
变量在数据集中多次发生的概率。
变量在数据集中多次发生的概率。
提问于 2021-01-02 13:37:31
我正在处理一个数据集,大约有38.000条关于趋势YouTube视频的观测结果。一个特定的视频可以有多个观察;这意味着一个视频可以多次或超过一天的时间趋势。
以上是正确的,我们知道,但我正在设法计算一个视频被观察超过一次的概率在这个数据集中。P(X > 1)
请参阅我用barplot(head(table(df$video_id)))绘制的以下图像:
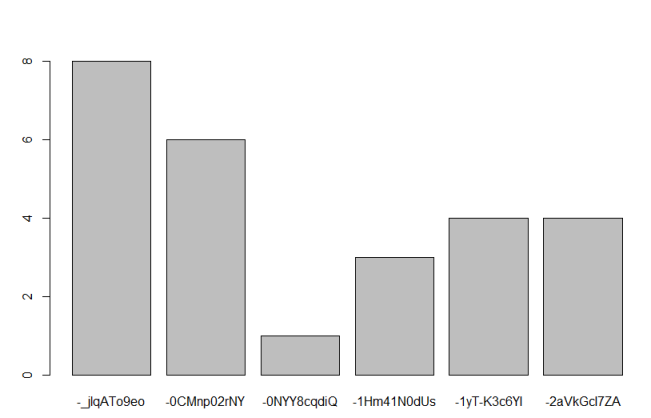
我们可以看出,在这6个视频中,有5个有超过一个的观察,相当于83.33%的概率。如何在整个数据集中计算出相同的数据集?虽然我不一定想把它形象化(这将是一个额外的收获),但我只是好奇如何计算在~38.000次观测中发生超过一次的video_id的概率。
下面是一个20个观察样本:https://pastebin.com/Tx9ebH2c
回答 1
Stack Overflow用户
回答已采纳
发布于 2021-01-02 18:19:14
你拥有你所需要的大部分:
tbl <- table(df$video_id)
p <- sum(tbl > 1)/length(tbl)
p
# [1] 0.5对于示例数据集,一半的视频不止一次发生。表的长度是不同视频的数量,除以这个值,你就可以得到超过一次观看视频的比例。你可以做一个简单的条形图来显示观看超过一次的视频相对于只看一次的视频的比例。
barplot(c(p, 1-p))页面原文内容由Stack Overflow提供。腾讯云小微IT领域专用引擎提供翻译支持
原文链接:
https://stackoverflow.com/questions/65539667
复制相关文章
相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号