
如何独立于任何损失函数实现Softmax导数?
对于一个神经网络库,我实现了一些激活函数和损失函数及其导数。它们可以任意组合,输出层的导数只是损耗导数和激活导数的乘积。
然而,我未能独立于任何损失函数实现Softmax激活函数的导数。由于标准化,即方程中的分母,改变单个输入激活会改变所有的输出激活,而不仅仅是一个。
这是我的Softmax实现,其中导数在梯度检查中失败了约1%。如何实现Softmax导数,以便将其与任何损失函数结合起来?
import numpy as np
class Softmax:
def compute(self, incoming):
exps = np.exp(incoming)
return exps / exps.sum()
def delta(self, incoming, outgoing):
exps = np.exp(incoming)
others = exps.sum() - exps
return 1 / (2 + exps / others + others / exps)
activation = Softmax()
cost = SquaredError()
outgoing = activation.compute(incoming)
delta_output_layer = activation.delta(incoming) * cost.delta(outgoing)回答 5
Stack Overflow用户
发布于 2017-09-03 21:34:55
从数学上讲,Softmaxσ(j)关于logit的导数(例如,Wi*X)是
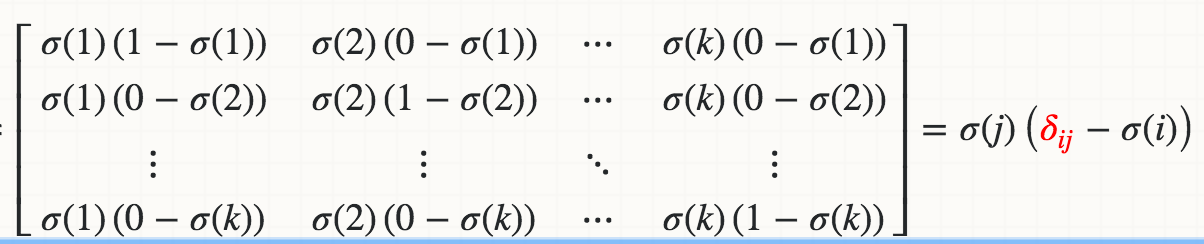
红色三角洲是Kronecker三角洲。
如果您迭代地实现:
def softmax_grad(s):
# input s is softmax value of the original input x. Its shape is (1,n)
# i.e. s = np.array([0.3,0.7]), x = np.array([0,1])
# make the matrix whose size is n^2.
jacobian_m = np.diag(s)
for i in range(len(jacobian_m)):
for j in range(len(jacobian_m)):
if i == j:
jacobian_m[i][j] = s[i] * (1 - s[i])
else:
jacobian_m[i][j] = -s[i] * s[j]
return jacobian_m测试:
In [95]: x
Out[95]: array([1, 2])
In [96]: softmax(x)
Out[96]: array([ 0.26894142, 0.73105858])
In [97]: softmax_grad(softmax(x))
Out[97]:
array([[ 0.19661193, -0.19661193],
[-0.19661193, 0.19661193]])如果您在向量化版本中实现:
soft_max = softmax(x)
# reshape softmax to 2d so np.dot gives matrix multiplication
def softmax_grad(softmax):
s = softmax.reshape(-1,1)
return np.diagflat(s) - np.dot(s, s.T)
softmax_grad(soft_max)
#array([[ 0.19661193, -0.19661193],
# [-0.19661193, 0.19661193]])Stack Overflow用户
发布于 2015-11-07 08:15:30
应该是这样的:(x是softmax层的输入,dy是上面损失的增量)。
dx = y * dy
s = dx.sum(axis=dx.ndim - 1, keepdims=True)
dx -= y * s
return dx但是,计算错误的方式应该是:
yact = activation.compute(x)
ycost = cost.compute(yact)
dsoftmax = activation.delta(x, cost.delta(yact, ycost, ytrue)) 说明:因为delta函数是反向传播算法的一部分,它的职责是将向量dy (在我的代码中是outgoing )乘以compute(x)函数在x上的雅可比值。如果你计算出这个Jacobian对于softmax 1是什么样子,然后用向量dy从左边乘以它,经过一些代数,你会发现你得到了与我的Python代码相对应的东西。
Stack Overflow用户
发布于 2021-04-17 06:00:51
其他答案是很好的,在这里可以共享forward/backward的一个简单实现,而不管失去什么函数。
