
理解生成对抗性网络
我在Keras中实现了论文边缘连接(https://github.com/knazeri/edge-connect)中提出的GAN模型,并在KITTI数据集上进行了一些培训。现在我正试图弄清楚我的模型里面发生了什么,因此我有几个问题。
1.初始训练(100个历元,500个批次/期,10个样本/批次)
首先,我训练了论文中提出的模型(包括风格、知觉、L1和对抗性损失)。
乍一看,该模型收敛到了很好的结果:


这是蒙面输入的生成器(左)的输出。
来自张拉板的大多数图形看起来也很好:(这些都是GAN-模型的值,包含生成器(GENERATOR_Loss)的总损失、基于生成的图像的不同损失(L1、perc、style)以及对抗性损失(DISCRIMINATOR_loss) )。
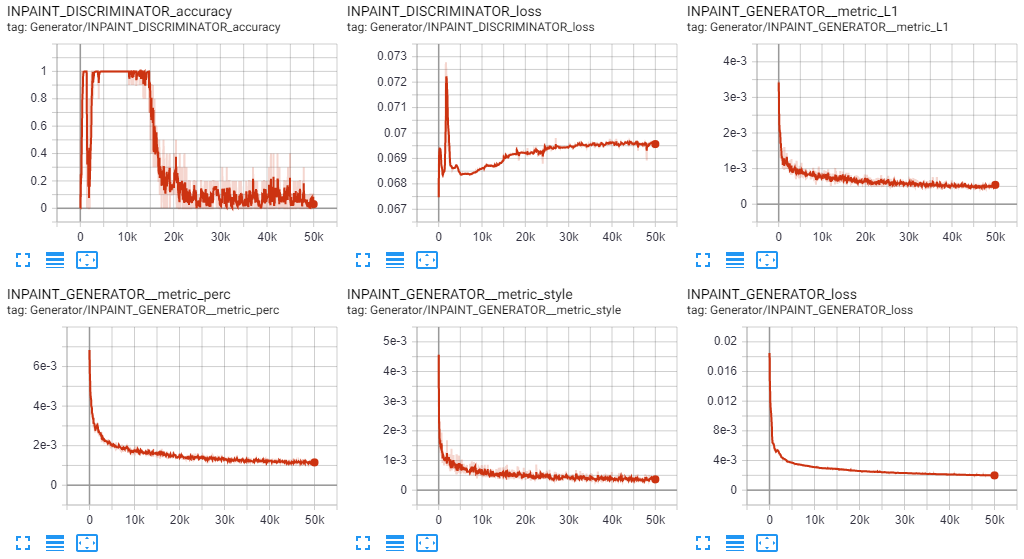
当仔细观察鉴别者时,情况就不同了。对于生成的图像,鉴别器的对抗性损失稳步增加。训练鉴别器时的损失(50/50假/真实示例)一点也不改变:

当查看鉴别器输出的激活直方图时,它总是输出0.5左右的值。
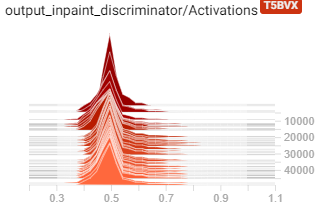
在我的问题/结论中,我希望得到你的反馈:
- So,我现在假设,我的模型从鉴别器那里学到了很多东西,对吗?这些结果都是基于除了对抗性loss?
- It以外的其他损失,这些结果表明鉴别器无法跟上产生更好图像的生成器。我认为鉴别器激活应该提前到大约0(假标签)和1(真实标签)的两个峰值,并保持there?
- I知道我的最终目标是,鉴别器输出的概率为真实的和假的.但是,当这种情况从一开始就发生,并且在training?
- Did期间没有改变,我会过早地停止训练,这意味着什么?识别器是否能赶上(因为发电机的输出不再有太大变化)并消除generator?
