
在R中复制这个地块
在R中复制这个地块
提问于 2020-12-20 23:36:13
我有两组病人。我想给两组病人画个图
就像这样的情节
我有这样的数据
> dput(df)
structure(list(gene = c("18q", "4q", "21p", "21q", "5q", "22q",
"17p", "3p", "9p", "4p", "9q", "19q", "10q", "15q", "16p", "19p",
"1p", "18p", "16q", "8p", "21q", "4q", "18q", "21p", "1p", "3p",
"4p", "17p", "5q", "16q", "18p", "14q", "19p", "20q"), CNV = c("Deletion",
"Deletion", "Deletion", "Deletion", "Deletion", "Deletion", "Deletion",
"Deletion", "Deletion", "Deletion", "Deletion", "Deletion", "Deletion",
"Deletion", "Deletion", "Deletion", "Deletion", "Deletion", "Deletion",
"Deletion", "Deletion", "Deletion", "Deletion", "Deletion", "Deletion",
"Deletion", "Deletion", "Deletion", "Deletion", "Deletion", "Deletion",
"Deletion", "Deletion", "Amplification"), log10_pvalue = c(5.974694135,
5.73754891, 4.995678626, 4.970616222, 4.793174124, 4.793174124,
4.109020403, 3.524328812, 3.524328812, 2.823908741, 2.567030709,
2.186419011, 1.769551079, 1.59345982, 1.59345982, 1.59345982,
1.416801226, 1.195860568, 1.094743951, 1.087777943, 4.083019953,
3.826813732, 3.826813732, 3.826813732, 2.675717545, 2.675717545,
2.675717545, 2.342944147, 2.084072788, 1.850780887, 1.659555885,
1.197226275, 1.197226275, 1.88941029), Percentage_altered = c(0.61,
0.53, 0.61, 0.56, 0.44, 0.5, 0.5, 0.44, 0.5, 0.47, 0.39, 0.28,
0.33, 0.31, 0.33, 0.31, 0.22, 0.36, 0.33, 0.33, 0.63, 0.52, 0.59,
0.67, 0.26, 0.44, 0.52, 0.48, 0.33, 0.44, 0.44, 0.3, 0.33, 0.5
), group = c("Non-responders", "Non-responders", "Non-responders",
"Non-responders", "Non-responders", "Non-responders", "Non-responders",
"Non-responders", "Non-responders", "Non-responders", "Non-responders",
"Non-responders", "Non-responders", "Non-responders", "Non-responders",
"Non-responders", "Non-responders", "Non-responders", "Non-responders",
"Non-responders", "Responders", "Responders", "Responders", "Responders",
"Responders", "Responders", "Responders", "Responders", "Responders",
"Responders", "Responders", "Responders", "Responders", "Responders"
)), class = "data.frame", row.names = c(NA, -34L))
>我试过这个代码,但没有给我你所做的。
df %>%
mutate(net_frequency=ifelse(CNV == "Deletion", -Percentage_altered/100, Percentage_altered/100)) %>%
crossing(., tibble(grp = c("Responders", "Non-Responders"))) %>%
mutate(log10_pvalue = if_else(CNV == "Deletion", -log10_pvalue, log10_pvalue)) %>%
ggplot(aes(x = log10_pvalue, y = net_frequency, color = log10_pvalue)) +
geom_point(aes(size=Percentage_altered)) +
geom_text_repel(aes(label=ifelse(log10_pvalue > -log10(0.05), gene, "")), force=10) +
geom_hline(yintercept=0, lty=2) +
scale_color_distiller(type = "div") +
theme_classic() +
facet_wrap(~grp)我得到了这样一个阴谋,但毫无意义。
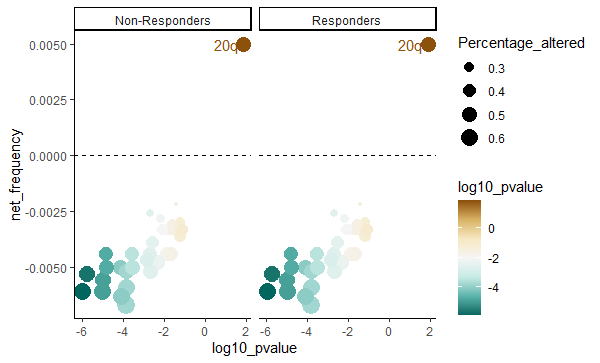
如果您查看,对于这两个组,只有响应者的信息正在绘制。
你能帮我编辑一下代码吗?
回答 1
Stack Overflow用户
发布于 2020-12-21 00:26:44
正如@andrew_reece所建议的,facet_*在这里会有所帮助。
由于我们在数据中没有"Responders“的任何概念,所以我将使用tidyr::crossing盲目地复制数据。
另外,为了演示起见,我删除了theme_classic以突出显示窗格。(使用它没有问题,我只是想说明两者之间的区别。)
library(dplyr)
library(ggplot2)
library(ggrepel) # geom_text_repel
library(tidyr) # crossing
df %>%
mutate(net_frequency=ifelse(CNV == "Deletion", -Percentage_altered/100, Percentage_altered/100)) %>%
crossing(. tibble(resp = c("Responder", "Non-Responder"))) %>%
ggplot(. aes(x=log10_pvalue, y=net_frequency)) +
geom_point(aes(size=Percentage_altered, color=log10_pvalue)) +
geom_text_repel(aes(label=ifelse(log10_pvalue > -log10(0.05), gene, "")), force=10) +
geom_hline(yintercept=0, lty=2) +
facet_wrap(. ~ resp)
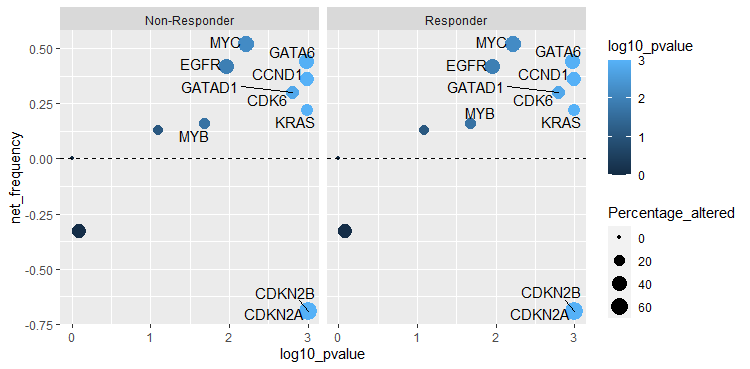
至于“两组不同的颜色”,你需要什么并不是很清楚。如果你想的话(例如)颜色标度对于响应者来说是“蓝色”,对于非响应者来说是“红色”,然后查看,比如ggnewscale或ggrelayer。(它们不是烘焙的。)
页面原文内容由Stack Overflow提供。腾讯云小微IT领域专用引擎提供翻译支持
原文链接:
https://stackoverflow.com/questions/65385887
复制相关文章
相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号