
如何更改NaiveBayesMultinomial中的分类阈值或在Weka中手动计算混淆矩阵
如何更改NaiveBayesMultinomial中的分类阈值或在Weka中手动计算混淆矩阵
提问于 2014-04-09 16:08:54
我正在做一个垃圾邮件过滤挖掘项目,我目前正在使用NaiveBayesMultinomial分类器,通过计数出现的单词频率,将垃圾邮件从非垃圾邮件中分类。
问题是,默认情况下,WEKA将分类阈值设置为0.5。然而,将非垃圾邮件错误分类为垃圾邮件比垃圾邮件更有害。
我想调整WEKA的NaiveBayesMultinomial算法的阈值,看看混淆矩阵是如何变化的。如果这是不可能的,我如何利用来自WEKA的输出来计算不同阈值的混淆矩阵?
下面是在测试拆分中评估项目当前结果的总结:
摘要:
Correctly Classified Instances 2715 98.4766 %
Incorrectly Classified Instances 42 1.5234 %
Kappa statistic 0.9679
Mean absolute error 0.0184
Root mean squared error 0.1136
Relative absolute error 3.8317 %
Root relative squared error 23.2509 %
Total Number of Instances 2757 `按类别划分的详细准确性:
TP Rate FP Rate Precision Recall F-Measure ROC Area Class
0.998 0.035 0.978 0.998 0.988 0.998 ham
0.965 0.002 0.996 0.965 0.98 0.999 spam
Weighted Avg. 0.985 0.022 0.985 0.985 0.985 0.998混淆矩阵:
a b <-- classified as
1669 4 | a = ham
38 1046 | b = spam回答 2
Stack Overflow用户
回答已采纳
发布于 2014-04-09 19:23:17
我在谷歌搜索过,而且似乎不太可能在WEKA中这样做。
但这仍然是可行的‘测试选项’->‘更多的选项’->‘输出预测’,然后它将给我的每个测试样本的可能性结果。
在那里,我可以使用另一个工具来完成剩下的工作。
Stack Overflow用户
发布于 2014-10-08 16:04:37
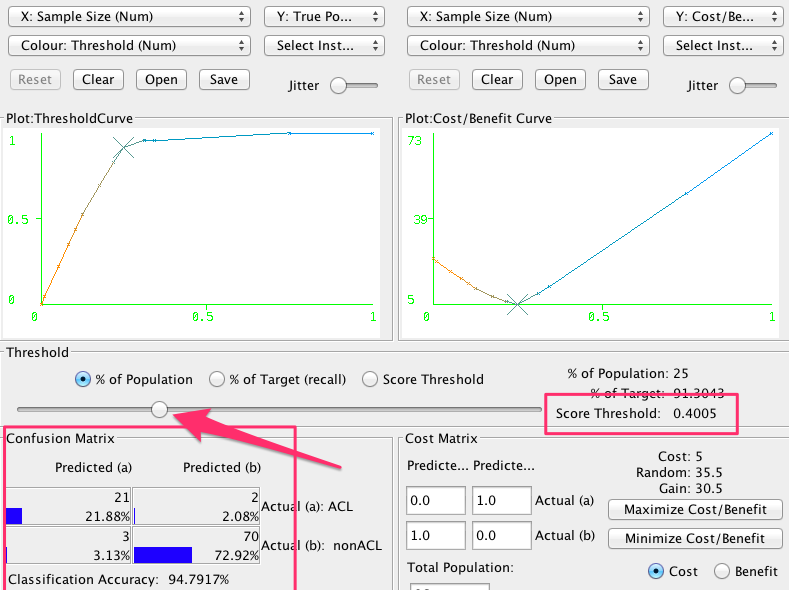
您可以在成本效益分析屏幕中更改它。右键单击结果列表中的结果,并选择可视化阈值曲线。
在里面有一个滑块来移动阈值,你的新混淆矩阵在左下角。
页面原文内容由Stack Overflow提供。腾讯云小微IT领域专用引擎提供翻译支持
原文链接:
https://stackoverflow.com/questions/22968151
复制相关文章
相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号