下所示。
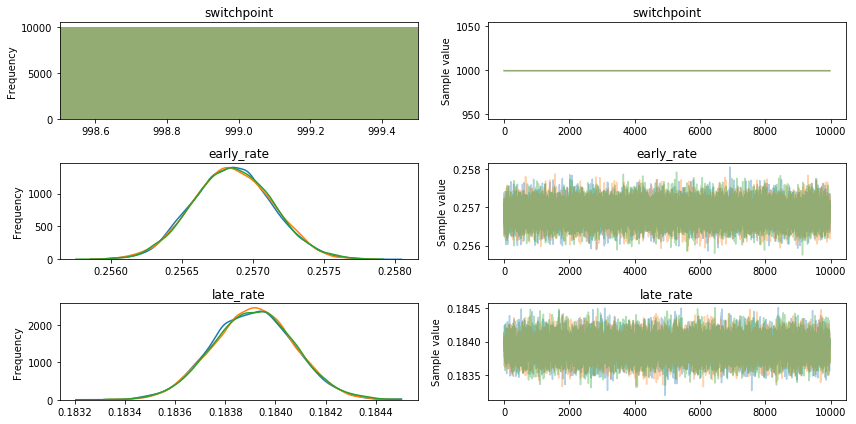
经过进一步研究,该模型的结果似乎高度依赖于初始值(在PyMC3中,"testval")。下面显示了当我设置testval = 750时会发生什么。
switchpoint = pm.DiscreteUniform('switchpoint', lower=gp['covariate'].min(),
upper=gp['covariate'].max(), testval=750)
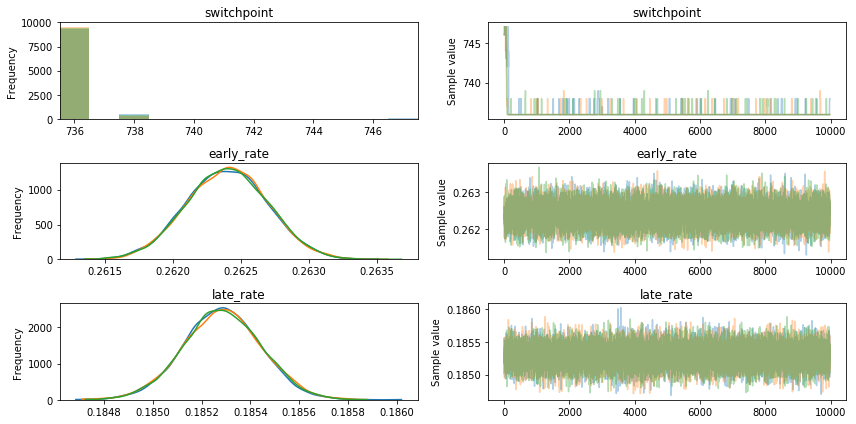
通过附加不同的起始值,我得到了类似的不同结果。
对于上下文,这是我的数据集的样子:
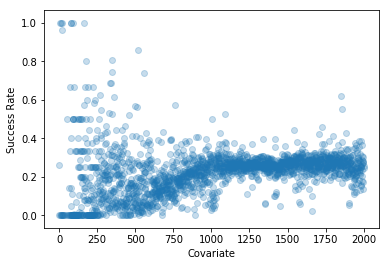
我的问题是:
- 我的模型被错误地指定了吗?
- 如果它被正确地指定,我应该如何解释这些结果?特别是,如何比较/选择由不同测试生成的结果?我唯一的想法就是用世界人工智能大会来评估样本外的表现.
回答 1
Stack Overflow用户
回答已采纳
发布于 2017-05-02 09:58:55
带有离散值的模型是有问题的,所有使用导数的好的采样技术都不再起作用,而且它们的行为很像多模态分布。在这种情况下,我不太明白为什么这会有那么大的问题,但是您可以尝试为开关点使用一个连续变量(这在概念上也更有意义吗?)
页面原文内容由Stack Overflow提供。腾讯云小微IT领域专用引擎提供翻译支持
原文链接:
https://stackoverflow.com/questions/43644587
复制相关文章
相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号