
对偶递归的lru_cache
对偶递归的lru_cache
提问于 2021-06-23 18:21:48
我理解没有回忆录的dfs的实现往往会很快超时,因为我们一次又一次地重新计算同样的事情。这是python中lru_cache的完美需求。例如:
from functools import lru_cache
@lru_cache
def fib(n):
if n <= 2:
return 1
else:
return fib(n - 2) + fib(n - 1)然而,我正在努力用lru_cache实现回忆录,以实现双重递归,但略有不同。当我将装饰lru_cache添加到代码中(其含义在下图Leetcode494中解释)时,它就会给出错误的结果。原因很简单,因为helper( cumsum+nums[i], i+1)和helper( cumsum-nums[i], i+1)做的事情不同。
from functools import lru_cache
class Solution:
def findTargetSumWays(self, nums: List[int], target: int) -> int:
# tree structure: two path "+" or "-"
# @lru_cache
def helper(cumsum, i):
nonlocal n
if i == len(nums) and cumsum == target:
n += 1
return n
if i == len(nums):
return
helper( cumsum+nums[i], i+1)
helper( cumsum-nums[i], i+1)
nums = tuple(nums)
n = 0
cumsum = 0
helper(cumsum, 0)
return n 在这种情况下,是否仍然可以使用lru_cache回溯中间结果?如果是的话,你能分享你的智慧吗?非常感谢。
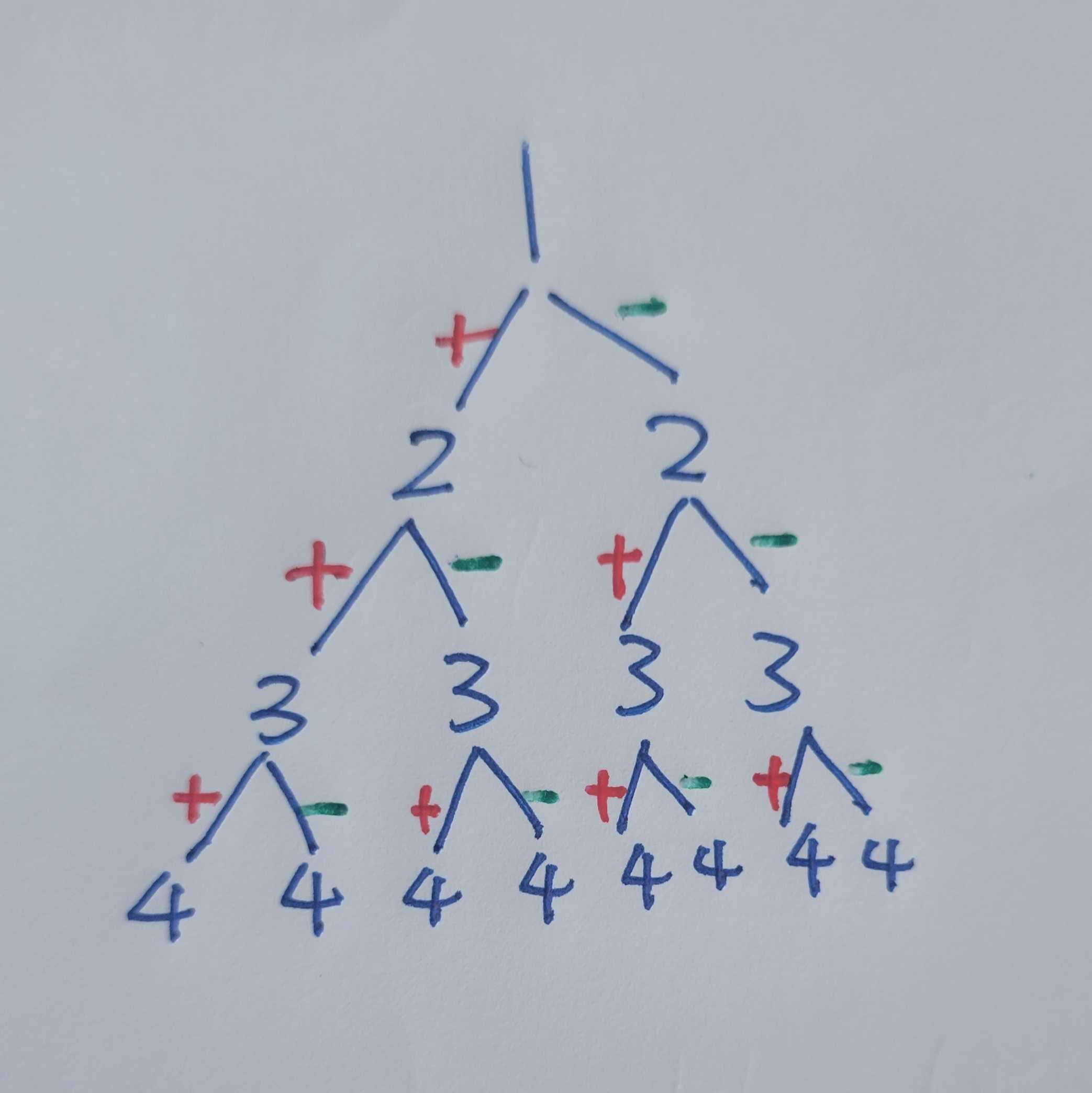
回答 1
Stack Overflow用户
发布于 2021-06-23 18:41:32
检查这种方法并比较不同之处。
from functools import lru_cache
class Solution:
def findTargetSumWays(self, a: List[int], S: int) -> int:
N = len(a)
@lru_cache(None)
def helper(i,S):
if i == N:
if S == 0:
return 1
else:
return 0
return helper(i+1,S + a[i]) + helper(i+1,S - a[i])
return helper(0,S)页面原文内容由Stack Overflow提供。腾讯云小微IT领域专用引擎提供翻译支持
原文链接:
https://stackoverflow.com/questions/68105280
复制相关文章
相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号