
坦赫需要多少次失败?
回答 3
Stack Overflow用户
发布于 2017-03-25 10:32:41
注意:这个答案并不是python特定的,但我不认为像tanh这样的东西在不同语言之间有根本的不同。
Tanh通常通过定义上界和下界来实现,分别返回1和-1。中间部分由以下不同的功能近似:
Interval 0 x_small x_medium x_large
tanh(x) | x | polynomial approx. | 1-(2/(1+exp(2x))) | 1存在精度可达单精度浮点的多项式,也有双精度多项式。这种算法称为Cody算法.
引用这一描述 (您也可以在那里找到更多关于数学的信息,例如如何确定x_medium),Cody和Waite的有理形式需要四个乘法、三个加法和一个单精度除法,以及七个乘法、六个加法和一个双精度除法。
对于负x,你可以计算x,然后翻转符号。因此,您需要比较哪个区间x在其中,并计算相应的近似。总共有:
- 取x的绝对值
- 3区间的比较
- 根据时间间隔和浮动精度,指数为0到几次失败,检查这个问题如何计算指数。
- 一个决定是否翻转标志的比较。
现在,这是1993年的一份报告,但我不认为这里有太大变化。
Stack Overflow用户
发布于 2017-03-25 20:51:25
如果我们看一下tanh(x)的glibc实现,我们就会看到:
- 对于
x值大于22.0和双精度的情况,可以安全地假定tanh(x)为1.0,因此几乎没有成本。 - 对于非常小的
x(比方说x<2^(-55)),另一种廉价的近似是可能的:tanh(x)=x(1+x),因此只需要两个浮点操作。 - 对于以甲虫为单位的值,可以重写
tanh(x)=(1-exp(-2x))/(1+exp(-2x))。但是,我们必须准确,因为1-exp(t)对于由于失去意义而产生的小t值来说是非常麻烦的,所以我们使用expm(x)=exp(x)-1并计算tanh(x)=-expm1(-2x)/(expm1(-2x)+2)。
基本上,最坏的情况是expm1所需的操作数的2倍,这是一个非常复杂的函数。最好的方法可能只是测量计算tanh(x)所需的时间,而不是简单的两倍乘法所需的时间。
我在英特尔处理器上进行的(草率的)实验得出了以下结果,这给出了一个粗略的想法:
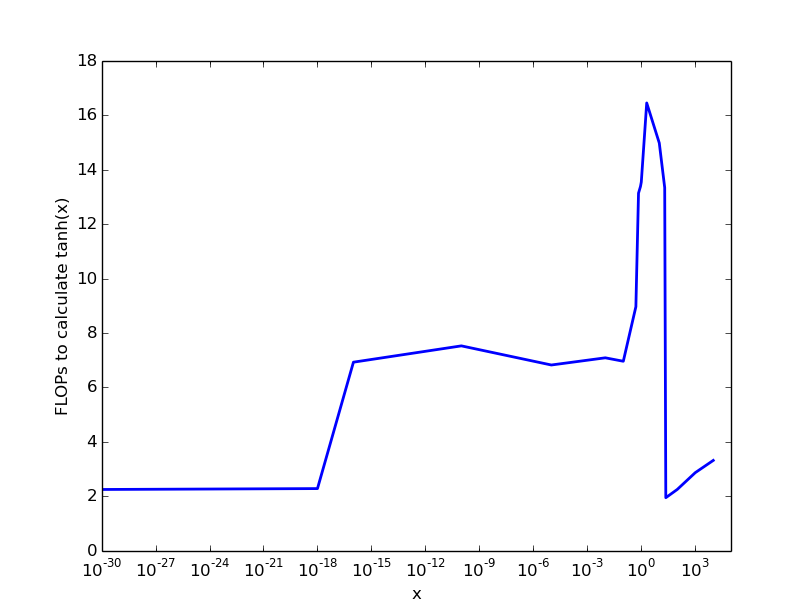
因此,对于非常小和数字>22,几乎没有成本,对于0.1的数字,我们支付6次失败,然后成本上升到每tanh-caclulation大约20次失败。
关键是:计算tanh(x)的成本取决于参数x,最大成本在10到100个失败之间。
有一个名为F2XM1的英特尔指令,它计算2^x-1 for -1.0<x<1.0,它可以用于计算tanh,至少在一定范围内是这样。然而,如果阿格纳桌被相信,这一行动的成本大约是60次失败。
另一个问题是矢量化--正常的glibc实现--据我所见,实现没有向量化。因此,如果您的程序使用矢量化,并且必须使用非矢量化的tanh实现,那么它将进一步降低程序的速度。为此,英特尔编译器拥有mkl库,其中tanh是其中之一.
