
将大于内存的数据写入bcolz
将大于内存的数据写入bcolz
提问于 2016-12-05 06:28:17
因此,我得到了一个大的滴答数据文件(有一天,60 to未压缩),我想要放入bcolz。我计划逐块读取这个文件,并将它们附加到bcolz中。
据我所知,bcolz只支持附加列,而不支持行。不过,我想说的是,滴答数据比列数据更倾向于行。例如:
0 ACTX.IV 0 13.6316 2016-09-26 03:45:00.846 ARCA 66
1 ACWF.IV 0 23.9702 2016-09-26 03:45:00.846 ARCA 66
2 ACWV.IV 0 76.4004 2016-09-26 03:45:00.846 ARCA 66
3 ALTY.IV 0 15.5851 2016-09-26 03:45:00.846 ARCA 66
4 AMLP.IV 0 12.5845 2016-09-26 03:45:00.846 ARCA 66 - 有人对如何做这件事有什么建议吗?
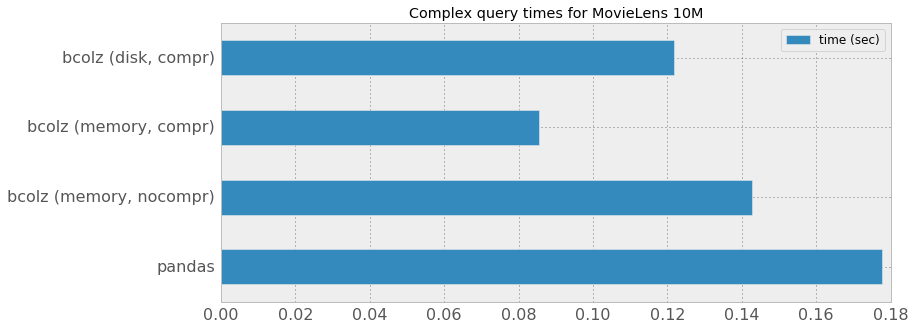
- 在使用bcolz时,是否有任何关于压缩级别的建议。我更关心的是更晚的查询速度,而不是大小。(我问这个问题,因为如下所示,第一级压缩的bcolz ctable实际上比未压缩的查询速度要好。所以我猜查询速度不是一个单调的压缩级别的函数)。参考资料:http://nbviewer.jupyter.org/github/Blosc/movielens-bench/blob/master/querying-ep14.ipynb
提前感谢!
回答 1
Stack Overflow用户
发布于 2017-02-09 15:59:50
- 你可以这样做: 输入bz ds = bz.data('my_file.csv')表示bz.odo中的块(ds,bz.chunks(pd.DataFrame),chunksize=1000000):bcolz.ctable.fromdataframe(块,rootdir=dir_path_for_chunk,mode='w',cparams=your_compression_params) 而不是使用bcolz.walk对块进行迭代。
- 默认(blosc第5级)在大多数情况下都是合适的。如果您想要获得每一点性能,就必须从大小在1-2GB左右的真实数据创建示例文件,并使用不同的压缩参数测试性能。
页面原文内容由Stack Overflow提供。腾讯云小微IT领域专用引擎提供翻译支持
原文链接:
https://stackoverflow.com/questions/40968326
复制相关文章
相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号