的最后一个小故障
2.因此,我开始了第二次训练,这次只使用发电机的对抗性损失!(~16期,500批/期,10个样本/批)
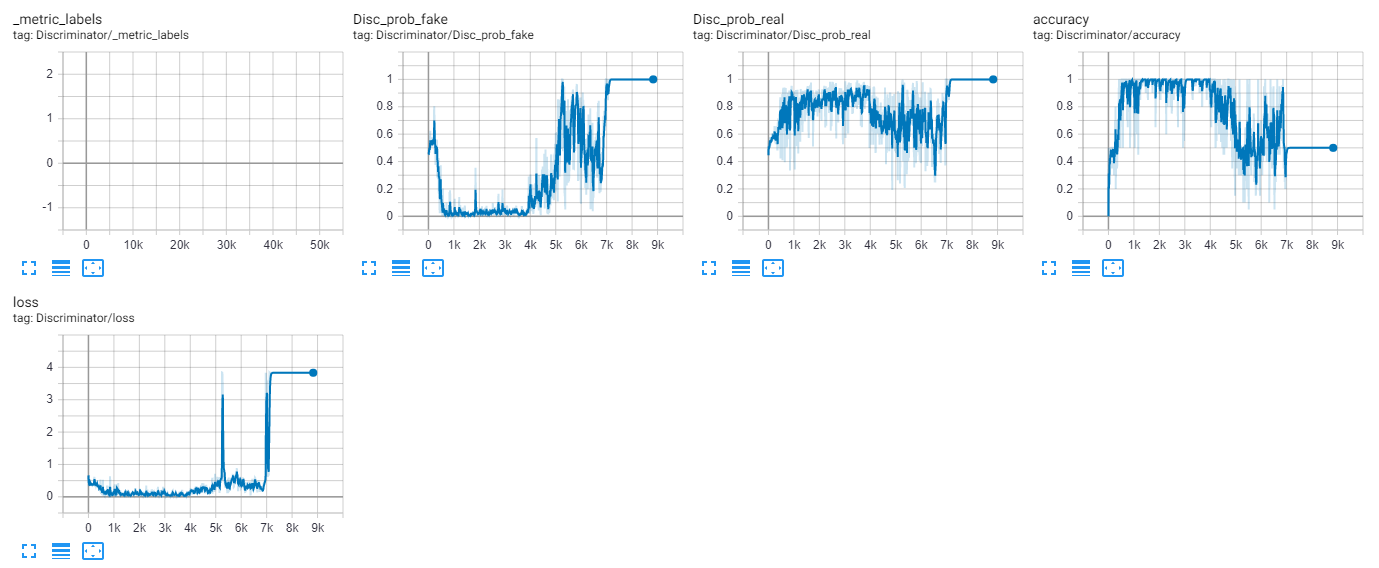
这一次,鉴别器似乎能够在一段时间后区分真假。(prob_real是分配给真实图像的平均概率,反之亦然)激活直方图看起来也不错:
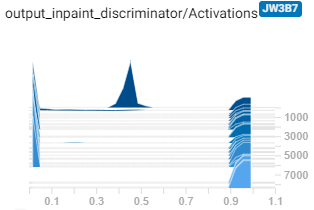
但不知怎的,在大约4k样本之后,事物开始发生变化,在7k左右,它就会发散……此外,生成器中的所有示例都如下所示:
关于我的问题/结论的第二部分:
- Should,我对鉴别器进行了预训练,这样它就有了先机?我想它需要能够区分真实和假(输出真实的大概率,反之亦然),这样生成器才能从中学到有用的东西?在第二次训练中,我是否应该在训练发电机的同时,对相同的reason?
- What进行一步的训练?甄别者的学习率是否太高? lr=1.0E-3)
- Many (:ADAM :ADAM)在互联网上提示GANs训练的目的是为了增加鉴别者工作的难度(标签噪声/标签翻转、实例噪声、标签平滑等)。在这里,我认为鉴别器更需要增强? (->,我也训练了磁盘,而不改变生成器,它很好地收敛)
回答 1
Stack Overflow用户
发布于 2020-06-10 01:00:06
如果判别器在网络开始时直接输出0.5概率,就意味着鉴别器的权重没有更新,在训练中没有作用,这进一步表明它无法区分来自生成器的真假图像。为了解决这一问题,尝试加入高斯噪声作为鉴别器的输入,或者进行标签平滑,这些都是非常简单有效的技术。在回答您的这个问题时,所有的结果都是基于对抗性损失以外的其他损失,可以使用的诀窍是首先对网络进行培训,了解除对抗性损失之外的所有损失,然后微调对抗性损失,希望它能有所帮助。对于问题的第二部分,生成的图像似乎面临着模式拼贴的问题,它们倾向于从1幅图像中学习颜色、退化,并将同样的图像传递给其他图像,试图通过缩小批处理大小或使用未滚动的gans来解决问题,
https://stackoverflow.com/questions/60042885
复制相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号