
熊猫枢轴回归分析
我有一个与以下类似的数据集:
import numpy as np
import statsmodels.api as sm
import statsmodels.formula.api as smf
dat = sm.datasets.get_rdataset("Guerry", "HistData").data
results = []
def fit_model_and_get_results(formula, data):
model = smf.ols(formula, data=data).fit()
#print(model.summary())
this_run = {}
this_run['model'] = formula
model_df = model.summary2().tables[1]
quality_tables = model.summary2().tables[0]
quality_tables.columns = [quality_tables.columns % 2, quality_tables.columns // 2]
quality_tables = quality_tables.stack().reset_index(drop=True)
quality_tables.columns = ['metric_kind', 'metric_value']
quality_tables = quality_tables[quality_tables.metric_kind != '']
for index, row in quality_tables.iterrows():
this_run[row.metric_kind] = row.metric_value
for k, v in this_run.items():
model_df[k] = v
return model_df
current_result = fit_model_and_get_results('Lottery ~ Literacy', dat)
current_result['variant'] = 'single_variable'
results.append(current_result)
current_result = fit_model_and_get_results('Lottery ~ Crime_pers', dat)
current_result['variant'] = 'single_variable'
results.append(current_result)
current_result = fit_model_and_get_results('Lottery ~ Crime_prop', dat)
current_result['variant'] = 'single_variable'
results.append(current_result)
# ***********************************************************************************
# adjustment for literacy
current_result = fit_model_and_get_results('Lottery ~ Literacy + Crime_pers', dat)
current_result['variant'] = 'two_variables'
results.append(current_result)
current_result = fit_model_and_get_results('Lottery ~ Literacy + Crime_prop', dat)
current_result['variant'] = 'two_variables'