正如你在表格中所看到的,每个操作的最大成本大约是10个时钟(浮点操作的成本大约是1个时钟)。
我想您可能会通过使用-ffast-math编译器选项赢得一些失败,这会导致一个更快但不太精确的程序(这是Cuda或c/c++的一个选项,不确定这是否可以用于python/numpy)。
生成图形数据的c++代码(用g++ -std=c++11 -O2编译)。它的意图不是给出确切的数字,而是给出有关费用的第一印象:
#include <chrono>
#include <iostream>
#include <vector>
#include <math.h>
int main(){
const std::vector<double> starts={1e-30, 1e-18, 1e-16, 1e-10, 1e-5, 1e-2, 1e-1, 0.5, 0.7, 0.9, 1.0, 2.0, 10, 20, 23, 100,1e3, 1e4};
const double FACTOR=1.0+1e-11;
const size_t ITER=100000000;
//warm-up:
double res=1.0;
for(size_t i=0;i<4*ITER;i++){
res*=FACTOR;
}
//overhead:
auto begin = std::chrono::high_resolution_clock::now();
for(size_t i=0;i<ITER;i++){
res*=FACTOR;
}
auto end = std::chrono::high_resolution_clock::now();
auto overhead=std::chrono::duration_cast<std::chrono::nanoseconds>(end-begin).count();
//std::cout<<"overhead: "<<overhead<<"\n";
//experiments:
for(auto start : starts){
begin=std::chrono::high_resolution_clock::now();
for(size_t i=0;i<ITER;i++){
res*=tanh(start);
start*=FACTOR;
}
auto end = std::chrono::high_resolution_clock::now();
auto time_needed=std::chrono::duration_cast<std::chrono::nanoseconds>(end-begin).count();
std::cout<<start<<" "<<time_needed/overhead<<"\n";
}
//overhead check:
begin = std::chrono::high_resolution_clock::now();
for(size_t i=0;i<ITER;i++){
res*=FACTOR;
}
end = std::chrono::high_resolution_clock::now();
auto overhead_new=std::chrono::duration_cast<std::chrono::nanoseconds>(end-begin).count();
std::cerr<<"overhead check: "<<overhead/overhead_new<<"\n";
std::cerr<<res;//don't optimize anything out...
