
LSTM模型中的平均压缩误差解释(双向或多平行)
我在玩时间序列和Keras 1)双向和2)多并行模型。根据"mean_squared_error“指标,我正在保存最好的模型。我的数据集是用MinMaxScaler标准化的(默认范围为0到1)。数据集测试部分的均方误差为0.02。这是否意味着我的模型的平均误差是14%,即0.02^0.5。这是对模型精度的一种很好的实用解释吗?
假设我想预测这个序列中的第四个值:
[10, 20, 30, 40, 50, 60, 70, 80, 90]所以我的x_test和y_test是这样的:
[10 20 30] 40
[20 30 40] 50
[30 40 50] 60
[40 50 60] 70
[50 60 70] 80
[60 70 80] 90守则如下:
cp = [ModelCheckpoint(filepath=path+"/epochBi.h5", monitor='mean_squared_error', verbose=1, save_best_only=True)]
model.compile(optimizer='adam', loss='mse', metrics= ['mean_squared_error'])
history_callback = model.fit(X_train, y_train, epochs=200, verbose=1, callbacks=cp)
model.load_weights(path+"/epochBi.h5")
score = model.evaluate(X_test, y_test, verbose=1)假设我对原始数据集进行了评估,我将如何解释MSE=0.02?
回答 2
Stack Overflow用户
发布于 2019-09-17 09:12:45
更新问题被更新了,因此有了一个新的评论
再说一遍,你的MSE 0.2并不意味着14%的任何东西,它只是一个标量,你不能把它当作你的地面真理的百分比。
是对模型精度的一个很好的实用解释吗?
我会以不同的方式问这个问题,what does it mean to me?
那么,看看你的目标值在40到90之间,你可以说,平均来说,你的错误是0.14。如果你需要更多的细节,这意味着当你预测40的时候,你猜到了39.86,当50 -> 50.14,60-> 59.86等等,但这是平均的。
希望你现在有了这个想法
让我们看一看均方误差(MSE)公式:
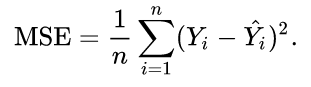
因此,这只是预测数据点和实际数据点之间平方差的平均值。在您的示例中,MSE (RMSE)的sqaure根为0.02^0.5或0.14左右(四舍五入)。
是否意味着我的模型的平均误差为14%?
不,当你损失0.14时,你不能说你的错误是14%。0.14只是误差的值,你的每一个错误可能是负的或正的,使他们的和为零,而不是他们的平方和。
能很好地解释模型的精度吗?
取决于你的目标。您通常测量的准确性取决于其他一些指标,如MAE,R sqaured和其他。假设你没有将你的数据恢复到最初的大小,那么就没有办法知道这在绝对条件下有多好或有多坏。因此,我建议您在重新标度的数据上测量MSE,然后决定,如果还没有这样做的话。
Stack Overflow用户
发布于 2019-09-17 06:49:08
您正在使用MSE来度量模型答案与实际答案之间的距离。也许你的模型从来没有准确地猜测过你的目标,但它的猜测足够接近目标。所以,你不能在这里计算百分比或准确度。有关更多信息,您可以阅读回归模型和分类模型之间的差异。
https://stackoverflow.com/questions/57968421
复制相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号