在下面的图像中,它是对softmax的backward的一个简短的推导。第二个方程是与损失函数有关的,不是我们实现的一部分。
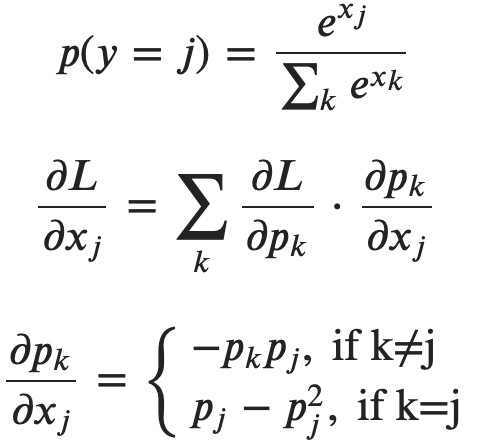
backward的验证通过手工的梯度检查。
import numpy as np
class Softmax:
def forward(self, x):
mx = np.max(x, axis=1, keepdims=True)
x = x - mx # log-sum-exp trick
e = np.exp(x)
probs = e / np.sum(np.exp(x), axis=1, keepdims=True)
return probs
def backward(self, x, probs, bp_err):
dim = x.shape[1]
output = np.empty(x.shape)
for j in range(dim):
d_prob_over_xj = - (probs * probs[:,[j]]) # i.e. prob_k * prob_j, no matter k==j or not
d_prob_over_xj[:,j] += probs[:,j] # i.e. when k==j, +prob_j
output[:,j] = np.sum(bp_err * d_prob_over_xj, axis=1)
return output
def compute_manual_grads(x, pred_fn):
eps = 1e-3
batch_size, dim = x.shape
grads = np.empty(x.shape)
for i in range(batch_size):
for j in range(dim):
x[i,j] += eps
y1 = pred_fn(x)
x[i,j] -= 2*eps
y2 = pred_fn(x)
grads[i,j] = (y1 - y2) / (2*eps)
x[i,j] += eps
return grads
def loss_fn(probs, ys, loss_type):
batch_size = probs.shape[0]
# dummy mse
if loss_type=="mse":
loss = np.sum((np.take_along_axis(probs, ys.reshape(-1,1), axis=1) - 1)**2) / batch_size
values = 2 * (np.take_along_axis(probs, ys.reshape(-1,1), axis=1) - 1) / batch_size
# cross ent
if loss_type=="xent":
loss = - np.sum( np.take_along_axis(np.log(probs), ys.reshape(-1,1), axis=1) ) / batch_size
values = -1 / np.take_along_axis(probs, ys.reshape(-1,1), axis=1) / batch_size
err = np.zeros(probs.shape)
np.put_along_axis(err, ys.reshape(-1,1), values, axis=1)
return loss, err
if __name__ == "__main__":
batch_size = 10
dim = 5
x = np.random.rand(batch_size, dim)
ys = np.random.randint(0, dim, batch_size)
for loss_type in ["mse", "xent"]:
S = Softmax()
probs = S.forward(x)
loss, bp_err = loss_fn(probs, ys, loss_type)
grads = S.backward(x, probs, bp_err)
def pred_fn(x, ys):
pred = S.forward(x)
loss, err = loss_fn(pred, ys, loss_type)
return loss
manual_grads = compute_manual_grads(x, lambda x: pred_fn(x, ys))
# compare both grads
print(f"loss_type = {loss_type}, grad diff = {np.sum((grads - manual_grads)**2) / batch_size}")https://stackoverflow.com/questions/33541930
复制相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号