
从长到宽,合并买卖数据的交易
我有买卖交易的长格式,我想把它转换为宽格式。看看例子:
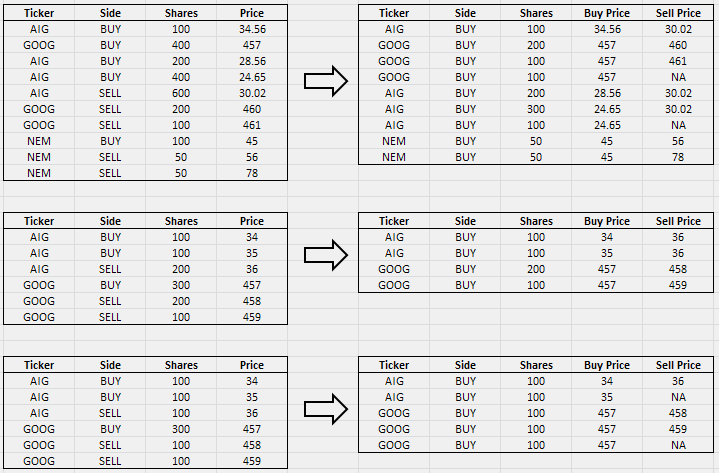
对于每一个买入交易的一些股票必须存在,出售交易相同的股票,关闭的立场。如果卖出交易不存在或股票计数变为零,则将NA置于卖出价格。
解释:
我们以34.56美元的价格购买了100股AIG股票。接下来,我们必须找到出口(卖出)交易,购买交易相同的股票,美国国际集团。这一交易存在于600股以下。因此,我们以100股完成了AIG的购买交易,将卖出交易的股票从600股降至500股,并以买入价格和卖出价格以宽格式进行交易。
下一笔交易是GOOG。对于这个股票,我们找到了两个卖出交易,并将它们全部写成宽格式,但100股未售出,所以我们把这笔交易作为“未完成”的交易,以NA作为卖出价格。
如果有必要的话,我以后可以把算法放进伪码中。但我希望我的解释是清楚的。
我的问题是:在R中使用干净和矢量化的代码很容易做到这一点?这个算法非常容易用命令式范式语言编程,比如C++。但对于R,我有麻烦。
编辑1:为R添加了输入和输出数据帧:
inputDF1 <- data.frame(Ticker = c("AIG", "GOOG", rep("AIG", 3), rep("GOOG", 2), rep("NEM", 3)), Side = c(rep("BUY", 4), rep("SELL", 3), "BUY", rep("SELL", 2)), Shares = c(100, 400, 200, 400, 600, 200, 100, 100, 50, 50), Price = c(34.56, 457, 28.56, 24.65, 30.02, 460, 461, 45, 56, 78))
inputDF2 <- data.frame(Ticker = c(rep("AIG", 3), rep("GOOG", 3)), Side = c(rep("BUY", 2), "SELL", "BUY", rep("SELL", 2)), Shares = c(100, 100, 200, 300, 200, 100), Price = c(34, 35, 36, 457, 458, 459))
inputDF3 <- data.frame(Ticker = c(rep("AIG", 3), rep("GOOG", 3)), Side = c(rep("BUY", 2), "SELL", "BUY", rep("SELL", 2)), Shares = c(100, 100, 100, 300, 100, 100), Price = c(34, 35, 36, 457, 458, 459))
outputDF1 <- data.frame(Ticker = c("AIG", rep("GOOG", 3), rep("AIG", 3), rep("NEM", 2)), Side = rep("BUY", 9), Shares = c(100, 200, 100, 100, 200, 300, 100, 50, 50), BuyPrice = c(34.56, 457, 457, 457, 28.56, 24.65, 24.65, 45, 45), SellPrice = c(30.02, 460, 461, NA, 30.02, 30.02, NA, 56, 78))
outputDF2 <- data.frame(Ticker = c(rep("AIG", 2), rep("GOOG", 2)), Side = rep("BUY", 4), Shares = c(100, 100, 200, 100), BuyPrice = c(34, 35, 457, 457), SellPrice = c(36, 36, 458, 459))
outputDF3 <- data.frame(Ticker = c(rep("AIG", 2), rep("GOOG", 3)), Side = rep("BUY", 5), Shares = rep(100, 5), BuyPrice = c(34, 35, rep(457, 3)), SellPrice = c(36, NA, 458, 459, NA))编辑2:更新示例和R的输入/输出数据
回答 2
Stack Overflow用户
发布于 2014-06-04 19:36:49
嗯,我在这个问题上花了太多时间!这是我的尝试(用data.table)。
由于您没有提到任何关于实际数据维度的内容,所以我无法进一步优化它。如果你能在你真实的数据集上运行这个,并把你的发现写回去,那就太好了(reg )。速度/比例)。
首先,我们将数据集拆分为Side,并执行join。这是最直接的方法。我还看到,@Mike.Gahan也尝试沿着这条路线前进。
require(data.table)
dt1 <- as.data.table(inputDF1)
d1 <- dt1[Side == "BUY"][, N := .N > 1L, by=Ticker]
d2 <- dt1[Side == "SELL"]
setkey(d2, Ticker)
ans = d2[d1, allow.cartesian=TRUE][, Side := NULL]请注意,
allow.cartesian不执行笛卡尔联接。这里用得很松。阅读?data.table以获得更多信息,或者查看this post关于它的用途。加入,基本上,将是非常快的,并将规模非常好。这并不是一个有限的步骤。
我们现在设置列顺序和相应的名称:
setcolorder(ans, c("Ticker", "Side.1", "Shares.1", "Shares", "Price.1", "Price", "N"))
setnames(ans, c("Ticker", "Side", "Shares", "tmp", "BuyPrice", "SellPrice", "N"))我们交换Shares和tmp,以便Shares根据N的值反映我们期望的实际输出,如下所示:
ans[, c("Shares", "tmp") := if (!N[1L])
{ val = Shares[1L]; list(tmp, val) }, by = Ticker]我们需要几个参数来聚合并获得最终结果:
ans[, `:=`(N2= rep(c(FALSE, TRUE), c(.N-1L, 1L)),
csum = sum(Shares)), by = Ticker][, N2 := !(N2 * (csum != tmp))]最后,
