
μ算法的实现
μ算法的实现
提问于 2014-07-21 11:17:39
这是从NAudio摘录的Mu-Law编码器。问题是,这个公式与代码是如何相同的?我可以理解,MuLawCompressTable实际上是日志,但我不明白尾数为什么被视为原样。
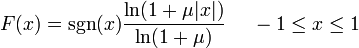
private const int cBias = 0x84;
private const int cClip = 32635;
private static readonly byte[] MuLawCompressTable = new byte[256]
{
0,0,1,1,2,2,2,2,3,3,3,3,3,3,3,3,
4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,
5,5,5,5,5,5,5,5,5,5,5,5,5,5,5,5,
5,5,5,5,5,5,5,5,5,5,5,5,5,5,5,5,
6,6,6,6,6,6,6,6,6,6,6,6,6,6,6,6,
6,6,6,6,6,6,6,6,6,6,6,6,6,6,6,6,
6,6,6,6,6,6,6,6,6,6,6,6,6,6,6,6,
6,6,6,6,6,6,6,6,6,6,6,6,6,6,6,6,
7,7,7,7,7,7,7,7,7,7,7,7,7,7,7,7,
7,7,7,7,7,7,7,7,7,7,7,7,7,7,7,7,
7,7,7,7,7,7,7,7,7,7,7,7,7,7,7,7,
7,7,7,7,7,7,7,7,7,7,7,7,7,7,7,7,
7,7,7,7,7,7,7,7,7,7,7,7,7,7,7,7,
7,7,7,7,7,7,7,7,7,7,7,7,7,7,7,7,
7,7,7,7,7,7,7,7,7,7,7,7,7,7,7,7,
7,7,7,7,7,7,7,7,7,7,7,7,7,7,7,7
};
public static byte LinearToMuLawSample(short sample)
{
//We get the sign
int sign = (sample >> 8) & 0x80;
if (sign != 0)
sample = (short)-sample;
if (sample > cClip)
sample = cClip;
sample = (short)(sample + cBias);
int exponent = (int)MuLawCompressTable[(sample >> 7) & 0xFF];
int mantissa = (sample >> (exponent + 3)) & 0x0F;
int compressedByte = ~(sign | (exponent << 4) | mantissa);
return (byte)compressedByte;
}回答 1
Stack Overflow用户
回答已采纳
发布于 2014-07-21 16:42:31
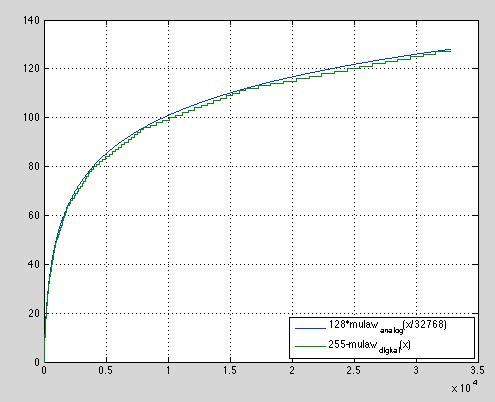
它们是不同的。看维基百科上的mu页面,http://en.wikipedia.org/wiki/Mulaw
这种算法有两种形式--模拟版本和量化数字版本。
您引用了“模拟”版本的公式--从-1.1到-1.1的压缩映射,这强调了mu-law的基本思想,即量化值对较小的值编码更详细的内容(使用较小的量化步骤),因此引入的量化误差与信号的总振幅大致成正比。
“数字”版本是对这一基本思想的分段线性近似,有一些额外的转移,以进一步简化处理。
下面是一个比较这两个人的图表。您可以看到绿色线(mu_digital)中对应于离散7位值的楼梯,您还可以看到近似光滑蓝线的不同的线性段。
页面原文内容由Stack Overflow提供。腾讯云小微IT领域专用引擎提供翻译支持
原文链接:
https://stackoverflow.com/questions/24863770
复制相关文章
相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号