results.append(current_result)
results = pd.concat(results)
#results = results.reset_index()
display(results)看上去像是:
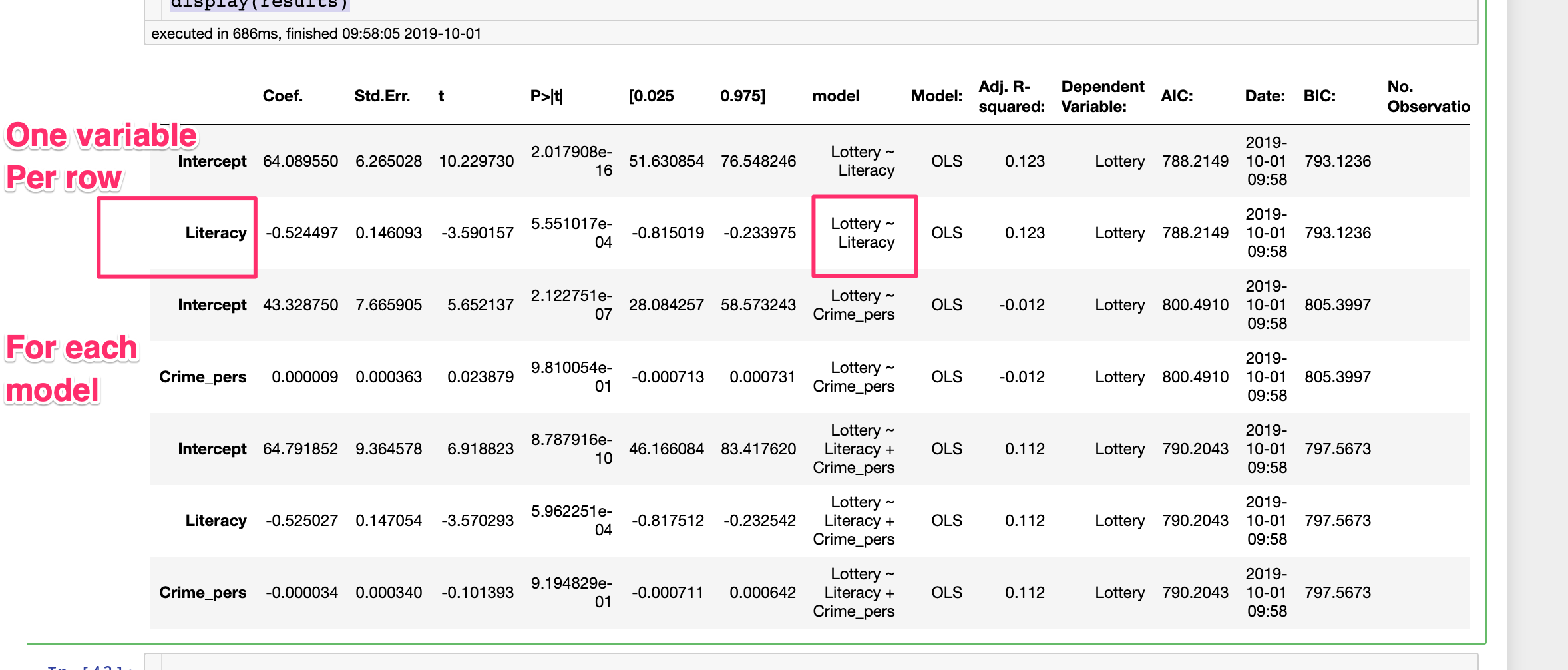
即模型中的一个变量构成和观察,数据框架包含多个模型。
但是,为了能够更好地比较结果,我希望获得一个类似于:

其中每个变量只存在一次(作为一个单一的观察),但是多个模型构成列。
看上去需要一个枢轴。然而,到目前为止,我还没有找到正确的方法来执行它。
预期的结果应包括:
- 变量作为第一列,每个变量
- 有一行,然后每个模型作为一个单独的列,在该列中只保留回归系数t值和p值
。
编辑
多个回归应该很容易比较。即,一旦所有1个组合,然后一些特征被调整为(性别,性别),然后所有剩下的单一组合加上这些特征的调整被计算,然后一个单一的第3模型,其中所有的特征被用于预测。
在这种情况下,首先将所有1种组合(识字、Crime_pers)计算为单独的(单一)模型。然后,对扫盲进行调整,并计算出剩余的(只有Crime_pers)。上面提到的第三模型被省略了,以使示例保持最小.
应要求为头两个案例提供一个输出样本数据框架:
d = pd.DataFrame({'feature':['Crime_pers', 'Literacy'], 'single_variable': [[4,4,6],[2,6,3]], 'two_variables' : [
#coef, t, p
np.nan,
[2,3,4]]})
display(d)
print(d)
feature single_variable two_variables
0 Crime_pers [4, 4, 6] NaN
1 Literacy [2, 6, 3] [2, 3, 4]其中每个字段中的子列是(系数、t值、p值(它们目前不包含只是为简洁而组成的值的实际值))。对于记录0和two_variables,输出是NaN,因为只有没有显式调整的模型的值是相关的。
基本上,上面的输出显示了所有3种模型的结果,这些模型都是以非常压缩的格式安装的。
编辑2
我更新了最小的例子,因为它太简约了。不幸的是,我被困在:
ValueError: Index contains duplicate entries, cannot reshape在应用建议的枢轴步骤时
回答 1
Stack Overflow用户
发布于 2019-10-01 16:00:49
恐怕我没有为最终结果表选择什么的逻辑,但这可能有助于您根据需要对其进行调整:
res = pd.DataFrame(results.loc[results.index!='Intercept','variant'])
res['val'] = results.loc[results.index!='Intercept',['Coef.', 'P>|t|', 't']].apply(lambda x: list(map('{:.3f}'.format, list(x))), axis=1)
res = res[(res.index=='Literacy') | (res.variant=='single_variable')].pivot(columns='variant')结果:
val
variant single_variable two_variables
Crime_pers [0.000, 0.981, 0.024] NaN
Literacy [-0.524, 0.001, -3.590] [-0.525, 0.001, -3.570]https://stackoverflow.com/questions/58180567
复制相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号