ans1 = ans[(N2)][, c("N", "N2", "tmp", "csum") := NULL]
ans2 = ans[!(N2)][, N := N * 1L]
if (nrow(ans2) > 0) {
ans2 = ans2[, list("BUY", if (N[1L]) c(Shares+tmp-csum, csum-tmp)
else c(Shares, tmp-csum), BuyPrice, c(SellPrice, NA)), by=Ticker]
}
ans = rbindlist(list(ans1, ans2))
# Ticker Side Shares BuyPrice SellPrice
# 1: AIG BUY 100 34.56 30.02
# 2: GOOG BUY 200 457.00 460.00
# 3: AIG BUY 200 28.56 30.02
# 4: NEM BUY 50 45.00 56.00
# 5: NEM BUY 50 45.00 78.00
# 6: GOOG BUY 100 457.00 461.00
# 7: GOOG BUY 100 457.00 NA
# 8: AIG BUY 300 24.65 30.02
# 9: AIG BUY 100 24.65 NA我猜这应该很快就会有足够的数量。但是,有可能进一步优化这一点。如果你选择以这个答案为基础,那我就留给你。
Stack Overflow用户
发布于 2014-06-01 15:31:36
原来的答案(当时这个问题还在开发中,我没有给予足够的关注)
使用来自dcast的reshape2:
> t <- c("AIG", "GOOG", "AIG", "AIG", "AIG", "GOOG", "GOOG")
> sd <- c(rep("BUY", 4), rep("SELL", 3))
> sh <- c(100, 400, 200, 400, 600, 200, 100)
> pr <- c(34.56, 457, 28.56, 24.65, 30.02, 460, 461)
> df <- data.frame(Ticker = t, Side = sd, Shares = sh, Price = pr)
>
> library(reshape2)
> df
Ticker Side Shares Price
1 AIG BUY 100 34.56
2 GOOG BUY 400 457.00
3 AIG BUY 200 28.56
4 AIG BUY 400 24.65
5 AIG SELL 600 30.02
6 GOOG SELL 200 460.00
7 GOOG SELL 100 461.00
> dcast(df, Ticker*Shares ~ Side, value.var="Price")
Ticker Shares BUY SELL
1 AIG 100 34.56 NA
2 AIG 200 28.56 NA
3 AIG 400 24.65 NA
4 AIG 600 NA 30.02
5 GOOG 100 NA 461.00
6 GOOG 200 NA 460.00
7 GOOG 400 457.00 NA新答案
这里的关键症结在于R中的“基于向量的”通常与" functional“(例如apply()家族)联系在一起,但是纯函数方法在这里并不完全有效,因为您必须更新每个(每个交易的一部分)的卖出列表。我真的觉得您可以用aggregate或by和精心设计的函数来做一些神奇的事情,但我想到的最好的可读性解决方案是一个简单的for-loop。
for版本
inputDF <- data.frame(Ticker = c("AIG", "GOOG", "AIG", "AIG", "AIG", "GOOG", "GOOG"),
Side = c(rep("BUY", 4), rep("SELL", 3)),
Shares = c(100, 400, 200, 400, 600, 200, 100),
Price = c(34.56, 457, 28.56, 24.65, 30.02, 460, 461))
buys <- subset(inputDF,Side=="BUY")
sells <- subset(inputDF,Side=="SELL")
transactions <- NULL
# go through every buy operation
for(i in 1:nrow(buys)){
ticker <- buys[i,"Ticker"]
bp <- buys[i,"Price"]
shares <- buys[i,"Shares"]
# keep going as long as we can find sellers
while(shares > 0 & sum(sells[sells$Ticker == ticker,"Shares"]) > 0){
sp <- sells[sells$Ticker == ticker & sells$Shares > 0,][1,"Price"]
if(sells[sells$Ticker == ticker & sells$Shares > 0,][1,"Shares"] > shares){
shares.sold <- shares
}else{
shares.sold <- sells[sells$Ticker == ticker & sells$Shares > 0,][1,"Shares"]
}
shares <- shares - shares.sold
sells[sells$Shares >= shares & sells$Ticker == ticker,][1,"Shares"] <- sells[sells$Shares >= shares & sells$Ticker == ticker,][1,"Shares"] - shares.sold
transactions <- rbind(transactions,data.frame("Ticker"=ticker
,"Side"="BUY"
,"Shares"=shares.sold
,"BuyPrice"=bp
,"SellPrice"=sp))
}
# not enough sellers
if(shares > 0){
transactions <- rbind(transactions,data.frame("Ticker"=ticker
