
为什么我在多元线性回归中的观察要比R中的数据行多?
为什么我在多元线性回归中的观察要比R中的数据行多?
提问于 2021-08-05 17:19:57
我在R中运行了一个MLR,以检查4个解释变量(温度、溶解氧、实际盐度和氧化还原电位)对1个响应变量(Shell圆度)的影响:
shell_round_mlr <- lm(Shell_Round ~ TempC + O2 + PSU + ORP, data = morph.na)所讨论的数据集(morph.na)具有53行数据。当我运行下面的代码来检查模型..。
par(mfrow = c(2,2))
plot(shell_round_mlr)我得到了这些情节:
残差与拟合值、正常Q-Q、标度位置、残差与杠杆:https://i.stack.imgur.com/Lkkmd.png
{kind=link}
它显示了观察#65和#159作为我可能想要删除的。然而,当我只有53行数据时,怎么可能有一个观察#159呢?,我已经三次检查我是否调用了正确的数据。
而且,在这种情况下,如果我想删除任何这些麻烦的观察,我将如何去做呢?它并不像从dataframe中删除一行那么简单。
如有任何建议,将不胜感激。谢谢。
回答 1
Stack Overflow用户
回答已采纳
发布于 2021-08-05 17:52:29
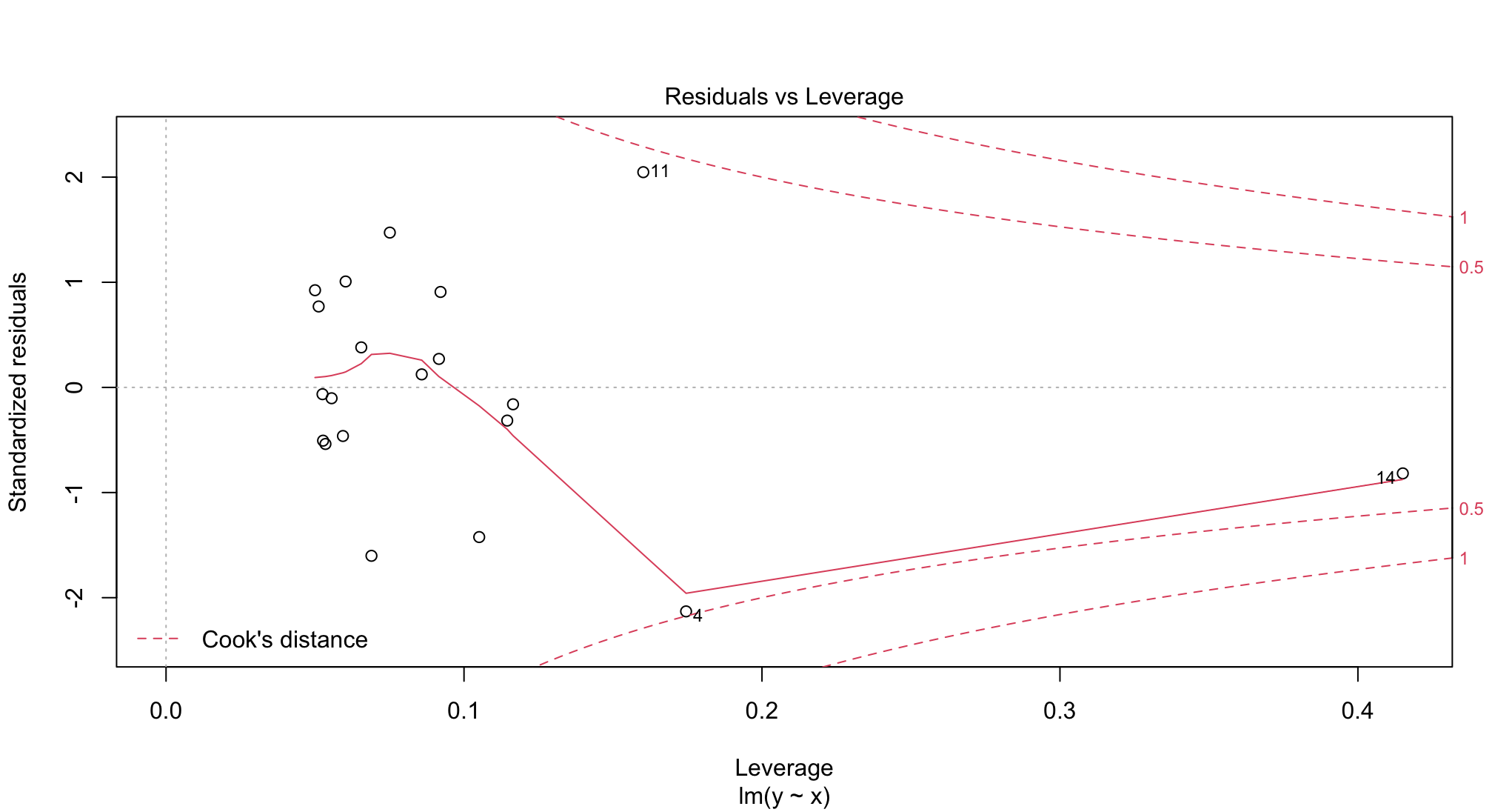
没有一个可重复的例子就很难诊断出你的问题。但正如@aosmith在一条评论中所指出的,plot将使用行索引进行标记。此示例显示lm图,其标号值高于总样本大小。
set.seed(1L)
df <- data.frame(x = rnorm(20), y = rnorm(20))
rownames(df) <- sample(50:70, 20)
fit <- lm(y ~ x, data = df)
plot(fit)
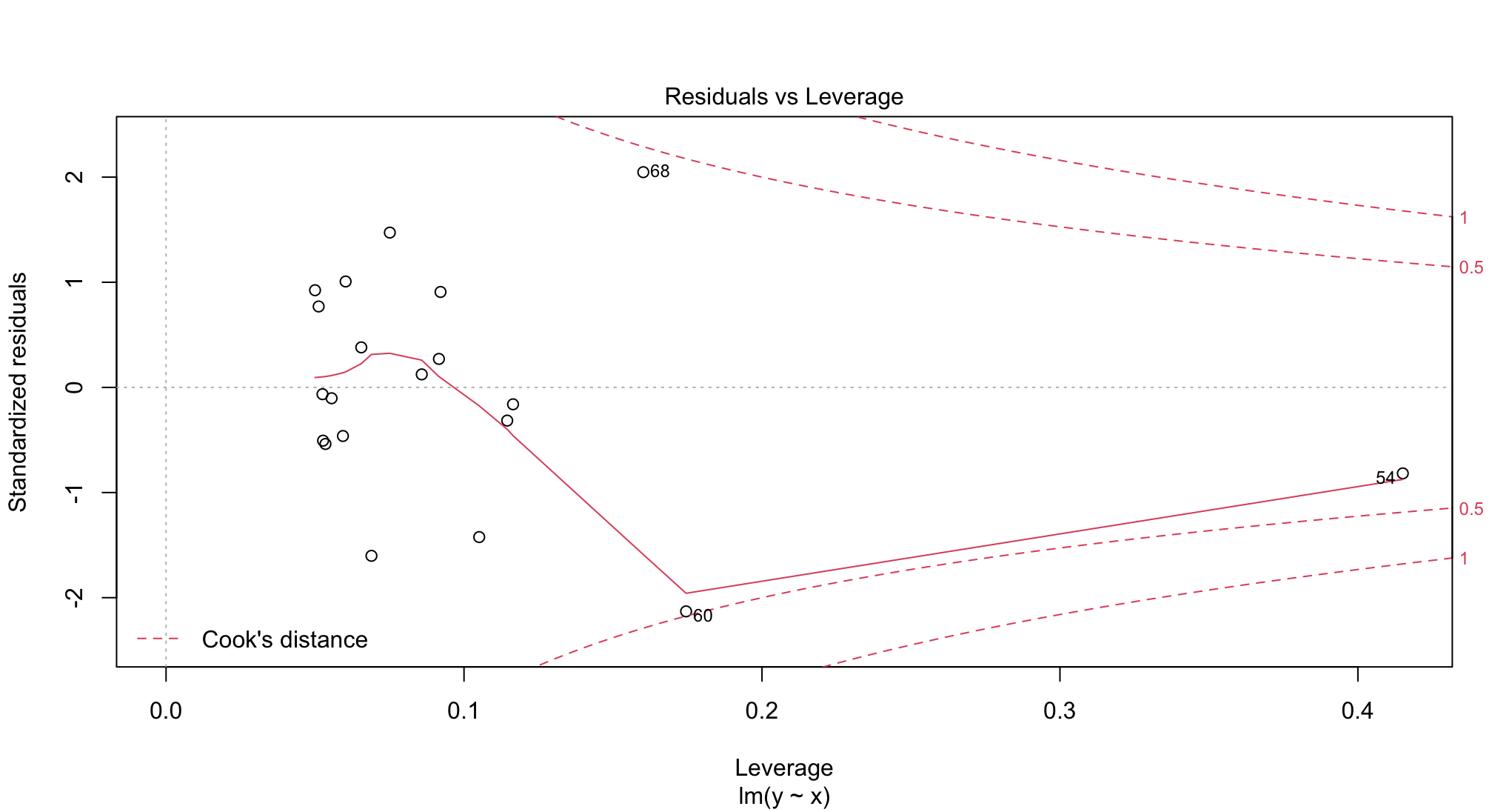
相比之下,下面是与labels.id = NULL相同的图
plot(fit, labels.id = NULL)
页面原文内容由Stack Overflow提供。腾讯云小微IT领域专用引擎提供翻译支持
原文链接:
https://stackoverflow.com/questions/68670973
复制相关文章
相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号