
无CNN重复模式的图像语义分割
假设我有一个或多个瓷砖组成一个单一的模式(例如,材料:木材,混凝土,砾石……)我想训练我的分类器,然后我将使用经过训练的分类器来确定另一个图像中的每个像素属于哪一类。
下面是两个瓷砖的例子,我想对分类器进行培训:


假设我想分割下面的图像来识别门的像素和墙壁的像素。这只是一个例子,我知道这个图像不是由与上面的瓷砖完全相同的图案组成的:

对于这个具体的问题,是否需要使用卷积神经网络?或者是否有一种方法来达到我的目标,一个浅层神经网络或任何其他分类器,结合纹理特征,例如?
我已经用Scikit-learn实现了一个分类器,该分类器分别工作在平铺像素上(参见下面的代码,其中training_data是单个对象的向量),但是我想用纹理模式来训练分类器。
# train classifier
classifier = SGDClassifier()
classifier.fit(training_data, training_target)
# classify given image
test_data = image_gray.flatten().reshape((-1, 1))
predictions = classifier.predict(test_data)
image_classified = predictions.reshape(image_gray.shape)我读了本评论关于最近用于图像分割的深度学习方法的文章,结果似乎是准确的,但由于我以前从未使用过任何CNN,所以我感到被它吓倒了。
回答 2
Stack Overflow用户
发布于 2019-11-02 15:08:07
您可以使用U-Net或SegNet进行图像分割。实际上,为了得到这样的结果,您在CNN中添加了剩余层:

