
预测均值和标准差
很抱歉,这是一个简单的问题,但在过去的一周里,我没有找到任何答案,这让我发疯了。
背景信息:我有一个数据集,可以在5年内跟踪5个个体的体重。每年,我都有一个群体中个体权重的分布,从这个分布中,我计算了平均偏差和标准差。数据如下:
Year = [2002,2003,2004,2005,2006]
Weights_2002 = [12, 14, 16, 18, 20]
Weights_2003 = [14, 16, 18, 20,20]
Weights_2004 = [16, 18, 20, 22, 18]
Weights_2005 = [18, 21, 22, 22, 20]
Weights_2006 = [2, 21, 19, 20, 20]的问题:如何预测未来10年该小组的年度权重分布?理想情况下,我希望随着时间的推移,均值的不确定性会增加。同样,我也希望标准偏差的不确定性也会增加。另一种说法是,我想预测未来的权重分布,同时考虑到这两种情况:
- 数据的自然方差
- 增加了不确定性。
任何帮助都是非常非常感谢的。如果有人能建议如何在R中这样做,那就更好了。
谢谢你们!
回答 1
Stack Overflow用户
发布于 2014-03-23 22:32:00
缺乏关于如何在R中使用预测工具的具体建议,即。对你的问题的评论,这里是另一种使用蒙特卡罗模拟的方法。
首先,一些内部管理:2在Weights_2006中的值要么是一个错误,要么是一个异常值。因为我不知道是哪一个,我会假设它是一个离群点,并将它排除在分析之外。
第二,您说您希望基于increasing uncertainty构建发行版。但你的数据不支持这一点。
Year <- c(2002,2003,2004,2005,2006)
W2 <- c(12, 14, 16, 18, 20)
W3 <- c(14, 16, 18, 20,20)
W4 <- c(16, 18, 20, 22, 18)
W5 <- c(18, 21, 22, 22, 20)
W6 <- c(NA, 21, 19, 20, 20)
df <- rbind(W2,W3,W4,W5,W6)
df <- data.frame(Year,df)
library(reshape2) # for melt(...)
library(ggplot2)
data <- melt(df,id="Year", variable.name="Individual",value.name="Weight")
ggplot(data)+
geom_histogram(aes(x=Weight),binwidth=1,fill="lightgreen",colour="grey50")+
facet_grid(Year~.)
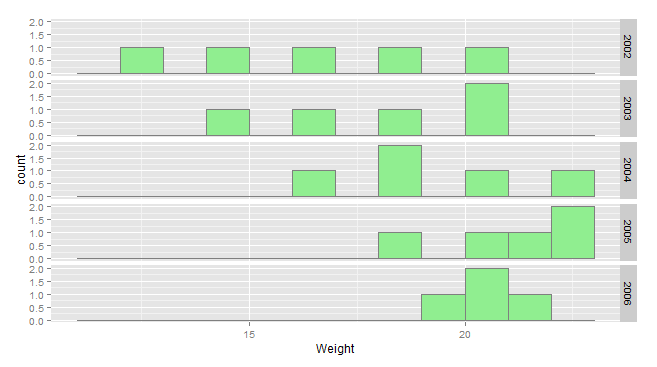
平均重量随着时间的推移而增加,但方差却在减小。看一看各个时间序列,就可以看出原因。
ggplot(data, aes(x=Year, y=Weight, color=Individual))+geom_line()
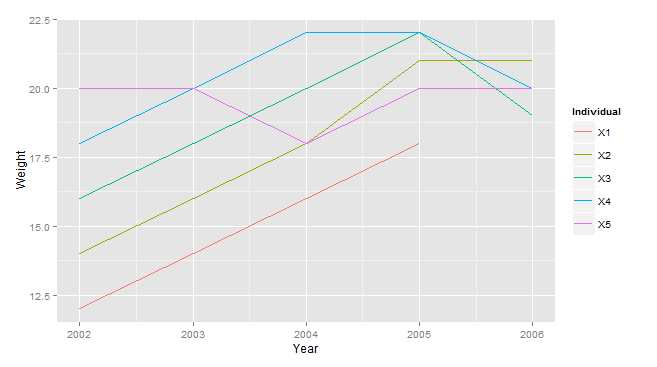
一般来说,一个人的体重随着时间而线性增加(大约每年2个单位),直到它达到20,当它停止增长,但波动。由于你的初始分布是均匀的,体重较低的个体会随着时间的推移而增加,从而推高平均体重。但体重较重的个体的体重停止增长。因此,分布会在20左右被“捆绑”,从而减少方差。我们可以从数字中看到这一点:不断增加的平均值,递减的标准差。
smry <- function(x)c(mean=mean(x),sd=sd(x))
aggregate(Weight~Year,data,smry)
# Year Weight.mean Weight.sd
# 1 2002 16.0000000 3.1622777
# 2 2003 17.6000000 2.6076810
# 3 2004 18.8000000 2.2803509
# 4 2005 20.6000000 1.6733201
# 5 2006 20.0000000 0.8164966我们可以用蒙特卡罗模拟来模拟这种行为。
set.seed(1)
start <- runif(1000,12,20)
X <- start
result <- X
for (i in 2003:2008){
X <- X + 2
X <- ifelse(X<20,X,20) +rnorm(length(X))
result <- rbind(result,X)
}
result <- data.frame(Year=2002:2008,result)在这个模型中,我们从1000个人开始,他们的体重在12到20之间形成一个均匀的分布,就像你们的数据一样。在每一时间步骤,我们增加了两个单位的重量。如果结果>20,我们将其剪裁为20,然后将随机噪声加为N0,1,现在我们可以绘制出这些分布。
model <- melt(result,id="Year",variable.name="Individual",value.name="Weight")
ggplot(model,aes(x=Weight))+
geom_histogram(aes(y=..density..),fill="lightgreen",colour="grey50",bins=20)+
stat_density(geom="line",colour="blue")+
geom_vline(data=aggregate(Weight~Year,model,mean), aes(xintercept=Weight), colour="red", size=2, linetype=2)+
facet_grid(Year~.,scales="free")
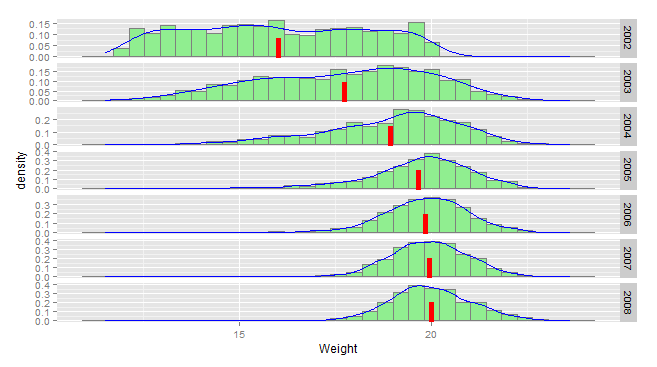
红条显示了每年的平均重量。
如果您认为个体的重量随时间的自然变化而增加,那么使用N[0,sigma]作为模型中的误差项,sigma随Year的增加而增加。问题是,您的数据中没有任何东西可以支持这一点。
https://stackoverflow.com/questions/22566350
复制相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号