
在vDSP_ctoz加速框架中,iOS的数据应该是什么格式?
我正试图为iOS显示一个频谱分析仪,两周后我就被困住了。我已经阅读了几乎每一篇关于快速傅立叶变换和加速框架的文章,并从苹果下载了aurioTouch2示例。
我想我理解FFT的原理(20年前在Uni中这么做),并且是一个相当有经验的iOS程序员,但我遇到了困难。
我正在使用AudioUnit播放mp3、m4a和wav文件,并使其工作得很好。我已经附加了一个对AUGraph的渲染回调,我可以绘制音乐的波形。波形与音乐很好地吻合。
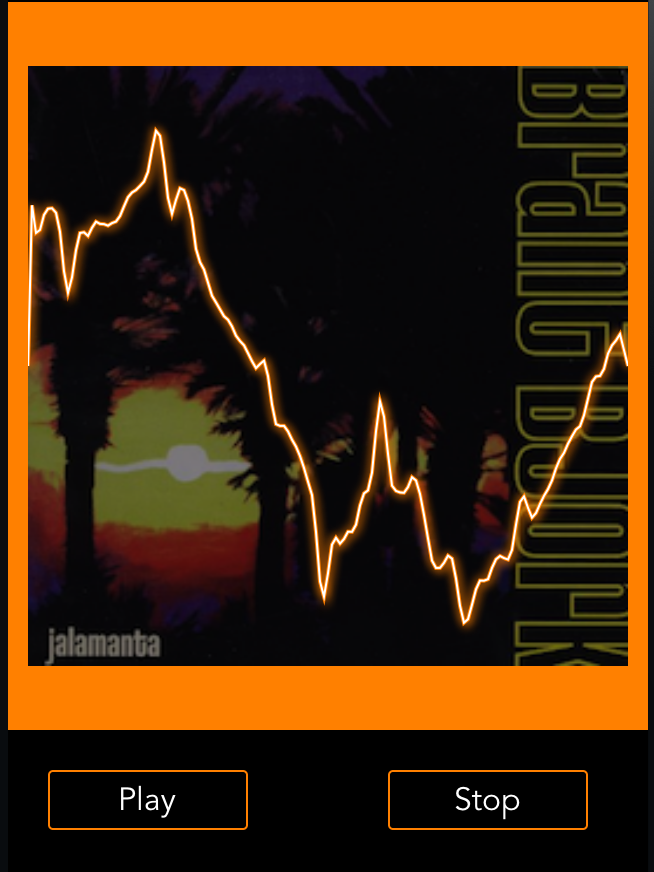
当我从呈现回调(在0范围内以浮动形式)获取数据时..并试图通过FFT代码(无论是我自己的还是aurioTouch2 2的FFTBufferManager.mm),我得到了一些不是完全错误的,但也是不正确的。或者,这是一个440 or的正弦波:

