
使用fminsearch进行分布拟合
使用fminsearch进行分布拟合
提问于 2016-03-11 23:49:59
假设我在数组errors中保存了一组单变量数据。
我想将PDF与我观察到的数据分布相匹配。
我的PDF是在函数poissvmwalkpdf中定义的,其定义行如下所示:
function p = poissvmwalkpdf(theta, mu, kappa, xi)这里,theta是错误( errors中的值是实例的变量),而mu、kappa和xi是errors的参数,我希望使用最大似然估计来找到它们的最佳匹配值。此函数在给定的theta值处返回概率密度。
在所有这些情况下,我如何使用fminsearch为mu、kappa和xi找到最适合我观察到的errors的值?fminsearch文档没有明确说明这一点。文件中的任何一个例子都不是分布拟合的例子。
注意:教程这里清楚地描述了什么是分布拟合(与曲线拟合不同),但给出的示例不使用fminsearch。
回答 1
Stack Overflow用户
回答已采纳
发布于 2016-03-12 09:09:51
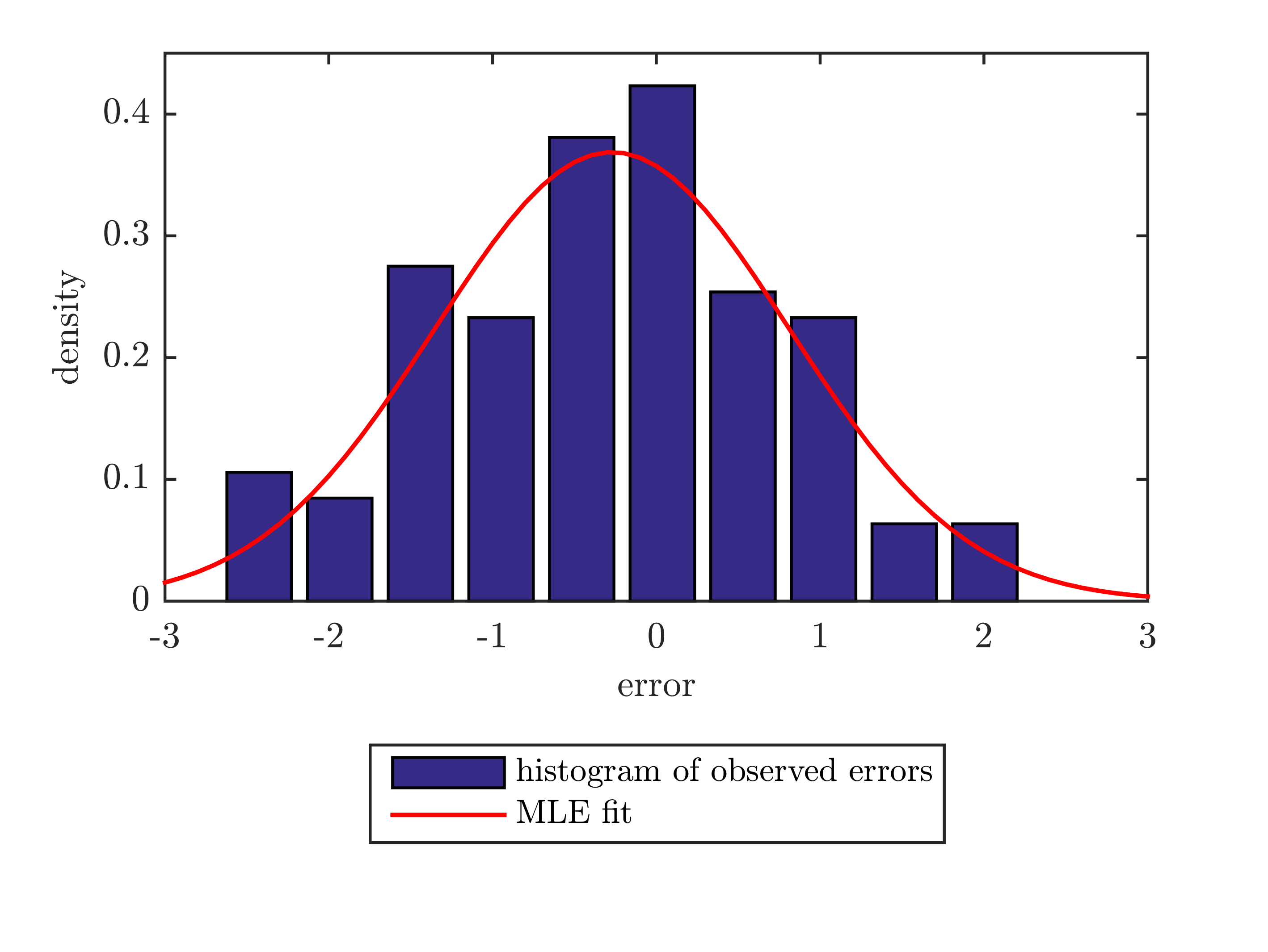
下面是一个使用fminsearch获取最大似然估计的最小示例(如注释中所要求的那样):
function mle_fit_minimal
n = 100;
% for reproducibility
rng(333)
% generate dummy data
errors = normrnd(0,1,n,1);
par0 = [1, 1];
[par_hat, nll] = fminsearch(@nloglike, par0)
% custom pdf
function p = my_pdf(data, par)
mu = par(1);
sigma = par(2);
p = normpdf(data, mu, sigma);
end
% negative loglikelihood function -- note that the parameters must be passed in a
% single argument (here called par).
function nll = nloglike(par)
nll = -sum(log(my_pdf(errors, par)));
end
end在建立了似然函数(或负对数似然)后,它只是一个简单的优化。
页面原文内容由Stack Overflow提供。腾讯云小微IT领域专用引擎提供翻译支持
原文链接:
https://stackoverflow.com/questions/35951934
复制相关文章
相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号