
如何提高TensorFlow中分类、非二进制、外语情感分析模型的准确性?
TLDR
我的目标是将一种外语(匈牙利语)中的句子分为三类:消极的、中立的和积极的。我想提高使用的模型的准确性,这可以在下面的“定义、编译、适合模型”一节中找到。这篇文章的其余部分是为了完整和可重现性而出现的。
我刚开始问机器学习方面的问题,这里也欢迎你的建议:https://meta.stackoverflow.com/questions/399477/how-to-ask-a-good-question-on-machine-learning
数据准备
为此,我有10000句话,给了5个人工注释器,分为否定、中性或肯定,可从这里获得。前几行如下所示:

如果注释者的分数之和为正,则将句子为正(用2表示);如果分数为0(用1表示),则为中性;如果和为负值,则为否定(用0表示):
import pandas as pd
sentences_df = pd.read_excel('/content/OpinHuBank_20130106.xls')
sentences_df['annotsum'] = sentences_df['Annot1'] +\
sentences_df['Annot2'] +\
sentences_df['Annot3'] +\
sentences_df['Annot4'] +\
sentences_df['Annot5']
def categorize(integer):
if 0 < integer: return 2
if 0 == integer: return 1
else: return 0
sentences_df['sentiment'] = sentences_df['annotsum'].apply(categorize)在本教程之后,我使用SubwordTextEncoder进行操作。我从这里下载web2.2-freq-sorted.top100k.nofreqs.txt,它包含目标语言中最常用的单词100000。(情绪数据和这个数据都是由这推荐的。)
阅读最常用的单词列表:
wordlist = pd.read_csv('/content/web2.2-freq-sorted.top100k.nofreqs.txt',sep='\n',header=None,encoding = 'ISO-8859-1')[0].dropna()编码数据,转换为张量
使用语料库方法初始化编码器:
import tensorflow_datasets as tfds
encoder = tfds.features.text.SubwordTextEncoder.build_from_corpus(
corpus_generator=(word for word in wordlist), target_vocab_size=2**16)在此基础上,对句子进行编码:
import numpy as np
import tensorflow as tf
def applyencoding(string):
return tf.convert_to_tensor(np.asarray(encoder.encode(string)))
sentences_df['encoded_sentences'] = sentences_df['Sentence'].apply(applyencoding)转换为张量每句话的感触:
def tensorise(input):
return tf.convert_to_tensor(input)
sentences_df['sentiment_as_tensor'] = sentences_df['sentiment'].apply(tensorise)定义要为测试保留多少数据:
test_fraction = 0.2
train_fraction = 1-test_fraction在pandas dataframe中,让我们创建编码语句列张量的numpy array:
nparrayof_encoded_sentence_train_tensors = \
np.asarray(sentences_df['encoded_sentences'][:int(train_fraction*len(sentences_df['encoded_sentences']))])这些张量有不同的长度,因此让我们使用填充使它们具有相同的长度:
padded_nparrayof_encoded_sentence_train_tensors = tf.keras.preprocessing.sequence.pad_sequences(
nparrayof_encoded_sentence_train_tensors, padding="post")让我们将这些张量放在一起:
stacked_padded_nparrayof_encoded_sentence_train_tensors = tf.stack(padded_nparrayof_encoded_sentence_train_tensors)将情绪张量叠加在一起:
stacked_nparray_sentiment_train_tensors = \
tf.stack(np.asarray(sentences_df['sentiment_as_tensor'][:int(train_fraction*len(sentences_df['encoded_sentences']))]))定义、编译、符合模型(要点)
定义并编译模型如下:
### THE QUESTION IS ABOUT THESE ROWS ###
model = tf.keras.Sequential([
tf.keras.layers.Embedding(encoder.vocab_size, 64),
tf.keras.layers.Conv1D(128, 5, activation='sigmoid'),
tf.keras.layers.GlobalAveragePooling1D(),
tf.keras.layers.Dense(6, activation='sigmoid'),
tf.keras.layers.Dense(3, activation='sigmoid')
])
model.compile(loss=tf.keras.losses.SparseCategoricalCrossentropy(from_logits = True), optimizer='adam', metrics=['accuracy'])适合:
NUM_EPOCHS = 40
history = model.fit(stacked_padded_nparrayof_encoded_sentence_train_tensors,
stacked_nparray_sentiment_train_tensors,
epochs=NUM_EPOCHS)输出的前几行是:

测试结果
就像在TensorFlow的RNN教程中一样,让我们绘制到目前为止所获得的结果:
import matplotlib.pyplot as plt
def plot_graphs(history):
plt.plot(history.history['accuracy'])
plt.plot(history.history['loss'])
plt.xlabel("Epochs")
plt.ylabel('accuracy / loss')
plt.legend(['accuracy','loss'])
plt.show()
plot_graphs(history)这给了我们:
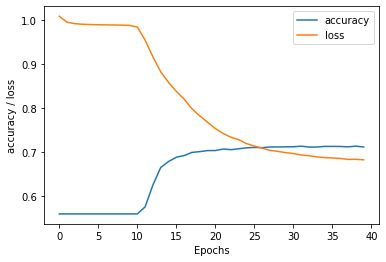
在准备培训数据时,准备测试数据:
nparrayof_encoded_sentence_test_tensors = \
np.asarray(sentences_df['encoded_sentences'][int(train_fraction*len(sentences_df['encoded_sentences'])):])
padded_nparrayof_encoded_sentence_test_tensors = tf.keras.preprocessing.sequence.pad_sequences(
nparrayof_encoded_sentence_test_tensors, padding="post")
stacked_padded_nparrayof_encoded_sentence_test_tensors = tf.stack(padded_nparrayof_encoded_sentence_test_tensors)
stacked_nparray_sentiment_test_tensors = \
tf.stack(np.asarray(sentences_df['sentiment_as_tensor'][int(train_fraction*len(sentences_df['encoded_sentences'])):]))仅使用测试数据评估模型:
test_loss, test_acc = model.evaluate(stacked_padded_nparrayof_encoded_sentence_test_tensors,stacked_nparray_sentiment_test_tensors)
print('Test Loss: {}'.format(test_loss))
print('Test Accuracy: {}'.format(test_acc))给出结果:

提供完整的笔记本,这里。
问题是
如何更改上述模型定义和编译行,使测试集在不超过1000个时代之后具有更高的精度?
回答 1
Stack Overflow用户
发布于 2020-07-16 21:41:15
- 你用的是字块子字,你可以试试BPE。此外,你也可以建立你的模型在伯特和使用转移学习,这将字面上飙升你的结果。
- 首先,更改Conv1D层中的内核大小,并为其尝试各种值。建议为3,5,7。然后,考虑添加层。此外,在第二层,即稠密,增加单位的数量,在其中,这可能会有所帮助。或者,您可以尝试一个只有LSTM层或LSTM层的网络,然后是Conv1D层。
- 通过尝试它是否有效,那么伟大的,否则重复。但是,训练损失给出了一个提示,如果你看到,损失并不顺利地下降,你可以假设,你的网络缺乏预测能力,即不适当,增加它中的神经元数量。
- 是的,更多的数据确实有帮助。但是,如果是在你的网络中的错误,即它是不合适的,那么,它不会有帮助。首先,在查找数据中的错误之前,您应该探索模型的局限性。
- 是的,使用最常见的词是通常的规范,因为在概率上,使用较少的单词不会发生更多,因此不会对预测产生很大的影响。
https://stackoverflow.com/questions/62943622
复制相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号