峰值是-6.1306,其次是-24。31. -35最终的价值大约是-63。
给“黑贝蒂”的动画礼物:
{kind=link}
从呈现回调中接收到的格式:
AudioStreamBasicDescription outputFileFormat;
outputFileFormat.mSampleRate = 44100;
outputFileFormat.mFormatID = kAudioFormatLinearPCM;
outputFileFormat.mFormatFlags = kAudioFormatFlagsNativeFloatPacked | kAudioFormatFlagIsNonInterleaved;
outputFileFormat.mBitsPerChannel = 32;
outputFileFormat.mChannelsPerFrame = 2;
outputFileFormat.mFramesPerPacket = 1;
outputFileFormat.mBytesPerFrame = outputFileFormat.mBitsPerChannel / 8;
outputFileFormat.mBytesPerPacket = outputFileFormat.mBytesPerFrame;在查看aurioTouch2示例时,看起来他们以签名的int格式接收数据,但随后运行AudioConverter将其转换为浮点数。它们的格式很难破译,但使用的是宏:
drawFormat.SetAUCanonical(2, false);
drawFormat.mSampleRate = 44100;
XThrowIfError(AudioConverterNew(&thruFormat, &drawFormat, &audioConverter), "couldn't setup AudioConverter");在呈现回调中,他们将数据从AudioBufferList复制到mAudioBuffer (Float32 32*),并将其传递给调用vDSP_ctoz的CalculateFFT方法
//Generate a split complex vector from the real data
vDSP_ctoz((COMPLEX *)mAudioBuffer, 2, &mDspSplitComplex, 1, mFFTLength);我想这就是我的问题所在。vDSP_ctoz所期望的格式是什么?它被转换为一个(复杂*),但我在aurioTouch2代码中找不到任何地方,它将mAudioBuffer数据转换为(复杂*)格式。所以必须是从这种格式的呈现回调来的吗?
typedef struct DSPComplex {
float real;
float imag;
} DSPComplex;
typedef DSPComplex COMPLEX;如果在这一点上没有正确的格式(或者理解格式),那么就没有必要调试它的其余部分。
任何帮助都将不胜感激。
我使用的来自AurioTouch2的代码:
Boolean FFTBufferManager::ComputeFFTFloat(Float32 *outFFTData)
{
if (HasNewAudioData())
{
// Added after Hotpaw2 comment.
UInt32 windowSize = mFFTLength;
Float32 *window = (float *) malloc(windowSize * sizeof(float));
memset(window, 0, windowSize * sizeof(float));
vDSP_hann_window(window, windowSize, 0);
vDSP_vmul( mAudioBuffer, 1, window, 1, mAudioBuffer, 1, mFFTLength);
// Added after Hotpaw2 comment.
DSPComplex *audioBufferComplex = new DSPComplex[mFFTLength];
for (int i=0; i < mFFTLength; i++)
{
audioBufferComplex[i].real = mAudioBuffer[i];
audioBufferComplex[i].imag = 0.0f;
}
//Generate a split complex vector from the real data
vDSP_ctoz((COMPLEX *)audioBufferComplex, 2, &mDspSplitComplex, 1, mFFTLength);
//Take the fft and scale appropriately
vDSP_fft_zrip(mSpectrumAnalysis, &mDspSplitComplex, 1, mLog2N, kFFTDirection_Forward);
vDSP_vsmul(mDspSplitComplex.realp, 1, &mFFTNormFactor, mDspSplitComplex.realp, 1, mFFTLength);
vDSP_vsmul(mDspSplitComplex.imagp, 1, &mFFTNormFactor, mDspSplitComplex.imagp, 1, mFFTLength);
//Zero out the nyquist value
mDspSplitComplex.imagp[0] = 0.0;
//Convert the fft data to dB
vDSP_zvmags(&mDspSplitComplex, 1, outFFTData, 1, mFFTLength);
//In order to avoid taking log10 of zero, an adjusting factor is added in to make the minimum value equal -128dB
vDSP_vsadd( outFFTData, 1, &mAdjust0DB, outFFTData, 1, mFFTLength);
Float32 one = 1;
vDSP_vdbcon(outFFTData, 1, &one, outFFTData, 1, mFFTLength, 0);
free( audioBufferComplex);
free( window);
OSAtomicDecrement32Barrier(&mHasAudioData);
OSAtomicIncrement32Barrier(&mNeedsAudioData);
mAudioBufferCurrentIndex = 0;
return true;
}
else if (mNeedsAudioData == 0)
OSAtomicIncrement32Barrier(&mNeedsAudioData);
return false;
}在阅读了下面的答案之后,我尝试将其添加到方法的顶部:
DSPComplex *audioBufferComplex = new DSPComplex[mFFTLength];
for (int i=0; i < mFFTLength; i++)
{
audioBufferComplex[i].real = mAudioBuffer[i];
audioBufferComplex[i].imag = 0.0f;
}
//Generate a split complex vector from the real data
vDSP_ctoz((COMPLEX *)audioBufferComplex, 2, &mDspSplitComplex, 1, mFFTLength);我得到的结果是:

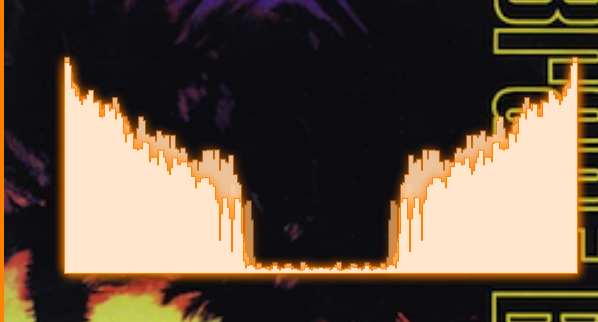
我现在呈现的最后5个结果,他们是褪色的落后。
添加hann窗口后:

现在在应用hann窗口后看起来好多了(谢谢hotpaw2)。不担心镜像。
我现在的主要问题是使用一首真正的歌曲,它看起来不像其他频谱分析器。无论是什么音乐,我总是把所有的东西都推到左边。涂上窗户后,它的节奏似乎要好得多。
回答 1
Stack Overflow用户
发布于 2014-03-24 02:46:34
AU呈现回调只返回所需复杂输入的真实部分。要使用复FFT,您需要自己填充相同数量的虚分量,并在需要时复制真实部分的元素。
https://stackoverflow.com/questions/22585341
复制相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号