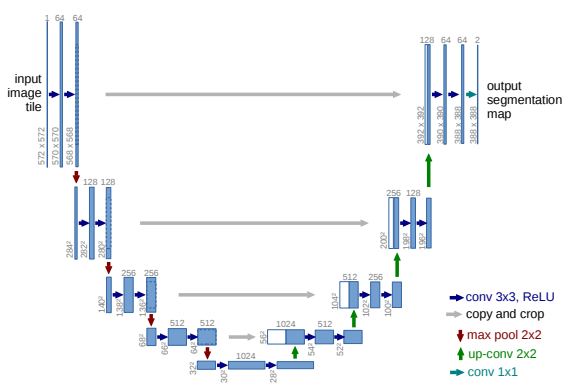
关于U-Net
Arxiv:U-Net:生物医学图像分割的卷积网络
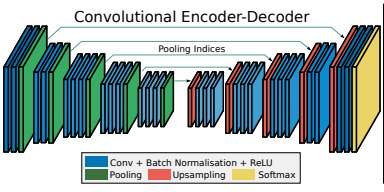
Seg-Net
Arxiv:SegNet:一种用于图像分割的深卷积编解码结构
这里是简单的代码示例: keras==1.1.0
U-Net:
shape=60
batch_size = 30
nb_classes = 10
img_rows, img_cols = shape, shape
nb_filters = 32
pool_size = (2, 2)
kernel_size = (3, 3)
input_shape=(shape,shape,1)
reg=0.001
learning_rate = 0.013
decay_rate = 5e-5
momentum = 0.9
sgd = SGD(lr=learning_rate,momentum=momentum, decay=decay_rate, nesterov=True)
shape2
recog0 = Sequential()
recog0.add(Convolution2D(20, 3,3,
border_mode='valid',
input_shape=input_shape))
recog0.add(BatchNormalization(mode=2))
recog=recog0
recog.add(Activation('relu'))
recog.add(MaxPooling2D(pool_size=(2,2)))
recog.add(UpSampling2D(size=(2, 2)))
recog.add(Convolution2D(20, 3, 3,init='glorot_uniform'))
recog.add(BatchNormalization(mode=2))
recog.add(Activation('relu'))
for i in range(0,2):
print(i,recog0.layers[i].name)
recog_res=recog0
part=1
recog0.layers[part].name
get_0_layer_output = K.function([recog0.layers[0].input, K.learning_phase()],[recog0.layers[part].output])
get_0_layer_output([x_train, 0])[0][0]
pred=[np.argmax(get_0_layer_output([x_train, 0])[0][i]) for i in range(0,len(x_train))]
loss=x_train-pred
loss=loss.astype('float32')
recog_res.add(Lambda(lambda x: x,input_shape=(56,56,20),output_shape=(56,56,20)))
recog2=Sequential()
recog2.add(Merge([recog,recog_res],mode='ave'))
recog2.add(Activation('relu'))
recog2.add(Convolution2D(20, 3, 3,init='glorot_uniform'))
recog2.add(BatchNormalization(mode=2))
recog2.add(Activation('relu'))
recog2.add(Convolution2D(1, 1, 1,init='glorot_uniform'))
recog2.add(Reshape((shape2,shape2,1)))
recog2.add(Activation('relu'))
recog2.compile(loss='mean_squared_error', optimizer=sgd,metrics = ['mae'])
recog2.summary()
x_train3=x_train2.reshape((1,shape2,shape2,1))
recog2.fit(x_train,x_train3,
nb_epoch=25,
batch_size=30,verbose=1)SegNet:
shape=60
batch_size = 30
nb_classes = 10
img_rows, img_cols = shape, shape
nb_filters = 32
pool_size = (2, 2)
kernel_size = (3, 3)
input_shape=(shape,shape,1)
reg=0.001
learning_rate = 0.012
decay_rate = 5e-5
momentum = 0.9
sgd = SGD(lr=learning_rate,momentum=momentum, decay=decay_rate, nesterov=True)
recog0 = Sequential()
recog0.add(Convolution2D(20, 4,4,
border_mode='valid',
input_shape=input_shape))
recog0.add(BatchNormalization(mode=2))
recog0.add(MaxPooling2D(pool_size=(2,2)))
recog=recog0
recog.add(Activation('relu'))
recog.add(MaxPooling2D(pool_size=(2,2)))
recog.add(UpSampling2D(size=(2, 2)))
recog.add(Convolution2D(20, 1, 1,init='glorot_uniform'))
recog.add(BatchNormalization(mode=2))
recog.add(Activation('relu'))
for i in range(0,8):
print(i,recog0.layers[i].name)
recog_res=recog0
part=8
recog0.layers[part].name
get_0_layer_output = K.function([recog0.layers[0].input, K.learning_phase()],[recog0.layers[part].output])
get_0_layer_output([x_train, 0])[0][0]
pred=[np.argmax(get_0_layer_output([x_train, 0])[0][i]) for i in range(0,len(x_train))]
loss=x_train-pred
loss=loss.astype('float32')
recog_res.add(Lambda(lambda x: x-np.mean(loss),input_shape=(28,28,20),output_shape=(28,28,20)))
recog2=Sequential()
recog2.add(Merge([recog,recog_res],mode='sum'))
recog2.add(UpSampling2D(size=(2, 2)))
recog2.add(Convolution2D(1, 3, 3,init='glorot_uniform'))
recog2.add(BatchNormalization(mode=2))
recog2.add(Reshape((shape2*shape2,)))
recog2.add(Reshape((shape2,shape2,1)))
recog2.add(Activation('relu'))
recog2.compile(loss='mean_squared_error', optimizer=sgd,metrics = ['mae'])
recog2.summary()
x_train3=x_train2.reshape((1,shape2,shape2,1))
recog2.fit(x_train,x_train3,
nb_epoch=400,
batch_size=30,verbose=1)然后为分割的颜色添加一个阈值。
Stack Overflow用户
发布于 2019-11-03 20:09:16
卷积神经网络是一种用于图像识别(包括语义分割)的高性能工具,并已被证明为对纹理非常敏感。然而,在当前对深度学习的兴趣浪潮之前,计算机视觉领域就已经存在了,而且还有各种其他工具仍然具有相关性--通常对计算资源和/或培训数据的要求较小。
对于这个具体的问题,是否需要使用卷积神经网络?
这在很大程度上取决于你对成功的衡量标准。还有其他不涉及使用氯化萘的工具--它们是否能给你一个令人满意的检测精度,只能通过实际测试来确定。
或者是否有一种方法来达到我的目标,一个浅层神经网络或任何其他分类器,结合纹理特征,例如?
浅层神经网络具有一定的检测能力,但与CNN不同的是,它们不存在平移不变性,因此对目标的小位移很敏感。如果用于对图像中的小块进行分类,这样的网络可能会取得更大的成功;当然,在滑动窗口内对图像补丁进行分类与CNN的工作方式并没有什么不同。用等效多层感知器(MLP)逼近CNN也是可能的--如果你对“肤浅”的定义允许的话,这将是另一种方法。
两种不需要神经网络的方法:
方向梯度直方图利用水平和垂直轴梯度直方图提取图像特征。这产生了一个可以分类的特征向量,例如使用支持向量机(SVM)或浅层神经网络(MLP)。这将是在不使用CNN的情况下对图像块进行分类的可行方法。scikit-image包有一个HOG函数,并且有一个完整的HOG特性分类示例这里。从文件中:
from skimage.feature import hog
from skimage import data, exposure
image = data.astronaut()
fd, hog_image = hog(image, orientations=8, pixels_per_cell=(16, 16),
cells_per_block=(1, 1), visualize=True, multichannel=True)Felsenszwalb高效的基于图的图像分割在scikit-image.segmentation工具箱中有很多分割算法。Felsenszwalb是其中之一,它(广义地说)是基于边缘的图像区域聚类。这里有更多的信息。来自模块文档:
from skimage.segmentation import felzenszwalb
from skimage.data import coffee
img = coffee()
segments = felzenszwalb(img, scale=3.0, sigma=0.95, min_size=5)希望这能有所帮助。
https://stackoverflow.com/questions/58504305
复制相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号