,"Side"="BUY"
,"Shares"=shares
,"BuyPrice"=bp
,"SellPrice"="NA"))
}
}
print(transactions)输出:
Ticker Side Shares BuyPrice SellPrice
1 AIG BUY 100 34.56 30.02
2 GOOG BUY 200 457.00 460
3 GOOG BUY 100 457.00 461
4 GOOG BUY 100 457.00 NA
5 AIG BUY 200 28.56 30.02
6 AIG BUY 300 24.65 30.02
7 AIG BUY 100 24.65 NA如果我们尝试使用foreach包自动并行化循环,那么更新就很明显了。很快就可以看出,我们在sell数据帧上有一个竞争条件。
apply版本
上面的代码中有几个效率低下的地方,可以对其进行改进。通过rbind()进行的附加操作效率不高,而且可能会进行一些优化,要么减少对rbind()的调用,要么将其全部消除。您还可以将所有内容打包到一个函数中,并将其转换为对apply()的调用,即使对于串行apply(),这种调用也会更快,因为循环是在一个更优化的级别上完成的。(对于CPython也是如此-列表理解和str.join()比循环要快得多,因为它们“更清楚”操作的总大小,而且它们是用优化C编写的。)这里是第一次尝试--注意,我们使用do.call(rbind, list(...))简化了从最初对apply的调用中获得的小数据帧列表。这并不是非常有效(rbindlist从data.table获得的速度要快得多,参见here),但它没有任何外部依赖。从apply()中得到的列表实际上以自己的方式很有趣--每个元素都是完成整个购买操作所需的事务列表。如果将行名称添加到buys数据帧中,则可以按名称调用每一组事务。
inputDF <- data.frame(Ticker = c("AIG", "GOOG", "AIG", "AIG", "AIG", "GOOG", "GOOG"),
Side = c(rep("BUY", 4), rep("SELL", 3)),
Shares = c(100, 400, 200, 400, 600, 200, 100),
Price = c(34.56, 457, 28.56, 24.65, 30.02, 460, 461))
buys <- subset(inputDF,Side=="BUY")
sells <- subset(inputDF,Side=="SELL")
transactions <- NULL
# go through every buy operation
buy.operation <- function(x){
ticker <- x["Ticker"]
# apply() converts to matix implicity, and all the elements of a matrix have
# have the same data type, so everything gets converted to characters
# thus, we need to convert back
bp <- as.numeric(x["Price"])
shares <- as.numeric(x["Shares"])
# keep going as long as we can find sellers
while(shares > 0 & sum(sells[sells$Ticker == ticker,"Shares"]) > 0){
sp <- sells[sells$Ticker == ticker & sells$Shares > 0,][1,"Price"]
if(sells[sells$Ticker == ticker & sells$Shares > 0,][1,"Shares"] > shares){
shares.sold <- shares
}else{
shares.sold <- sells[sells$Ticker == ticker & sells$Shares > 0,][1,"Shares"]
}
shares <- shares - shares.sold
sells[sells$Shares >= shares & sells$Ticker == ticker,][1,"Shares"] <- sells[sells$Shares >= shares & sells$Ticker == ticker,][1,"Shares"] - shares.sold
transactions <- rbind(transactions,data.frame("Ticker"=ticker
,"Side"="BUY"
,"Shares"=shares.sold
,"BuyPrice"=bp
,"SellPrice"=sp))
}
# not enough sellers
if(shares > 0){
transactions <- rbind(transactions,data.frame("Ticker"=ticker
,"Side"="BUY"
,"Shares"=shares
,"BuyPrice"=bp
,"SellPrice"="NA"))
}
transactions
}
transactions <- do.call(rbind, apply(buys,1,buy.operation) )
# get rid of weird row names
row.names(transactions) <- NULL
print(transactions)输出:
Ticker Side Shares BuyPrice SellPrice
1 AIG BUY 100 34.56 30.02
2 GOOG BUY 200 457.00 460
3 GOOG BUY 100 457.00 461
4 GOOG BUY 100 457.00 NA
5 AIG BUY 200 28.56 30.02
6 AIG BUY 400 24.65 30.02不幸的是,美国国际集团最后一笔不完整的交易不见了。我还没想出怎么解决这个问题。
https://stackoverflow.com/questions/23981074
复制相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号