
如何在R中从长到宽与指定的偏好数据
我希望这不是交叉张贴。我一直试图从堆栈溢出的可用链接中了解如何执行数据从长到宽的更改。我想我已经快到了,但仍然有很多缺失。
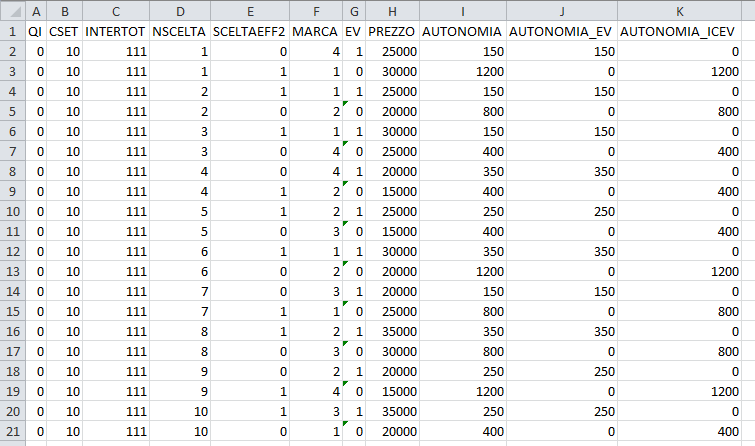
我已经说明了在电动汽车和汽油车之间的选择的预围栏数据。有些变量一般与汽车有关,如PREZZO,而另一些变量则与电动汽车有关,如AUTONOMIA_EV和内燃机汽车,如AUTONOMIA ICEV。
在INTERTOT栏中,每个答复者都有一个编号。第一个答辩人的号码是111号。有20行对应于这个人,因为他面临10种选择的两辆车,一辆电动和一辆汽油。在列SCELTAEFF2中,等于1的值表示个人执行的选择。这样的值必须与EV栏中报告的值进行比较,其中值1表示这条线路中的选项是电动汽车。
因此,例如,如果您查看第4行,它涉及到第一个个体面临的第二个选择,列SCELTAEFF2的值为1,并且列EV上的相应行也是1。这意味着被申请人在第二种备选方案中选择电动汽车。如果你看看第8行,第四种选择,个人选择一辆汽油车。这是因为列SCELTAEFF2的值为1,但是列EV上的对应行为零。
现在,我想为每个答复者,INTERTOT,只有一行,包含所有的信息,现在分散在20行。
我所拥有的文件非常大,这就是为什么我只给你展示一个部分。
我想估计一个混合选择模型,并执行计算意愿支付通过三角洲方法,但第一个问题是相关的数据,以正确的格式。
我正在尝试的代码如下:
prova_reshape.wide = reshape(data = "prova_reshape", idvar = "INTERTOT", direction = "wide" ) 但是,当然,我收到以下错误消息:
数据中的错误,timevar:
因为我没有指定timevar。我没有,因为我不知道该放什么进去。此外,我不确定指定idvar = "INTERTOT"是否足够。
我想我可以接近,但我不知道如何进行。
如果有人能帮我,我会很有帮助的。
马可
这里摘录了我的数据集:
structure(list(QI = c(0L, 0L, 0L, 0L, 0L, 0L, 0L, 0L, 0L, 0L,
0L, 0L, 0L, 0L, 0L, 0L, 0L, 0L, 0L, 0L), CSET = c(10L, 10L, 10L,
10L, 10L, 10L, 10L, 10L, 10L, 10L, 10L, 10L, 10L, 10L, 10L, 10L,
10L, 10L, 10L, 10L), INTERTOT = c(111L, 111L, 111L, 111L, 111L,
111L, 111L, 111L, 111L, 111L, 111L, 111L, 111L, 111L, 111L, 111L,
111L, 111L, 111L, 111L), NSCELTA = c(1L, 1L, 2L, 2L, 3L, 3L,
4L, 4L, 5L, 5L, 6L, 6L, 7L, 7L, 8L, 8L, 9L, 9L, 10L, 10L), SCELTAEFF2 = c(0L,
1L, 1L, 0L, 1L, 0L, 0L, 1L, 1L, 0L, 1L, 0L, 0L, 1L, 1L, 0L, 0L,
1L, 1L, 0L), MARCA = c(4L, 1L, 1L, 2L, 1L, 4L, 4L, 2L, 2L, 3L,
1L, 2L, 3L, 1L, 2L, 3L, 2L, 4L, 3L, 1L), EV = c(1L, 0L, 1L, 0L,
1L, 0L, 1L, 0L, 1L, 0L, 1L, 0L, 1L, 0L, 1L, 0L, 1L, 0L, 1L, 0L
), PREZZO = c(25000L, 30000L, 25000L, 20000L, 30000L, 25000L,
20000L, 15000L, 25000L, 15000L, 30000L, 20000L, 20000L, 25000L,
35000L, 30000L, 20000L, 15000L, 35000L, 20000L), AUTONOMIA = c(150L,
1200L, 150L, 800L, 150L, 400L, 350L, 400L, 250L, 400L, 350L,
1200L, 150L, 800L, 350L, 800L, 250L, 1200L, 250L, 400L), AUTONOMIA_EV = c(150L,
0L, 150L, 0L, 150L, 0L, 350L, 0L, 250L, 0L, 350L, 0L, 150L, 0L,
350L, 0L, 250L, 0L, 250L, 0L), AUTONOMIA_ICEV = c(0L, 1200L,
0L, 800L, 0L, 400L, 0L, 400L, 0L, 400L, 0L, 1200L, 0L, 800L,
