
Keras与Numpy的数值误差
为了真正理解卷积层,我在基本numpy中重新实现了单个角点Conv2D层的前向方法。两个seam的输出几乎相同,但有一些细微的差异。
得到角角的输出:
inp = K.constant(test_x)
true_output = model.layers[0].call(inp).numpy()我的产出:
def relu(x):
return np.maximum(0, x)
def forward(inp, filter_weights, filter_biases):
result = np.zeros((1, 64, 64, 32))
inp_with_padding = np.zeros((1, 66, 66, 1))
inp_with_padding[0, 1:65, 1:65, :] = inp
for filter_num in range(32):
single_filter_weights = filter_weights[:, :, 0, filter_num]
for i in range(64):
for j in range(64):
prod = single_filter_weights * inp_with_padding[0, i:i+3, j:j+3, 0]
filter_sum = np.sum(prod) + filter_biases[filter_num]
result[0, i, j, filter_num] = relu(filter_sum)
return result
my_output = forward(test_x, filter_weights, biases_weights)结果基本相同,但以下是一些不同之处的例子:
Mine: 2.6608338356018066
Keras: 2.660834312438965
Mine: 1.7892705202102661
Keras: 1.7892701625823975
Mine: 0.007190803997218609
Keras: 0.007190565578639507
Mine: 4.970898151397705
Keras: 4.970897197723389我尝试过将所有内容转换为float32,但这并不能解决这个问题。有什么想法吗?
编辑:我绘制了错误的分布图,它可能会给我们一些关于正在发生的事情的洞察。可以看出,这些误差都有非常相似的值,可分为四组。然而,这些错误并不完全是这四个值,而是几乎所有的唯一值围绕这四个峰值。
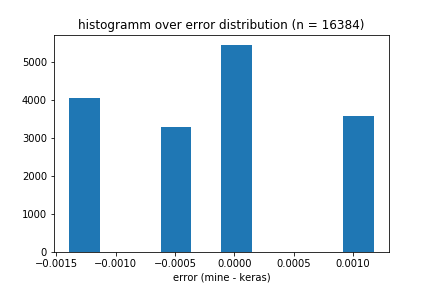
我非常感兴趣的是如何使我的实现与keras 1完全匹配。不幸的是,当实现多个层时,错误似乎呈指数增长。任何洞察力都能帮到我很多!
回答 3
Stack Overflow用户
发布于 2020-03-19 11:39:13
浮点运算是不可换的。下面是一个示例:
In [19]: 1.2 - 1.0 - 0.2
Out[19]: -5.551115123125783e-17
In [21]: 1.2 - 0.2 - 1.0
Out[21]: 0.0因此,如果你想要完全相同的结果,你不仅需要做同样的计算分析。但是,您还需要按照完全相同的顺序,使用相同的数据类型和舍入实现来执行这些操作。
来调试这个。从Keras代码开始,并将其逐行更改为代码,直到您看到差异为止。
Stack Overflow用户
发布于 2020-03-10 18:21:10
考虑到差异有多小,我想说它们是四舍五入的错误。
我建议使用np.isclose (或math.isclose)检查浮点数是否“相等”。
Stack Overflow用户
发布于 2020-03-13 16:01:40
第一件事是检查是否使用padding='same'。在您的实现中,您似乎使用了相同的填充。
如果您使用的是其他类型的填充,包括默认的padding='valid',则会有不同。
另一种可能性是,由于小和的三重循环,您可能正在积累错误。
你可以一次做一次,看它是否变了。例如,将此实现与您自己的实现进行比较:
def forward2(inp, filter_weights, filter_biases):
#inp: (batch, 64, 64, in)
#w: (3, 3, in, out)
#b: (out,)
padded_input = np.pad(inp, ((0,0), (1,1), (1,1), (0,0))) #(batch, 66, 66, in)
stacked_input = np.stack([
padded_input[:, :-2],
padded_input[:, 1:-1],
padded_input[:, 2: ]], axis=1) #(batch, 3, 64, 64, in)
stacked_input = np.stack([
stacked_input[:, :, :, :-2],
stacked_input[:, :, :, 1:-1],
stacked_input[:, :, :, 2: ]], axis=2) #(batch, 3, 3, 64, 64, in)
stacked_input = stacked_input.reshape((-1, 3, 3, 64, 64, 1, 1))
w = filter_weights.reshape(( 1, 3, 3, 1, 1, 1, 32))
b = filter_biases.reshape (( 1, 1, 1, 32))
result = stacked_input * w #(-1, 3, 3, 64, 64, 1, 32)
result = result.sum(axis=(1,2,-2)) #(-1, 64, 64, 32)
result += b
result = relu(result)
return result第三种可能是检查是否使用GPU,并将所有内容切换到CPU进行测试。GPU的一些算法甚至是不确定的.
对于任何内核大小:
def forward3(inp, filter_weights, filter_biases):
inShape = inp.shape #(batch, imgX, imgY, ins)
wShape = filter_weights.shape #(wx, wy, ins, out)
bShape = filter_biases.shape #(out,)
ins = inShape[-1]
out = wShape[-1]
wx = wShape[0]
wy = wShape[1]
imgX = inShape[1]
imgY = inShape[2]
assert imgX >= wx
assert imgY >= wy
assert inShape[-1] == wShape[-2]
assert bShape[-1] == wShape[-1]
#you may need to invert this padding, exchange L with R
loseX = wx - 1
padXL = loseX // 2
padXR = padXL + (1 if loseX % 2 > 0 else 0)
loseY = wy - 1
padYL = loseY // 2
padYR = padYL + (1 if loseY % 2 > 0 else 0)
padded_input = np.pad(inp, ((0,0), (padXL,padXR), (padYL,padYR), (0,0)))
#(batch, paddedX, paddedY, in)
stacked_input = np.stack([padded_input[:, i:imgX + i] for i in range(wx)],
axis=1) #(batch, wx, imgX, imgY, in)
stacked_input = np.stack([stacked_input[:,:,:,i:imgY + i] for i in range(wy)],
axis=2) #(batch, wx, wy, imgX, imgY, in)
stacked_input = stacked_input.reshape((-1, wx, wy, imgX, imgY, ins, 1))
w = filter_weights.reshape(( 1, wx, wy, 1, 1, ins, out))
b = filter_biases.reshape(( 1, 1, 1, out))
result = stacked_input * w
result = result.sum(axis=(1,2,-2))
result += b
result = relu(result)
return resulthttps://stackoverflow.com/questions/60619900
复制相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号