}Stack Overflow用户
发布于 2021-04-07 20:00:27
这个问题表明它是在机器学习的背景下提出的,因此重点是单精度计算,特别是使用IEEE-754 binary32格式。Asker声称NVIDIA GPU是一个令人感兴趣的平台。我将重点介绍使用CUDA的这些GPU,因为我不熟悉CUDA的Python绑定。
说到失败,除了简单的加法和乘法之外,还有很多关于如何计算它们的思想流派。例如,GPU计算软件中的除法和平方根。识别浮点指令并对其进行计数是不那么模棱两可的,这就是我在这里要做的。请注意,并非所有浮点指令都将以相同的吞吐量执行,而且这也可能取决于GPU体系结构。有关指令吞吐量的一些相关信息可在CUDA编程指南中找到。
从图灵体系结构(计算能力7.5)开始,GPU包括一个指令MUFU.TANH,用于计算单精度双曲正切,精度约为16位。由多功能单元(MUFU)支持的单精度函数通常是通过存储在ROM中的表中的二次插值来计算的。据我所知,MUFU.TANH是在虚拟汇编语言PTX的层次上公开的,但并不是(截至CUDA11.2)作为设备功能固有的。
但是,考虑到该功能是在PTX级别公开的,我们可以很容易地用一行内联程序集来创建自己的内部程序集:
// Compute hyperbolic tangent for >= sm75. maxulperr = 133.95290, maxrelerr = 1.1126e-5
__forceinline__ __device__ float __tanhf (float a)
{
asm ("tanh.approx.f32 %0,%1; \n\t" : "=f"(a) : "f"(a));
return a;
}在较老的计算能力< 7.5的GPU体系结构上,通过代数变换和机器指令MUFU.EX2和MUFU.RCP,分别计算指数基2和倒数,实现了具有非常接近匹配特性的固有GPU。对于大小较小的参数,我们可以使用tanh(x) =x,并在实验上确定这两种近似之间的一个很好的转换点。
// like copysignf(); when first argument is known to be positive
__forceinline__ __device__ float copysignf_pos (float a, float b)
{
return __int_as_float (__float_as_int (a) | (__float_as_int (b) & 0x80000000));
}
// Compute hyperbolic tangent for < sm_75. maxulperr = 108.82848, maxrelerr = 9.3450e-6
__forceinline__ __device__ float __tanhf (float a)
{
const float L2E = 1.442695041f;
float e, r, s, t, d;
s = fabsf (a);
t = -L2E * 2.0f * s;
asm ("ex2.approx.ftz.f32 %0,%1;\n\t" : "=f"(e) : "f"(t));
d = e + 1.0f;
asm ("rcp.approx.ftz.f32 %0,%1;\n\t" : "=f"(r) : "f"(d));
r = fmaf (e, -r, r);
if (s < 4.997253418e-3f) r = a;
if (!isnan (a)) r = copysignf_pos (r, a);
return r;
}用CUDA11.2编译sm_70目标代码,然后用cuobjdump --dump-sass解压缩二进制代码,显示了8个浮点指令。我们还可以看到,生成的机器代码(SASS)是无分支的。
如果我们想要一个双曲正切,具有完全的单精度精度,我们可以用极小极大多项式逼近小量值,而用代数变换和机器指令MUFU.EX2和MUFU.RCP来表示较大的量值。超过一定程度的论证,结果将是±1。
// Compute hyperbolic tangent. maxulperr = 1.81484, maxrelerr = 1.9547e-7
__forceinline__ __device__ float my_tanhf (float a)
{
const float L2E = 1.442695041f;
float p, s, t, r;
t = fabsf (a);
if (t >= 307.0f/512.0f) { // 0.599609375
r = L2E * 2.0f * t;
asm ("ex2.approx.ftz.f32 %0,%1;\n\t" : "=f"(r) : "f"(r));
r = 1.0f + r;
asm ("rcp.approx.ftz.f32 %0,%1;\n\t" : "=f"(r) : "f"(r));
r = fmaf (r, -2.0f, 1.0f);
if (t >= 9.03125f) r = 1.0f;
r = copysignf_pos (r, a);
} else {
s = a * a;
p = 1.57394409e-2f; // 0x1.01e000p-6
p = fmaf (p, s, -5.23025580e-2f); // -0x1.ac766ap-5
p = fmaf (p, s, 1.33152470e-1f); // 0x1.10b23ep-3
p = fmaf (p, s, -3.33327681e-1f); // -0x1.5553dap-2
p = fmaf (p, s, 0.0f);
r = fmaf (p, a, a);
}
return r;
}这段代码包含一个依赖于数据的分支,通过查看CUDA11.2为sm75目标生成的机器代码就可以看出分支被保留了。这意味着,一般来说,在所有活动线程中,一些线程将跟随分支的一边,而其余线程将跟随分支的另一端,需要随后的同步。因此,要想对所需的计算工作有一个实际的想法,我们需要将两种执行路径的浮点指令的计数结合起来。这是十三个浮点指令。
以上代码注释中的错误界限是通过对所有可能的单精度参数进行彻底测试而建立的。
https://stackoverflow.com/questions/41251698
复制相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号