
培训和验证LSTM问题:查全率和召回问题
培训和验证LSTM问题:查全率和召回问题
提问于 2020-08-22 12:01:58
我有一个LSTM编码器-解码器模型,我已经开发,以分类的价格波动基于跳跃-扩散模型(二进制分类问题本质上)。
我的模型是75/25之间的培训和验证。
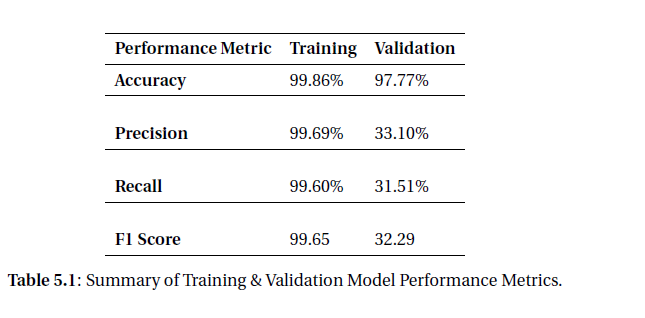
我的问题是,在应用了类不平衡技术(如SMOTE )之后,我的模型在培训和验证两方面的预测精度都很高(可能仍然过于合适)。但是,在精确性方面,召回和f1评分--我的训练模型再次表现良好--但在验证方面,我的查全率和召回率明显下降。这显然会导致验证侧的f1得分较低。
有谁知道为什么验证的准确性会很高,但查准率和召回率都显著下降了吗?这是与我的模型在验证方面的计算精度和召回方式有关的问题,还是我的模型过于适合导致验证结果降低?
下面的图片是模型结果的总结,如果需要的话,我也可以提供笔记本。
编辑:包括相关守则
#%pip install keras-metrics
# Importing required packages
import keras_metrics as km
# LSTM Workings_Autoencoder Model
ac_model_1b = Sequential()
ac_model_1b.add(Bidirectional(LSTM(units=200, return_sequences = True,
input_shape = (n_timesteps, n_features),
kernel_initializer='glorot_normal')))
ac_model_1b.add(LSTM(100))
ac_model_1b.add(Dropout(0.2))
ac_model_1b.add(RepeatVector(n_timesteps))
ac_model_1b.add(LSTM(100, return_sequences = True))
ac_model_1b.add(Dropout(0.2))
ac_model_1b.add(LSTM(200, return_sequences = True))
ac_model_1b.add(TimeDistributed(Dense(1, activation='sigmoid')))
ac_model_1b.compile(loss='binary_crossentropy', optimizer='Adamax',
metrics=['accuracy', km.binary_precision(), km.binary_recall()])
results_ac_model_1b = ac_model_1b.fit(x_train, y_train, epochs=100, batch_size=32,
shuffle=True, validation_data=(x_valid, y_valid))
print(ac_model_1b.summary())
ac_model_1b.save('lstm_model_adamax.h5')
欢迎任何建议。
谢谢。
回答 1
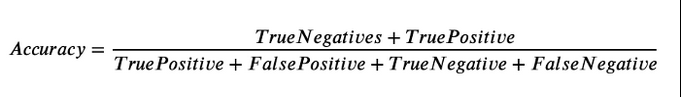
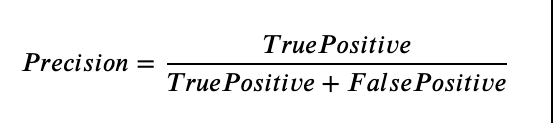
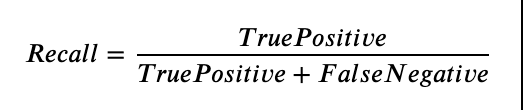
页面原文内容由Stack Overflow提供。腾讯云小微IT领域专用引擎提供翻译支持
原文链接:
https://stackoverflow.com/questions/63535969
复制相关文章
相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号