0L, 800L, 0L, 1200L, 0L, 400L)), row.names = c(NA, 20L), class = "data.frame")回答 1
Stack Overflow用户
发布于 2019-12-18 15:40:56
我看不出你发布的数据是怎样的,但是,如果我已经很好地理解了你所需要的,所有这些都是在基R中,以防万一,它可以被修改:
# add the timevar you need for reshape:
dats$timev <- with(dats, ave(rep(1, nrow(dats)), CHOICE_SET, FUN = seq_along))
# now you can reshape it:
dats_w <- reshape(dats, idvar = " CHOICE_SET", timevar = "timev", direction = "wide")
# choose the column you need
dats_w <- dats_w[,c(2,1,3,4,10,6,12,7,13)]
# last add the correct column names
colnames(dats_w) <- c('INTERVIEW','CHOICE_SET','CHOICE','BRAND_EV','BRAND_ICEV','PRICE_EV','PRICE_ICEV','RANGE_EV',' RANGE_ICEV')
dats_w
INTERVIEW CHOICE_SET CHOICE BRAND_EV BRAND_ICEV PRICE_EV PRICE_ICEV RANGE_EV RANGE_ICEV
1 111 1 0 4 1 25000 30000 150 1200
3 111 2 1 1 2 25000 20000 150 800
5 111 3 1 1 4 30000 25000 150 400
7 111 4 0 4 2 20000 15000 350 400
9 111 5 1 2 3 25000 15000 250 400
11 111 6 1 1 2 30000 20000 350 1200
13 111 7 0 3 1 20000 25000 150 800
15 111 8 1 2 3 35000 30000 350 800
17 111 9 0 2 4 20000 15000 250 1200
19 111 10 1 3 1 35000 20000 250 400有数据:
dats <- structure(list(INTERVIEW = c(111L, 111L, 111L, 111L, 111L, 111L,
111L, 111L, 111L, 111L, 111L, 111L, 111L, 111L, 111L, 111L, 111L,
111L, 111L, 111L), CHOICE_SET = c(1L, 1L, 2L, 2L, 3L, 3L, 4L,
4L, 5L, 5L, 6L, 6L, 7L, 7L, 8L, 8L, 9L, 9L, 10L, 10L), CHOICE = c(0L,
1L, 1L, 0L, 1L, 0L, 0L, 1L, 1L, 0L, 1L, 0L, 0L, 1L, 1L, 0L, 0L,
1L, 1L, 0L), BRAND = c(4L, 1L, 1L, 2L, 1L, 4L, 4L, 2L, 2L, 3L,
1L, 2L, 3L, 1L, 2L, 3L, 2L, 4L, 3L, 1L), EV_DUMMY = c(1L, 0L,
1L, 0L, 1L, 0L, 1L, 0L, 1L, 0L, 1L, 0L, 1L, 0L, 1L, 0L, 1L, 0L,
1L, 0L), PRICE = c(25000L, 30000L, 25000L, 20000L, 30000L, 25000L,
20000L, 15000L, 25000L, 15000L, 30000L, 20000L, 20000L, 25000L,
35000L, 30000L, 20000L, 15000L, 35000L, 20000L), RANGE = c(150L,
1200L, 150L, 800L, 150L, 400L, 350L, 400L, 250L, 400L, 350L,
1200L, 150L, 800L, 350L, 800L, 250L, 1200L, 250L, 400L), timev = c(1,
2, 1, 2, 1, 2, 1, 2, 1, 2, 1, 2, 1, 2, 1, 2, 1, 2, 1, 2)), row.names = c(NA,
20L), class = "data.frame")https://stackoverflow.com/questions/59391279
复制相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号