
如何在feature_log_prob_中计算naive_bayes MultinomialNB
如何在feature_log_prob_中计算naive_bayes MultinomialNB
提问于 2020-05-04 07:15:52
这是我的密码:
# Load libraries
import numpy as np
from sklearn.naive_bayes import MultinomialNB
from sklearn.feature_extraction.text import CountVectorizer
# Create text
text_data = np.array(['Tim is smart!',
'Joy is the best',
'Lisa is dumb',
'Fred is lazy',
'Lisa is lazy'])
# Create target vector
y = np.array([1,1,0,0,0])
# Create bag of words
count = CountVectorizer()
bag_of_words = count.fit_transform(text_data) #
# Create feature matrix
X = bag_of_words.toarray()
mnb = MultinomialNB(alpha = 1, fit_prior = True, class_prior = None)
mnb.fit(X,y)
print(count.get_feature_names())
# output:['best', 'dumb', 'fred', 'is', 'joy', 'lazy', 'lisa', 'smart', 'the', 'tim']
print(mnb.feature_log_prob_)
# output
[[-2.94443898 -2.2512918 -2.2512918 -1.55814462 -2.94443898 -1.84582669
-1.84582669 -2.94443898 -2.94443898 -2.94443898]
[-2.14006616 -2.83321334 -2.83321334 -1.73460106 -2.14006616 -2.83321334
-2.83321334 -2.14006616 -2.14006616 -2.14006616]]我的问题是:
让我们说句话:“最佳”:class 1 : -2.14006616的概率。
得到这个分数的计算公式是什么?
我用的是LOG (P(best|y=class=1)) -> Log(1/2) ->不能得到-2.14006616
回答 1
Stack Overflow用户
回答已采纳
发布于 2020-05-04 10:13:01
从文档中我们可以推断出feature_log_prob_对应于给定一类特征的经验对数概率。让我们以一个“最佳”的特性为例,这个特性对于1类的1概率是-2.14006616 (正如您所指出的),现在如果我们将它转换为实际的概率得分,那么它就是np.exp(1)**-2.14006616 = 0.11764。让我们再退一步,看看在类1中“最佳”的概率如何以及为什么是0.11764。根据多项式朴素贝叶斯的文档,我们看到这些概率是使用以下公式计算的:
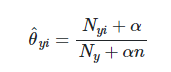
其中,分子大致对应于训练集中的类1 (在本例中我们感兴趣)中出现的特征“最佳”的次数,分母对应于类1的所有特性的总数。另外,我们还增加了一个小的平滑值,alpha来防止概率降到零,而n对应于特征总数,即词汇表的大小。为我们的例子计算这些数字,
N_yi = 1 # "best" appears only once in class `1`
N_y = 7 # There are total 7 features (count of all words) in class `1`
alpha = 1 # default value as per sklearn
n = 10 # size of vocabulary
Required_probability = (1+1)/(7+1*10) = 0.11764对于任何给定的特性和类,您都可以以类似的方式进行计算。
页面原文内容由Stack Overflow提供。腾讯云小微IT领域专用引擎提供翻译支持
原文链接:
https://stackoverflow.com/questions/61586946
复制相关文章
相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号