
获得完全量化的TfLite模型,并在int8上进行输入和输出
获得完全量化的TfLite模型,并在int8上进行输入和输出
提问于 2020-09-09 07:46:35
我用Tensorflow 1.15.3量化了一个Keras h5模型(Tf1.13;keras_vggface模型),以便与NPU一起使用它。我用于转换的代码是:
converter = tf.lite.TFLiteConverter.from_keras_model_file(saved_model_dir + modelname)
converter.optimizations = [tf.lite.Optimize.DEFAULT]
converter.representative_dataset = representative_dataset_gen
converter.target_spec.supported_ops = [tf.lite.OpsSet.TFLITE_BUILTINS_INT8]
converter.inference_input_type = tf.int8 # or tf.uint8
converter.inference_output_type = tf.int8 # or tf.uint8
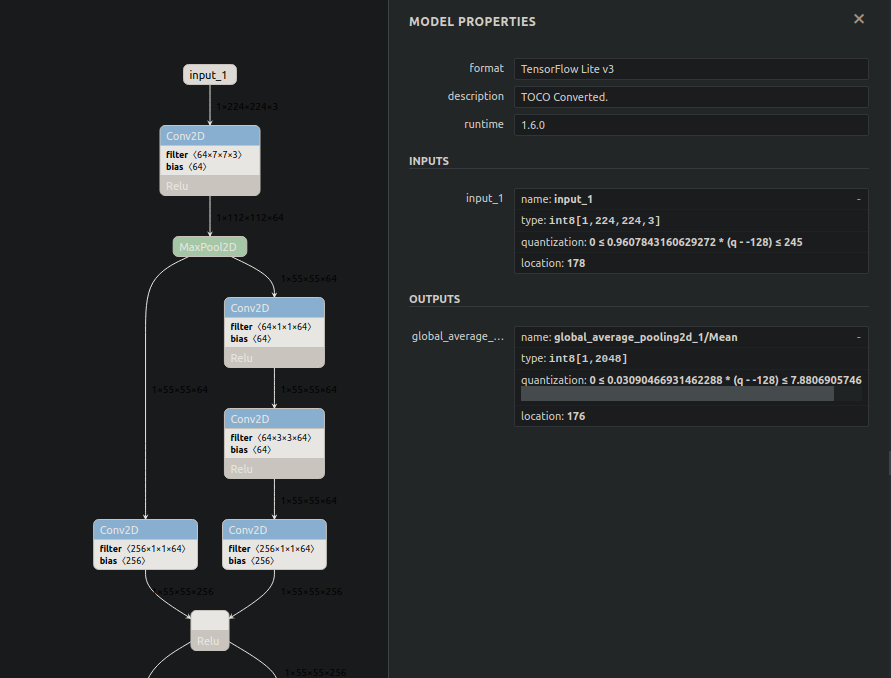
tflite_quant_model = converter.convert()我得到的量化模型一见钟情。输入层类型为int8,滤波器为int8,偏置为int32,输出为int8。
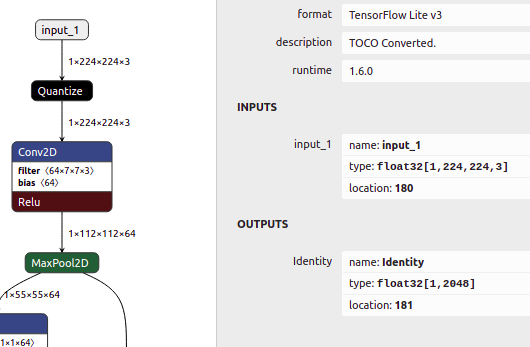
然而,模型在输入层之后有一个量化层,输入层是float32 (见下图)。但是,似乎NPU也需要输入为int8。
是否有一种没有转换层但也以int8作为输入的完全量化的方法?
正如您在上面看到的,我使用了:
converter.inference_input_type = tf.int8
converter.inference_output_type = tf.int8编辑
来自用户dtlam的解决方案
尽管模型仍然没有在google中运行,但是使用TF 1.15.3或TF2.2.0在int8中量化模型和输入输出的解决方案是,多亏了delan:
...
converter = tf.lite.TFLiteConverter.from_keras_model_file(saved_model_dir + modelname)
def representative_dataset_gen():
for _ in range(10):
pfad='pathtoimage/000001.jpg'
img=cv2.imread(pfad)
img = np.expand_dims(img,0).astype(np.float32)
# Get sample input data as a numpy array in a method of your choosing.
yield [img]
converter.representative_dataset = representative_dataset_gen
converter.optimizations = [tf.lite.Optimize.DEFAULT]
converter.representative_dataset = representative_dataset_gen
converter.target_spec.supported_ops = [tf.lite.OpsSet.TFLITE_BUILTINS_INT8]
converter.experimental_new_converter = True
converter.target_spec.supported_types = [tf.int8]
converter.inference_input_type = tf.int8
converter.inference_output_type = tf.int8
quantized_tflite_model = converter.convert()
if tf.__version__.startswith('1.'):
open("test153.tflite", "wb").write(quantized_tflite_model)
if tf.__version__.startswith('2.'):
with open("test220.tflite", 'wb') as f:
f.write(quantized_tflite_model)
回答 1
Stack Overflow用户
回答已采纳
发布于 2020-09-09 07:56:21
如果您应用培训后量化,您必须确保您的代表性数据集,而不是在float32。此外,如果您想使用int8或uint8输入/输出来量化模型,您应该考虑使用量化感知培训。这也给你更好的量化效果。
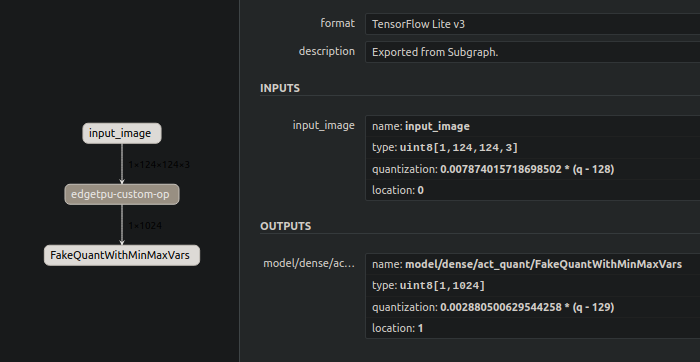
我还试着用你给我的图像和代码来量化你的模型,毕竟它是量化的。
页面原文内容由Stack Overflow提供。腾讯云小微IT领域专用引擎提供翻译支持
原文链接:
https://stackoverflow.com/questions/63806975
复制相关文章
相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号