
如何通过R中的纯素绘制期望丰富度曲线(Chao1)?
如何通过R中的纯素绘制期望丰富度曲线(Chao1)?
提问于 2016-11-25 10:52:13
我有一个来自一个网站的数据集,其中包含物种及其丰度的数据(样本中每个物种的个体数)。我用纯素包进行α多样性分析。例如,我用折射函数绘制了一条物种折射曲线(因为我有一个站点的数据,所以不能使用散斑函数),然后通过Chao1函数计算出一个estimateR指数。
如何使用Chao1函数绘制estimateR期望的丰富度曲线?然后,我想把这些曲线组合在一个单独的图上。
library(vegan)
TR <- matrix(nrow=1,c(3,1,1,17,1,1,1,1,1,2,1,1,3,13,31,24,6,1,1,4,1,10,2,3,1,5,6,1,1,1,4,16,17,15,6,9,66,3,1,3,24,15,2,3,17,1,7,2,27,13,2,1,1,3,1,3,30,7,1,1,4,1,2,5,1,1,6,2,1,9,11,5,8,7,2,2,2,1,13,3,8,4,1,5,27,1,62,13,6,7,7,4,9,1,7,7,1,25,1,5,3,1,2,1,1,5,2,73,25,17,43,88,2,3,38,4,5,6,6,16,2,13,10,7,1,2,9,3,1,3,1,8,4,4,5,13,2,25,9,2,1,12,29,4,1,9,1,1,3,4,2,9,4,26,2,7,4,18,1,10,10,4,6,5,20,1,2,11,1,3,1,2,1,1,12,3,2,1,4,24,7,22,19,43,2,9,18,1,1,1,9,7,6,1,8,2,2,19,7,26,4,4,1,3,4,5,2,4,8,2,3,1,5,5,1,11,6,6,2,4,3,1,10,6,9,16,1,1,32,1,1,31,2,12,2,13,1,2,9,13,1,11,8,1,14,5,9,1,3,1,7,1,1,13,17,1,1,3,2,9,1,4,1,7,2,2,9,24,20,2,1,2,2,1,9,5,1,1,23,13,7,1,8,5,47,32,6,13,16,8,2,1,5,4,3,1,2,1,1,1,3,14,6,21,2,7,2,2,16,2,10,21,18,2,1,3,33,12,55,4,1,5,14,3,10,2,4,1,2,5,7,6,2,12,14,28,18,30,28,7,1,1,1,3,4,2,17,60,31,3,3,2,2,3,6,2,6,1,13,2,3,13,7,2,10,19,9,7,1,3))
num_species=specnumber(TR)
chao1=estimateR(TR)[2,]
shannon=diversity(TR,"shannon")
rarecurve(TR)
estimateR(TR)下面是一个以EstimateS输出(我输入相同数据)为基础的SigmaPlot图:
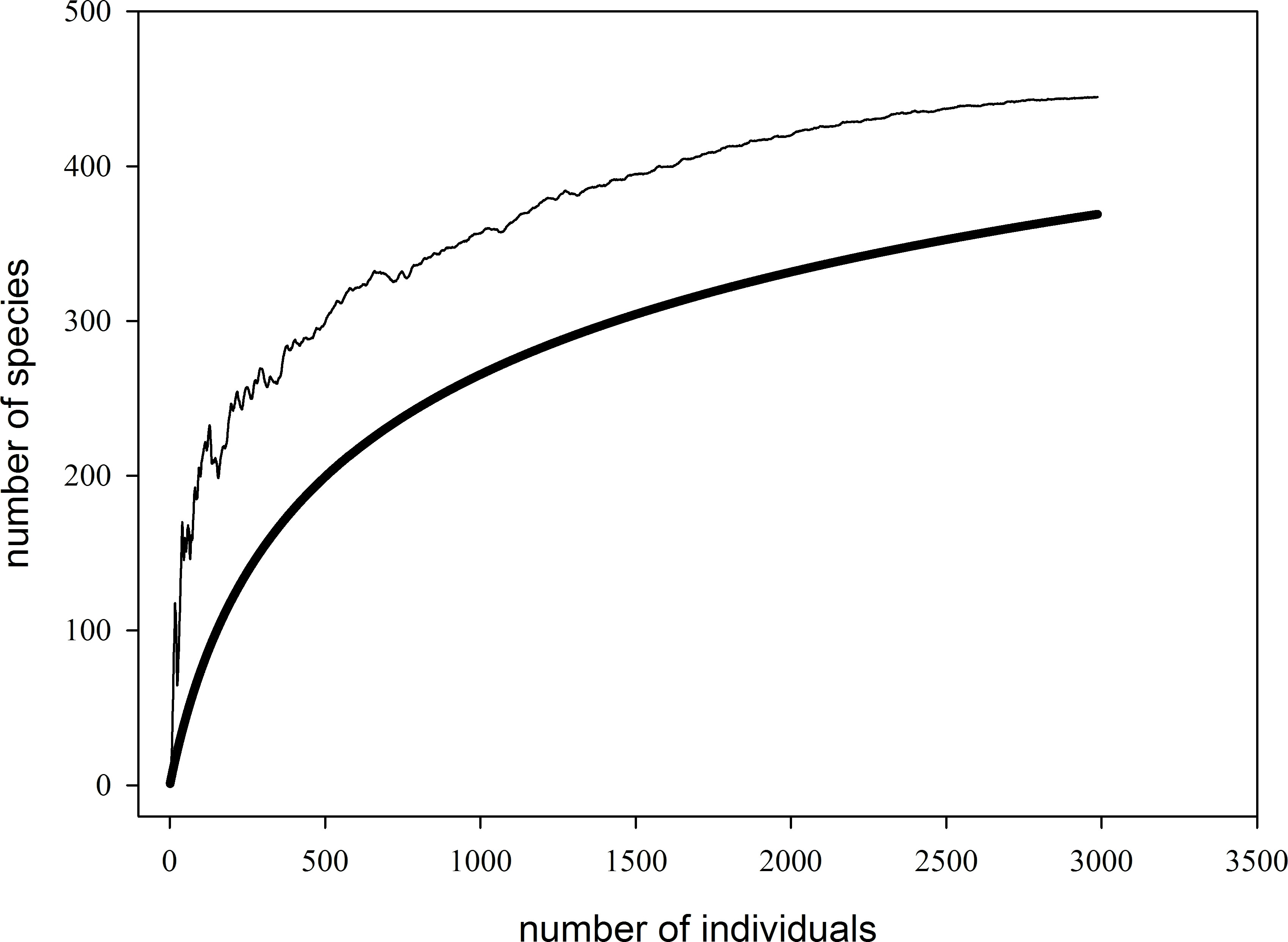
细线被期望丰富- Chao1。在R中,我只能绘制SAC。在EstimateS中,我得到了所有2990个人的数据集,但在R中没有。
回答 1
Stack Overflow用户
发布于 2016-11-28 14:02:26
我不知道在estimateS中是如何做到的,但看起来扩展丰富度(Chao 1)曲线是基于社区随机子样本的平均值的。可以这样做:
subchao <- sapply(1:2990, function(i)
mean(sapply(1:100, function(...) estimateR(rrarefy(TR, i))[2,])))这将随机稀薄(rrarefy())到所有样本大小从1到2990,并从100个副本的平均数。这需要时间。
页面原文内容由Stack Overflow提供。腾讯云小微IT领域专用引擎提供翻译支持
原文链接:
https://stackoverflow.com/questions/40803261
复制相关文章
相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号