
比较两个向量的FDR
我们给出了一个2列(样本、实验条件)和n行(例如基因)的矩阵,我们的目的是确定两个样本之间(在特定的FDR上)发生显著变化的基因。
如何使用R执行此操作?
下面是fdrtool包手册中的一个示例,它演示了如何从p值向量计算FDR:
library("fdrtool")
data(pvalues)
fdr = fdrtool(pvalues, statistic="pvalue")
fdr$qval # estimated Fdr values
fdr$lfdr # estimated local fdr但问题是,我们这里只有两个观测向量,而不是p值。有什么想法吗?
下面是可以使用的示例数据:foo <- matrix(runif(1000), ncol=2)
我想我们没有复制信息,p值等等,但是可以肯定的是,两个样本之间的基因值有很大的不同,确实有更有力的证据。在这种情况下,有什么办法分配FDR吗?
回答 1
Stack Overflow用户
发布于 2013-06-08 15:26:43
如果每种情况都有一个样本,就不可能有一个p值,因为这是为一个群体绘制的样本之间的差异在统计上不同的概率。但是,如果你没有复制,没有均值,没有变异,据我所知,我们不能估计采样误差,因此没有办法区分你所看到的值和随机值,对于小样本的常规测试,如t检验。听着,这可能会有帮助:
http://en.wikipedia.org/wiki/P-value
http://www-stat.stanford.edu/~tibs/SAM/
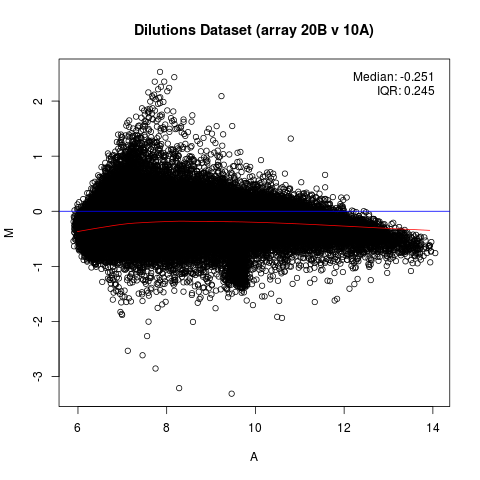
你能做的,是一个MA阴谋
plot
看看你的数据的分布,这是很大的差异,并选择那些。但是,这不是在统计框架中的错误发现率分析,它可能有助于作为一个探索性的分析,但没有真正的统计。在微阵列的文献中,你可能会找到其他的选择,做出一套假设,并进行假设检验,但我不知道有一个可以说明,也许这个小程序包有一个.
https://stackoverflow.com/questions/16998658
复制相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号