
MKL是否为主要订单优化cblas?
我正在使用mkl cblas_dgemm,目前它与CblasRowMajor、CblasNoTrans、CblasNotrans一起用于我的矩阵。
我知道c是一种主要的行语言,而dgemm是一种主要的列算法。我很想知道,如果我链接到cblas_dgemm,那么切换矩阵的顺序是否会对mkl算法产生任何影响。mkl是否足够聪明,能够在幕后做一些我想做的事情来优化矩阵乘法?如果没有,用mkl执行矩阵乘法的最佳方法是什么?
回答 1
Stack Overflow用户
发布于 2015-09-13 13:03:02
TL;DR:简而言之,使用MKL (和其他BLAS实现)使用行主序或列主序来执行矩阵矩阵乘法并不重要。
我知道c是行的主要语言,而dgemm是列的主要算法。
DGEMM是而非的一种列主要算法,它是计算具有一般矩阵的矩阵积的BLAS接口.DGEMM (和大多数BLAS)的通用参考实现是用Fortran编写的Netlib's。它假定列-主要排序的唯一原因是因为Fortran是一种列-主要顺序语言。DGEMM (以及相应的BLAS第3级函数)是,而不是,专门用于列主数据。
DGEMM计算什么?
基础数学中的DGEMM执行一个2D 矩阵-矩阵乘法。标准
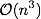
相乘2D矩阵的算法要求您沿着其行遍历一个矩阵,沿着其列遍历另一个矩阵。为了执行矩阵-矩阵乘法,AB = C,我们将A的行乘以B的列,生成CE 220。因此,输入矩阵的顺序并不重要,因为一个矩阵必须沿其行遍历,另一个必须沿着其列遍历。
用MKL研究行和列的DGEMM计算
Intel MKL非常聪明地利用了这一点,并为行主数据和列主数据提供了完全相同的性能。
cblas_dgemm(CblasRowMajor, CblasNoTrans, CblasNoTrans, ...);和
cblas_dgemm(CblasColMajor, CblasNoTrans, CblasNoTrans, ...);将以类似的性能执行。我们可以用一个相对简单的程序来测试这个
#include <float.h>
#include <mkl.h>
#include <omp.h>
#include <stdio.h>
void init_matrix(double *A, int n, int m, double d);
void test_dgemm(CBLAS_LAYOUT Layout, double *A, double *B, double *C, const MKL_INT m, const MKL_INT n, const MKL_INT k, int nSamples, double *timing);
void print_summary(const MKL_INT m, const MKL_INT n, const MKL_INT k, const int nSamples, const double *timing);
int main(int argc, char **argv) {
MKL_INT n, k, m;
double *a, *b, *c;
double *timing;
int nSamples = 1;
if (argc != 5){
fprintf(stderr, "Error: Wrong number of arguments!\n");
fprintf(stderr, "usage: %s mMatrix nMatrix kMatrix NSamples\n", argv[0]);
return -1;
}
m = atoi(argv[1]);
n = atoi(argv[2]);
k = atoi(argv[3]);
nSamples = atoi(argv[4]);
timing = malloc(nSamples * sizeof *timing);
a = mkl_malloc(m*k * sizeof *a, 64);
b = mkl_malloc(k*n * sizeof *a, 64);
c = mkl_calloc(m*n, sizeof *a, 64);
/** ROW-MAJOR ORDERING **/
test_dgemm(CblasRowMajor, a, b, c, m, n, k, nSamples, timing);
/** COLUMN-MAJOR ORDERING **/
test_dgemm(CblasColMajor, a, b, c, m, n, k, nSamples, timing);
mkl_free(a);
mkl_free(b);
mkl_free(c);
free(timing);
}
void init_matrix(double *A, int n, int m, double d) {
int i, j;
#pragma omp for schedule (static) private(i,j)
for (i = 0; i < n; ++i) {
for (j = 0; j < m; ++j) {
A[j + i*n] = d * (double) ((i - j) / n);
}
}
}
void test_dgemm(CBLAS_LAYOUT Layout, double *A, double *B, double *C, const MKL_INT m, const MKL_INT n, const MKL_INT k, int nSamples, double *timing) {
int i;
MKL_INT lda = m, ldb = k, ldc = m;
double alpha = 1.0, beta = 0.0;
if (CblasRowMajor == Layout) {
