
忽略过采样中的列
我有六个特性列和一个目标列,这是不平衡的。我是否可以像ADASYN那样进行过采样,或者只为X1、X2、X3、X4四列创建合成记录,方法是复制与常量(月份、年份)完全相同的记录。
目前的一项:
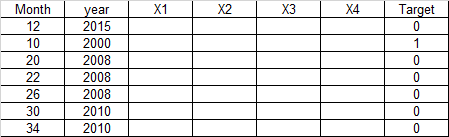
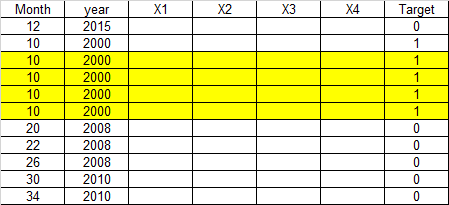
预期的记录:它可以通过对目标类“1”进行过采样来创建合成记录,但是记录的数量可以增加,但是添加的记录应该有月份和年份(不变,如下所示)。
回答 1
Stack Overflow用户
发布于 2020-06-23 15:36:48
从编程的角度来看,2017年在相关的Github回购中提出的一个相同问题被否定地回答了:
问题 我有一个数据框架,我想要应用smote,但我希望只使用列的子集。其他列包含每个示例的附加数据,我希望每个新示例也包含原始信息。 回答 除了在一个新的矩阵中提取列并对其进行平滑处理之外,没有办法做到这一点。即使您生成了一个新的示例,您也必须决定将什么作为值放在那里,所以我不知道如何添加这样的特性
从建模的角度来看,这是一个好主意,而不是,即使您能够找到一个编程解决方案,您也应该使用而不是来尝试--这就是为什么上面的imbalanced-learn开发人员即使想到在平滑的实现中添加这样一个特性也不屑一顾的原因。
为什么会这样呢?嗯,合成过采样算法,比如SMOTE,本质上使用了k-nn方法的一些变体,以便在现有的样本之间创建人工样本。鉴于这种方法,不言而喻,为了使这些人工样本确实“介于”真实样本之间(在k-nn意义上),必须考虑到所有现有的(数字)特征。
如果通过使用某种编程炼金术,您最终只能根据您的特性子集来生成新的SMOTE样本,那么将未使用的特性重新放入将摧毁这些人工样本的接近和“介于”的概念,从而通过在您的培训集中插入一个巨大的偏差来损害整个企业。
简言之:
- 如果您认为您的
Month和year确实是有用的特性,只需将它们包含在SMOTE中即可;您可能会得到一些无意义的人工样本,但这不应该被认为是一个(大的)问题。 - 如果没有,那么也许你应该考虑把他们从你的训练中完全移除。
https://stackoverflow.com/questions/62536637
复制相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号