printf("\n*****ROW-MAJOR ORDERING*****\n\n");
} else if (CblasColMajor == Layout) {
printf("\n*****COLUMN-MAJOR ORDERING*****\n\n");
}
init_matrix(A, m, k, 0.5);
init_matrix(B, k, n, 0.75);
init_matrix(C, m, n, 0);
// First call performs any buffer/thread initialisation
cblas_dgemm(Layout, CblasNoTrans, CblasNoTrans, m, n, k, alpha, A, lda, B, ldb, beta, C, ldc);
double tmin = DBL_MAX, tmax = 0.0;
for (i = 0; i < nSamples; ++i) {
init_matrix(A, m, k, 0.5);
init_matrix(B, k, n, 0.75);
init_matrix(C, m, n, 0);
timing[i] = dsecnd();
cblas_dgemm(Layout, CblasNoTrans, CblasNoTrans, m, n, k, alpha, A, lda, B, ldb, beta, C, ldc);
timing[i] = dsecnd() - timing[i];
if (tmin > timing[i]) tmin = timing[i];
else if (tmax < timing[i]) tmax = timing[i];
}
print_summary(m, n, k, nSamples, timing);
}
void print_summary(const MKL_INT m, const MKL_INT n, const MKL_INT k, const int nSamples, const double *timing) {
int i;
double tavg = 0.0;
for(i = 0; i < nSamples; i++) {
tavg += timing[i];
}
tavg /= nSamples;
printf("#Loop | Sizes m n k | Time (s)\n");
for(i = 0; i < nSamples; i++) {
printf("%4d %12d %3d %3d %6.4f\n", i + 1 , m, n, k, timing[i]);
}
printf("Summary:\n");
printf("Sizes m n k | Avg. Time (s)\n");
printf(" %8d %3d %3d %12.8f\n", m, n, k, tavg);
}在我的系统中这会产生
$ ./benchmark_dgemm 1000 1000 1000 5
*****ROW-MAJOR ORDERING*****
#Loop | Sizes m n k | Time (s)
1 1000 1000 1000 0.0589
2 1000 1000 1000 0.0596
3 1000 1000 1000 0.0603
4 1000 1000 1000 0.0626
5 1000 1000 1000 0.0584
Summary:
Sizes m n k | Avg. Time (s)
1000 1000 1000 0.05995692
*****COLUMN-MAJOR ORDERING*****
#Loop | Sizes m n k | Time (s)
1 1000 1000 1000 0.0597
2 1000 1000 1000 0.0610
3 1000 1000 1000 0.0581
4 1000 1000 1000 0.0594
5 1000 1000 1000 0.0596
Summary:
Sizes m n k | Avg. Time (s)
1000 1000 1000 0.05955171我们可以看到,列-主排序时间和行-主要排序时间之间的差别很小。0.0595秒表示列大调,而0.0599秒表示行主.再次执行此操作可能会产生以下结果,其中行主计算比0.00003秒更快。
$ ./benchmark_dgemm 1000 1000 1000 5
*****ROW-MAJOR ORDERING*****
#Loop | Sizes m n k | Time (s)
1 1000 1000 1000 0.0674
2 1000 1000 1000 0.0598
3 1000 1000 1000 0.0595
4 1000 1000 1000 0.0587
5 1000 1000 1000 0.0584
Summary:
Sizes m n k | Avg. Time (s)
1000 1000 1000 0.06075310
*****COLUMN-MAJOR ORDERING*****
#Loop | Sizes m n k | Time (s)
1 1000 1000 1000 0.0634
2 1000 1000 1000 0.0596
3 1000 1000 1000 0.0582
4 1000 1000 1000 0.0582
5 1000 1000 1000 0.0645
Summary:
Sizes m n k | Avg. Time (s)
1000 1000 1000 0.06078266https://stackoverflow.com/questions/32445741
复制相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号